XiaoMi-AI文件搜索系统
World File Search System信息检索

噪声量子态的信息可恢复性
从量子系统中提取经典信息是许多量子算法的必要步骤。然而,由于系统容易受到量子噪声的影响,这些信息可能会被破坏,而且量子动力学下的失真尚未得到充分研究。在这项工作中,我们引入了一个系统框架来研究我们如何从嘈杂的量子态中检索信息。给定一个嘈杂的量子信道,我们完全表征了可恢复的经典信息的范围。这个条件允许一个自然的度量来量化信道的信息可恢复性。此外,我们解决了最小信息检索成本,它与相应的最优协议一起,可以通过半定规划有效地计算出来。作为应用,我们为实际量子噪声建立了信息检索成本的极限,并采用相应的协议来减轻基态能量估计中的错误。我们的工作首次全面表征了噪声量子态从可恢复范围到恢复成本的信息可恢复性,揭示了概率误差消除的最终极限。

什么是好的搜索引擎?
本文研究了一个道德问题:“什么是好的搜索引擎?”由于搜索引擎是全球在线信息的守门人,因此他们在道德上做得很好。虽然互联网已有数十年历史了,但从跨学科角度来看,该主题仍未探索。本文提出了一种基于角色的新型方法,涉及四种搜索引擎行为类型的道德模型:客户仆人,图书馆员,记者和老师。它参考了信息检索的研究领域探索这些道德模型,并通过涉及COVID-19的全球大流行的案例研究。它还从搜索引擎开发的历史上,从1990年代的较早的努力到最近的大型基于语言模型的对话信息寻求系统的最新前景来反映出四种道德模型,从而扮演了诸如Google之类的既定网络搜索引擎的作用。最后,本文概述了考虑到现在和未来的法规以及对搜索引擎继续发展的考虑的考虑。本文应兴趣信息检索研究人员和对搜索引擎伦理感兴趣的其他人。

自然语言处理与量子物理学
近年来,量子计算引起了广泛关注。其基本思想是利用量子力学的力量来解决计算问题(Shor,1999;Nielsen 和 Chuang,2002)。虽然某些量子算法可以成为经典算法的更快替代方案(Biamonte 等人,2017;Arute 等人,2019),但量子物理的数学框架也已用于认知(Busemeyer 和 Bruza,2012)、优化(Soleimanpour 等人,2014)和其他学科。在自然语言处理 (NLP) 领域,量子力学近年来的研究兴趣激增,解决了从词汇语义模糊性(Meyer and Lewis,2020 年)到语义组合(Coecke 等人,2020 年)以及从信息检索(Jiang 等人,2020 年)到文本分类(Zhang 等人,2021 年)等各种问题,其中量子物理的不同特性启发了新算法。尽管其研究文献不断增加,但尚未有调查对量子 NLP 领域进行综述和分类。最相关的调查是关于量子启发的信息检索(Uprety 等人,2020 年;
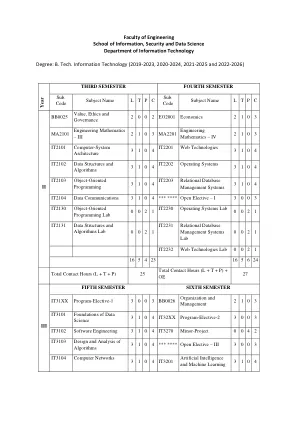
工程学院 信息、安全与数据科学学院
• IT4144 高级数据结构 • IT4145 分布式计算 • IT4146 软件测试技术 • IT4147 软件可靠性 • IT4148 面向对象设计和模式 • IT4149 无线自组织和传感器网络 • IT4150 云计算 • IT4151 软件定义网络 • IT4152 移动计算 • IT4153 自然语言处理 • IT4154 信息检索

人工智能创新的步伐:速度、人才和试验
1 自然语言处理 NLP 16,126 13.8 2 知识表示与推理 KR 6,319 5.4 3 规划与调度 PS 5,086 4.4 4 信息检索 IR 2,514 2.2 5 机器人 RO 1,540 1.3 6 智能代理 IA 2,571 2.2 7 计算机视觉 CV 27,228 23.3 8 深度学习 DL 37,925 32.5

