XiaoMi-AI文件搜索系统
World File Search System似然估计

中国社会的序列生成对抗网络...
尽管序列到序列模型在许多摘要数据集中都达到了最先进的性能,但是中国社交媒体文本的处理中仍然存在一些问题,例如短句子,缺乏连贯性和准确性。这些问题是由两个因素引起的:基于RNN的序列模型的原理是最大似然估计,这将导致产生长摘要时梯度消失或爆炸;中国社交媒体中的文字漫长而嘈杂,很难产生高质量的摘要。为了解决这些问题,我们应用了序列生成的对抗网络框架。该框架包括生成器和歧视器,其中生成器用于生成摘要,并使用歧视器来评估生成的摘要。软核层层用作连接层,以确保发电机和歧视器的共培训。实验是在大规模的中国社交媒体文本摘要数据集上进行的。句子的长度,胭脂评分和摘要质量的人工得分用于评估生成的摘要。结果表明,我们的模型生成的摘要中的句子更长且准确性更高。

接近...
摘要:量子振幅估计(QAE)算法是一种主要的量子算法,旨在实现二次加速。直到实现易于断层的量子计算为止,与经典的蒙特卡洛(MC)具有竞争力一直难以捉摸。已经开发出替代方法,以便在保持有利的理论规模的同时需要更少的资源。我们将标准QAE算法与两个嘈杂的中间尺度量子(NISQ)在数值集成任务上的友好版本与大都会的蒙特卡洛技术 - 黑斯廷斯作为经典基准。分别根据样品数量,计算时间和解决方案所需的量子电路的长度来评估算法。在11 Quibent的捕获量子计算机上测试了两个QAE替代方案的有效性,以验证哪种解决方案可以首先在积分估计问题中加快速度。我们得出的结论是,对于使用阶段估计常规而言,另一种方法是可取的。的确,最大似然估计保证了量子电路的长度与积分估计中的精度以及对噪声的更大阻力之间的最佳权衡。

神经网络量子态断层扫描
现代量子技术利用量子系统的独特特性来实现经典策略无法达到的性能。这一潜在优势取决于创建、操纵和测量量子态的能力。该领域的任何实验程序都需要对这些步骤进行可靠的认证:这正是量子态层析成像 (QST) 的领域 [1]。QST 的目标是通过对系统有限组相同副本进行测量来估计未知的量子态。如果状态由密度矩阵 ϱ 描述,位于 ad 维希尔伯特空间中,则需要 O(d/ε) 个副本才能获得 ϱ 的估计值,且误差(理解为总变分距离)小于 ε[2]。这清楚地说明了 QST 对大规模系统的资源需求。从广义上讲,QST 是一个逆问题 [3-5]。因此,线性反演 [6] 可能是该主题最直观的方法。然而,它也有一些缺点:它可能报告非物理状态,并且无法通过分析确定估计的均方误差界限。为了绕过这些缺点,可以使用各种有用的 QST 方法,例如贝叶斯断层扫描 [ 7 , 8 ]、压缩感知 [ 9 , 10 ] 或矩阵积状态 [ 11 , 12 ],尽管最大似然估计 (MLE) 仍然是最常用的方法 [ 13 , 14 ]。从现代的角度来看,QST 本质上是一个数据处理问题,试图从

气候变化会影响迁移吗?
在本文中,我们测试了从中国和印度的国际迁移到经济合作与发展组织的一些重要目的地。目的是看看除了经济因素外,气候移民是否对劳动迁移有重大影响。经验估计是通过运行泊松伪最大似然估计器来完成的,对平衡面板数据具有固定的影响。数据是在1995 - 2018年期间收集的。结果表明,如果目的地国家二氧化碳排放和自然灾害较低,则中国人更有可能迁移。这意味着人们因拉力因素而不是中国的推动因素而迁移。对于印度来说,对于两种气候变化的代表,均未获得原产地和目的地的重要性。本文的价值尤其来自选择这两个国家,根据世界人口评论(2020)和EM-DAT(2018),这是亚洲气候变化国家最受影响的。独创性来自包括气候变化的代理与经济因素以及添加虚拟变量,例如通用语言,在每种情况下都可以获得积极和重要的。基于我们的结果,我们能够对我们的研究提出一些实际含义。政府应实施更有效的计划,为从暴露于高水平二氧化碳排放的地区提供更好的生活条件,以防止其移民。在突然灾难的情况下,政府应涉及为重新安置提供支持。

