机构名称:
¥ 1.0
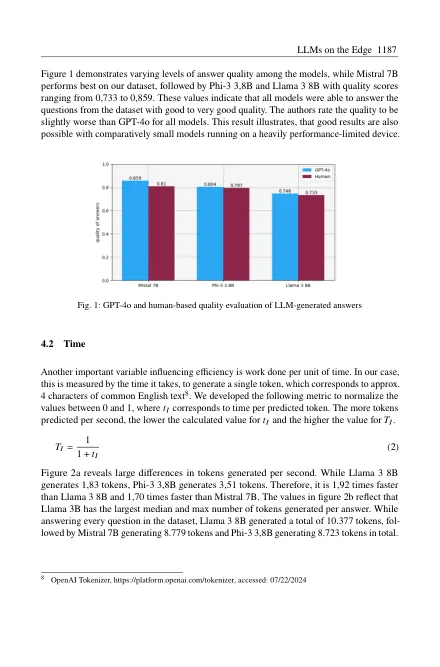
摘要:生成的人工智能已成为许多人生活中不可或缺的一部分。大型语言模型(LLM)在科学和社会中的普及越来越多。虽然众所周知,训练这些模型需要显着的能量,但推论也有助于其总能源需求。因此,我们通过研究推理的效率,尤其是在计算能力有限的本地硬件上,分析了如何尽可能可持续地使用它们。我们开发了用于量化LLM在边缘的效率的指标,重点是最有影响力的因素质量,时间和能量。我们比较了边缘上三种不同的最生成模型状态的性能,并评估生成的文本的质量,用于文本创建的时间以及能量需求降低到令牌水平。这些模型在质量水平上达到73%,3%和85之间,每秒产生1、83至3、51令牌,而在没有GPU支持的情况下,在单板计算机上消耗0、93和93至1、76 <,76 <,⌘,每张令牌的能量。这项研究的发现表明,生成模型可以在边缘设备上产生令人满意的结果。但是,在将它们部署在生产环境中之前,建议进行彻底的效率评估。
llms在边缘:质量,延迟和能源效率
主要关键词




相关文件推荐