XiaoMi-AI文件搜索系统
World File Search System判断

个性化的患者偏好预测因素,用于替代医疗保健的判断:技术上FEA
摘要在为无行为能力的患者做出替代判断时,代理人经常努力猜测患者有能力会想要什么。代理人也可能因(唯一)做出这种决定的责任而感到痛苦。为了解决此类问题,已经提出了一种患者偏好预测因子(PPP),该预测因素将使用算法从人群级别的数据中推断出单个患者的治疗偏好,以了解具有相似人口统计学特征的人的已知偏好。然而,批评家们已经表明,即使这种PPP平均比人类替代者更准确,在识别患者偏好方面,拟议的算法仍然无法尊重患者(以前的)自主权,因为它会借鉴“错误的”数据:对于个人而言,这些数据不适合个人的数据,因此他们不适合他们的挑战,并且他们的实际原因是他们的实际原因,或者是实际的,或者是实际上的,或者是实际上的,或者是实际的,或者是实际的,或者是实际的,或者是实际上所依据的,或者是实际的原因。在船上受到这样的批评,我们在这里提出了一种新方法:个性化的患者偏好预测因子(P4)。P4基于机器学习的最新进展,该技术允许包括大型语言模型在内的技术更便宜,更有效地“微调”在特定于人的数据上。与PPP不同,P4将能够从实际上特定于其特定的材料(例如先前的治疗决策)中推断出单个患者的偏好。因此,我们认为,除了在个体水平上比以前提出的PPP更准确,P4的谓词还将更直接地反映每个患者自身的原因和价值观。在本文中,我们回顾了人工智能研究中的最新发现,这些发现表明P4在技术上是可行的,并认为,如果它是开发和适当部署的,则应缓解一些基于自主的主要关注原始PPP的批评者的关注。然后,我们考虑对我们的提案的各种异议,并提供一些暂定的答复。

开发基于精细语言模型的瑞典法律判断的语义搜索工具
大型语言模型(LLMS)是非常大的深度学习模型,可根据大量数据进行重新训练。是句子的双向编码器表示,来自变形金刚(SBERT)的句子是基于变压器的DeNoising AutoCoder(TSDAE),生成查询网络(GENQ)和生成假伪标记(GPL)的改编。本论文项目旨在为瑞典法律判断开发语义搜索工具,以克服法律文件检索中传统关键字搜索的局限性。为此,使用高级培训方法(例如TSDAE,GENQ和GPL的改编),通过利用自然语言处理(NLP)(NLP)(NLP)(NLP)和精细的LLM来开发一种善于理解法律语言的语义细微差别的模型。要从未标记的数据中生成标记的数据,对其进行微调后使用了GPT3.5模型。使用生成模型的使用标记数据的生成对于该项目有效训练Sbert至关重要。已经评估了搜索工具。评估表明,搜索工具可以根据语义查询准确检索相关文档,并同样提高法律研究的效率和准确性。genq已被证明是此用例的最有效的训练方法。

由您的邻居判断:大型和异构样本的大脑结构规范性概况
从本文准备中使用的数据是从德国国家队列(Nako)获得的(www.nako。de)。NAKO由联邦教育和研究部(BMBF)[项目资金参考编号:01er1301a/b/c,01er1511d,01er1er1er1801a/b/c/c/c/c/d and 01er2301a/b/c],联邦德国和HelmHoltz联合会,该协会和Intistations and Intisitation and Interitation and Interitation and the Institation and the Interitation and Institation and Interations and Interations and Interations and Interations and Interitation and Interations。Nako研究人员在致谢中列出。b在本文制备中使用的数据是从阿尔茨海默氏病新型倡议(ADNI)数据库(adni.loni.usc.edu)获得的。ADNI于2003年作为公私合作伙伴关系成立,由主要研究员Michael W. Weiner,医学博士领导。ADNI的主要目标是测试是否可以合并串行磁共振成像(MRI),正电子发射断层扫描(PET),其他生物学标记物以及临床和神经心理评估,以衡量轻度认知障碍(MCI)和早期阿尔茨海默氏病的进展。c的数据用于准备本文的数据是从额叶洛巴尔变性神经影像学计划(FTLDNI)数据库中获得的。NIFD/FTLDNI的调查人员为FTLDNI和/或提供的数据的设计和实施做出了贡献,但没有参与本报告的分析或撰写(除非另有列出)。FTLDNI研究人员在“确认”部分中进一步列出。AIBL研究人员贡献了数据,但没有参与本报告的分析或撰写。AIBL研究人员在www.aibl.csiro.au上列出。准备本文中使用的数据是从澳大利亚成像生物标志物和衰老的生活方式旗舰研究(AIBL)获得的,该研究由英联邦科学和工业研究组织(CSIRO)资助,该组织在ADNI数据库(www.loni.usc.usc.edu/adni)提供。
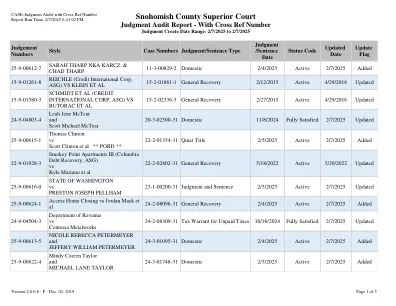
带有交叉参考号码的案例判断审核
15-9-01261-8 Reichle(Credit International Corp,ASG)vs Klein等人15-2-01861-1一般恢复2/12/2015 Active 4/29/2016更新