课程和教学大纲
单位-II:假设估计理论的估计理论和测试:估计的无偏,一致性,效率和充分性,最大似然估计及其特性(没有证据)。假设的检验:简单而复合的假设,基因和类型的错误–II,关键区域,重要性水平,大小和测试的功率。单位-III:简单假设的显着性检验,卡方检验,拟合良好,应急表中属性的独立性以及许多比例的平等,t检验,f检验和基于它们的问题,在数据挖掘中的重要性测试的应用。单位IV:相关和回归相关性:简介,类型,Karl Pearson的相关系数,Spearman的等级相关系数,多重和部分相关。回归:线性回归,回归系数,多线性回归的概念和多线性回归的矩阵符号。单位V:非参数测试需要非参数测试,一个样本和两个样本的标志测试,Wilcoxon签名的等级测试,中间测试,Wald Wolfowitz Run测试,Mann Whitney U测试,随机性运行测试,基于Spearman的独立性测试,基于Spearman的独立等级相关系数(小样品和大型样品),kruskal iner for等等。在数据挖掘中非参数测试的应用。教科书

发展性认知神经科学
数学操作是我们为计算数字之间关系而采取的认知动作。算术操作,加法,减法,乘法和分裂是教育中的基础。增加是在学校教授的第一个,并且在功能磁共振成像(fMRI)研究中最受欢迎。分裂,通常是通过fMRI进行的最少教导的。fMRI荟萃分析显示,算术操作激活儿童和成人的顶叶,扣带和岛状皮质的大脑区域。至关重要的是,没有荟萃分析检查儿童和成人各自的算术操作的大脑相关性的一致性。我们使用来自fMRI文章的定量荟萃分析审查和检查,这些数据分别报告了脑坐标,以增加儿童和成人的添加,术语,繁殖和分裂。结果表明,算术操作引起了成人和儿童的额叶和cingulo-obercular网络的共同领域。在操作差异之间主要观察到成人。有趣的是,在激活似然估计中表达的较高的组内一致性在与儿童的大脑区域相关的大脑区域,而不是额叶 - 额叶网络相关,而成人和儿童之间也很常见。与建构主义的认知理论和未来研究的实际方向讨论了发现。

