
机构名称:
¥ 1.0
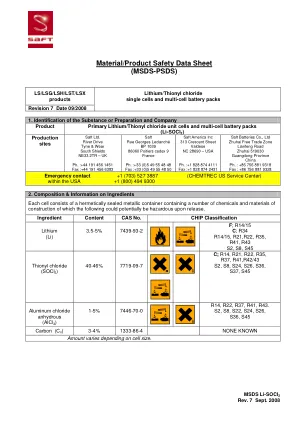
在正常业务过程中,公司花费大量精力阅读和解释文件,这是一个高度手动的过程,涉及繁琐的任务,例如识别日期和名称或确定合同中某些条款的存在与否。处理自然语言很复杂,而且由于这些文档有各种格式(扫描图像、数字格式)并且具有不同程度的内部结构(电子表格、发票、文本文档),这进一步复杂化了这一过程。我们提出了 DICR,这是一个端到端、模块化且可训练的系统,可自动执行文档审查的日常方面,并允许人类执行验证。该系统能够加快这项工作,同时提高提取信息的质量、一致性、吞吐量并减少决策时间。提取的数据可以输入到其他下游应用程序中(从仪表板到问答和报告生成)。
DICR:AI 辅助、自适应合同审查平台
主要关键词


相关文件推荐

















![招标修改/合同修改 [X]](/simg/5/5003432cfddb712e9f125902de20efcb0c5f959b.webp)