要求提出建议,以开发用于免疫的非判断性患者教育的AI工具
错误的信息和虚假信息已成为对患者的护理和健康,我们社区的公共卫生以及医学实践的核心价值和科学基础的主要威胁。它破坏了患者与医生之间的信任,并助长了司法和立法入侵检查室。它有助于处理监管,法律,哲学和专业的医生的压力和工作量,这些医生与基于证据,及时和富有同情心的患者的照料相抵触。它已成为道德困扰和倦怠的重要来源,可能对医师的实践和福祉产生不利影响。社交媒体,虚假新闻网站,政治消息,算法分发针对个人利益和恐惧的算法分发,向易感人士的营销产品,名人代言,主流媒体,AI产生的深层效果以及没有优先准确的精确度的搜索引擎是错误的,但是有一些错误和失败的方式被引入,并且被介绍了。在影响患者的护理或医生的福祉时,几乎没有解决这些问题可以解决这些问题。MIS和虚假信息的最困难和最普遍的领域之一是疫苗。媒体和在线论坛的虚假信息和毫无根据的怀疑论促进对疫苗接种的有效性,安全性或重要性的不信任会激发犹豫不决和拒绝,这破坏了对公共卫生的信任以及保护它的主要护理任务。目标这可能会影响患者就诊的重点和工作流程,并内在减少信任,从而破坏医生提供预期护理和实践中的快乐的能力。该项目旨在通过利用AI在访问前向患者提供有关免疫接种的准确,基于证据和非判断性的信息来解决这些挑战,从而减少冲突,时间和精力来有效解决这些问题。我们正在寻求提案,以开发和实施AI工具,旨在以非判断性和信息性的方式对患者/父母进行有关免疫接种的知识。目的是提高患者对支持个人和公共卫生的免疫常规的重要性和信心,减少讨论患者接触中的免疫接种所花费的时间,并建立对患者 - 医学关系的信任。

要求提出建议,以开发用于免疫的非判断性患者教育的AI工具
错误的信息和虚假信息已成为对患者的护理和健康,我们社区的公共卫生以及医学实践的核心价值和科学基础的主要威胁。它破坏了患者与医生之间的信任,并助长了司法和立法入侵检查室。它有助于处理监管,法律,哲学和专业的医生的压力和工作量,这些医生与基于证据,及时和富有同情心的患者的照料相抵触。它已成为道德困扰和倦怠的重要来源,可能对医师的实践和福祉产生不利影响。社交媒体,虚假新闻网站,政治消息,算法分发针对个人利益和恐惧的算法分发,向易感人士的营销产品,名人代言,主流媒体,AI产生的深层效果以及没有优先准确的精确度的搜索引擎是错误的,但是有一些错误和失败的方式被引入,并且被介绍了。在影响患者的护理或医生的福祉时,几乎没有解决这些问题可以解决这些问题。MIS和虚假信息的最困难和最普遍的领域之一是疫苗。媒体和在线论坛的虚假信息和毫无根据的怀疑论促进对疫苗接种的有效性,安全性或重要性的不信任会激发犹豫不决和拒绝,这破坏了对公共卫生的信任以及保护它的主要护理任务。目标这可能会影响患者就诊的重点和工作流程,并内在减少信任,从而破坏医生提供预期护理和实践中的快乐的能力。该项目旨在通过利用AI在访问前向患者提供有关免疫接种的准确,基于证据和非判断性的信息来解决这些挑战,从而减少冲突,时间和精力来有效解决这些问题。我们正在寻求提案,以开发和实施AI工具,旨在以非判断性和信息性的方式对患者/父母进行有关免疫接种的知识。目的是提高患者对支持个人和公共卫生的免疫常规的重要性和信心,减少讨论患者接触中的免疫接种所花费的时间,并建立对患者 - 医学关系的信任。