地中海欧洲极端野火的跨国风险量化
摘要,我们估计了被烧毁区域(BA)定义为地中海欧洲定义的极端野生鱼类的国家层面的风险,并进行了越野比较。为此,我们利用2006年至2019年的欧洲森林消防信息系统(EFFIS)地理空间数据进行了极端的价值分析。更具体地,我们使用最大似然估计来应用对极端野生野生产生的点表征。通过对协变量进行建模,我们还评估了潜在的趋势和与驱动或影响野生发生的常见因素的潜在趋势和相关性,例如火灾天气指数作为气象条件,人口密度,土地覆盖率,土地覆盖类型和海上性的代理。我们发现,极端野生动物的最高风险是葡萄牙(PT),其次是希腊(GR),西班牙(ES)和意大利(IT),其10年BA回报水平分别为50'338 HA,33'242 HA,25'165 HA,25'165 HA和8'966 HA,以及8'966 HA。将我们的结果与对大型野生野生动力的货币影响的现有估计相结合,这表明预计损失为162-4.39亿欧元(PT),81-219亿欧元(ES),41-29亿欧元,41-2.2亿欧元(GR),以及18-78万欧元,在此类10年的回报期间发生。
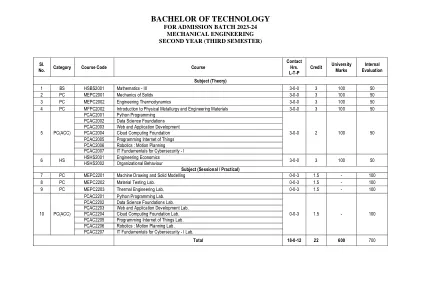
技术学士
模块5:应用统计(8小时)随机抽样,参数估计,最大似然估计,置信区间。回归和相关分析:直线的拟合(避免正方形的方法),与基本属性相关系数。教科书:1。E. Kreyszig的高级工程数学,John Willey&Sons Inc.第10版。2。Ronald E. Walpole,Raymond H. Myers,Sharon L. Myers&Keying Ye,“工程师与科学家的概率与统计数据”,第八版,2007年,新德里Pearson Education Inc.。 参考书:1。 J. Sinha Roy和S. Padhy,Kalyani出版商的普通和部分微分方程。 2。 B. V. Ramana的高级工程数学,McGraw Hill Education。 3。 PAL和S. Bhunia的工程数学,牛津出版物。 随机过程,Roy D. Yates,Rutgers和David J. Goodman,John Wiley and Sons,Inc。Ronald E. Walpole,Raymond H. Myers,Sharon L. Myers&Keying Ye,“工程师与科学家的概率与统计数据”,第八版,2007年,新德里Pearson Education Inc.。参考书:1。J. Sinha Roy和S. Padhy,Kalyani出版商的普通和部分微分方程。2。B. V. Ramana的高级工程数学,McGraw Hill Education。3。PAL和S. Bhunia的工程数学,牛津出版物。随机过程,Roy D. Yates,Rutgers和David J. Goodman,John Wiley and Sons,Inc。

跨领域 ALE 荟萃分析揭示的伙伴互动的神经相关性
目标:伙伴式互动是人类合作性质的重要体现。伙伴式互动可以采取多种形式,包括以问题为导向的对话等认知活动和一起搬动家具等体力任务。本研究的主要目标是使用定量荟萃分析技术探索伙伴式互动的神经基础,以寻找跨互动模式共同的领域通用大脑区域。方法:对 18 项功能性神经影像学研究进行了激活似然估计 (ALE) 荟萃分析,对比了有伙伴参与的任务表现和没有互动伙伴参与的任务表现。研究包括各种互动任务,涵盖了伙伴式互动的认知和体力形式。结果:荟萃分析结果显示,在右颞顶交界处 (rTPJ) 中存在一个显著的 ALE 簇,其中有两个子峰,该区域与心理化、社会预测和合作密切相关。结论:将 rTPJ 确定为伙伴式互动的主要跨模式区域,突出了隐性心理化在所有形式的伙伴式互动中的作用。两个不同子峰的发现可能表明两个区域之间的心理功能存在独特差异。

高度适应性拉索:在现实模型中提供有效的非参数推断的机器学习
使用现实世界数据了解治疗对健康相关结果的影响需要定义因果参数并施加相关识别假设,以将其转化为统计估计。半参数方法,例如目标最大似然估计器(TMLE),以构建这些参数的渐近线性估计器。要进一步建立这些估计量的渐近效率,必须满足两个条件:1)数据可能性的相关组成部分必须属于Donsker类,而2)2)滋扰参数的估计值在其真实值的速度上以比N -1 /4更快的速度收敛。高度适应性的拉索(HAL)通过在具有有界分段变化标准的Càdlàg函数中充当经验风险最小化来满足这些标准,已知是Donsker。hal达到了所需的收敛速度,从而保证了估计量的渐近效率。HAL最小化其风险的功能类别具有足够的灵活性,可以捕获现实的功能,同时保持建立效率的条件。此外,HAL可以对非方向可区分参数(例如条件平均治疗效果(CATE)和因果剂量响应曲线,对精确健康很重要。尽管在机器学习文献中经常考虑这些参数,但这些应用通常缺乏适当的统计推断。HAL通过提供可靠的统计不确定性量化来解决这一差距,这对于健康研究中的知情决策至关重要。