点击购买,资源将自动在新窗口打开.
获取独家产品信息,尽享促销优惠!立即订阅,不容错过
* 限···时··优惠
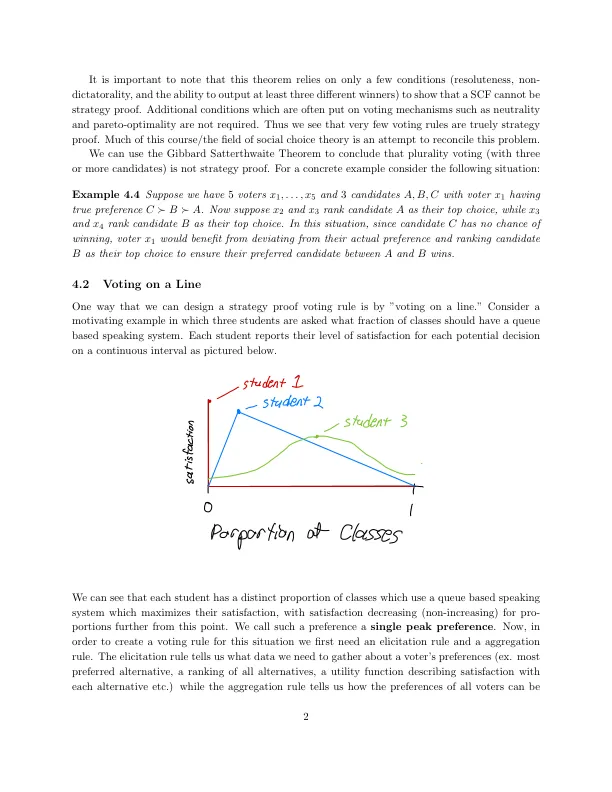
结合起来得到获胜者。在选民具有单峰偏好的情况下,我们可以设计一种防策略的投票机制。该机制要求每个选民报告他们最喜欢的点作为引出规则,然后聚合规则选择中位数作为获胜者。请注意,聚合规则使用中位数而不是平均值,因为使用平均值会导致策略行为(尚未处于中间位置的选民会受到激励走向极端以获得更接近他们真实偏好的结果)。这是布莱克定理给出的。事实证明,当使用 l 1 范数表示距离并且选民偏好在每个维度上都是单峰时,布莱克定理也可以推广到两个(或更多)维度。
主要关键词