人工智能作为法律研究助理
摘要 文本检索和语义分割的应用具有很大的潜力,可以改变法律研究行业的格局,使任何人都可以更轻松地获取和负担得起相关信息。在本工作论文中,我们介绍了一些新方法,作为人工智能法律援助 (2020) 的一部分,这是信息检索评估论坛-2020 的一个重要活动。在本文的第一部分,我们使用基于 BM 25、主题嵌入和 Law2Vec 嵌入的方法确定了所提供查询的相关先前案例和法规。对于第二部分,我们使用 BERT 将法律案件文件语义分割为七个预定义标签或“修辞角色”。在第一个任务中,我们在 P@10 和 BPREF 指标中的表现使我们位居前两名。另一方面,我们针对第二个任务的 BERT 实现获得了 .479 的宏精度,仅比表现最佳的方法低 .027。关键词 1 nlp、词嵌入、主题嵌入、bm25、先例检索、信息检索、法规检索、bert、修辞角色、分类、法律 1。介绍

文本分析和自动索引 - SIGIR
本书的前两章介绍了现有信息检索系统的设计和操作。在信息检索所需的所有操作中,最关键、也可能是最困难的操作是分配能够表示集合项内容的适当术语和标识符。这项任务称为索引,通常由受过培训的专家手动执行。在现代环境中,索引任务可以自动执行。本章涉及用于自动索引的技术以及这些技术的效果和性能。首先介绍基本的索引任务,然后比较手动和自动索引。然后研究选择好的内容术语和根据术语的假定值分配权重的基本技术,以便进行内容识别。然后提出了一种简单的自动索引程序,以及由使用术语短语和同义词库类别组成的改进。还简要介绍了语言和概率技术在自动索引中的使用。最后,包括评估输出以证明所提出的索引技术应用于小样本集合的有效性。

如何引用本文:Indraji C,Satishkumar Naikar,Dominic J(2024)使用机器人技术和人工智能来增强图书馆服务。
摘要图书馆的运作方式和为客户提供服务的方式正在通过机器人技术和人工智能(AI)的结合进行革命。这些尖端技术在编目,信息检索,用户支持和维护中的利用是本研究所研究的图书馆服务领域。机器人系统提供交互式和自定义的用户支持,增强了整体用户体验,但AI驱动的系统通过自动化元数据生产和分类来提高编目过程的效率。此外,通过AI算法使高级信息检索更容易,从而使用户更快,更准确地访问相关信息。此外,该研究探讨了机器人技术如何帮助诸如书籍检索和货架组织等标准维护职责,从而释放了人工劳动,从而获得更多复杂而有价值的工作。结果表明,AI和机器人技术在库中的应用提高了服务质量和运营效率,同时也提高了可访问性和用户友好性。还探索了这些技术广泛使用的可能障碍,以及未来的研究目标。
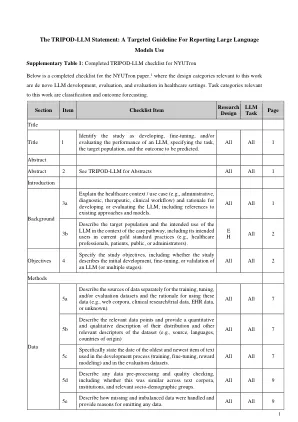
报告大语的目标指南...
llm =大语言模型; M = LLM方法; d = de novo llm开发; E = LLM评估; H =医疗保健设置中的LLM评估; C =分类; =结果预测; QA =长形式提问; ir =信息检索; DG =文档生成; SS =摘要和简化; MT =机器翻译; EHR =电子健康记录。

人工智能的回归:使用主题建模对人工智能法律研究的分析
人工智能研究正处于其历史上的第三次繁荣时期,近年来,与人工智能相关的主题在法律等新学科中获得了相当大的欢迎。本文探讨了人工智能法律研究的构成及其发展方式,同时解决了信息检索和研究重复的问题。使用潜在狄利克雷分配 (LDA) 主题建模对 3931 篇期刊文章的数据集进行研究,我们探讨了三个问题:(a) 人工智能法律研究中的哪些主题可以区分?(b) 这些主题是什么时候讨论的?和 (c) 可以检测到类似的论文吗?主题建模共产生 32 个有意义的主题。此外,研究发现,截至 2016 年,人工智能法律研究急剧增加,主题随着时间的推移变得更加细化和多样化。最后,通过比较算法和人类专家得出的相似性评估,可以发现评估结果往往一致。研究结果有助于了解人工智能法律研究如何随时间演变,并支持开发机器学习和信息检索工具(如 LDA),帮助构建大型文档集并识别相关文章。