表征基于触摸屏的GO/NO GO,用于评估小鼠认知判断偏见的任务:一种用于情感状态疾病药物筛查的新翻译工具
预印本(未通过同行评审认证)是作者/资助者。保留所有权利。未经许可就不允许重复使用。此版本的版权持有人于2025年1月20日发布。 https://doi.org/10.1101/2025.01.20.633915 doi:Biorxiv Preprint

关键词:临床判断,高保真模拟,效果,护理学生。 *请引用这篇文章为:Mohammadpourhodki R,Karimi Moonaghi
Q1:真正的随机化是用于将参与者分配给治疗组的真正随机分组?Q2:藏匿的分配是分配给涉及试验人员的治疗组? Q3:基线相似性在基线时治疗组是否相似以最大程度地减少现有的差异? Q4:参与者失明的参与者是否对其治疗作业视而不见,以减少报告偏见? Q5:治疗提供者失明的是那些接受治疗的人对小组分配失明以最大程度地减少绩效偏见? Q6:结果评估师失明是结果评估者对治疗分配失明以减少检测偏见? Q7:相同的治疗条件是实验组是否相同治疗,除了干预外,治疗组是否相同? Q8:随访完整的后续性完整性,并且随访的差异是否充分描述和分析? Q9:在他们被随机分析的组中分析了参与者的意向性分析? Q10:一致的结果测量是在治疗组之间始终如一地测量结果吗? Q11:可靠的测量是使用可靠方法测量结果的吗? Q12:适当的统计分析是适用于数据的适当统计分析吗? Q13:试验设计适当性是否适合试验设计,并且与标准RCT方案的偏差合理吗?Q2:藏匿的分配是分配给涉及试验人员的治疗组?Q3:基线相似性在基线时治疗组是否相似以最大程度地减少现有的差异?Q4:参与者失明的参与者是否对其治疗作业视而不见,以减少报告偏见? Q5:治疗提供者失明的是那些接受治疗的人对小组分配失明以最大程度地减少绩效偏见? Q6:结果评估师失明是结果评估者对治疗分配失明以减少检测偏见? Q7:相同的治疗条件是实验组是否相同治疗,除了干预外,治疗组是否相同? Q8:随访完整的后续性完整性,并且随访的差异是否充分描述和分析? Q9:在他们被随机分析的组中分析了参与者的意向性分析? Q10:一致的结果测量是在治疗组之间始终如一地测量结果吗? Q11:可靠的测量是使用可靠方法测量结果的吗? Q12:适当的统计分析是适用于数据的适当统计分析吗? Q13:试验设计适当性是否适合试验设计,并且与标准RCT方案的偏差合理吗?Q4:参与者失明的参与者是否对其治疗作业视而不见,以减少报告偏见?Q5:治疗提供者失明的是那些接受治疗的人对小组分配失明以最大程度地减少绩效偏见? Q6:结果评估师失明是结果评估者对治疗分配失明以减少检测偏见? Q7:相同的治疗条件是实验组是否相同治疗,除了干预外,治疗组是否相同? Q8:随访完整的后续性完整性,并且随访的差异是否充分描述和分析? Q9:在他们被随机分析的组中分析了参与者的意向性分析? Q10:一致的结果测量是在治疗组之间始终如一地测量结果吗? Q11:可靠的测量是使用可靠方法测量结果的吗? Q12:适当的统计分析是适用于数据的适当统计分析吗? Q13:试验设计适当性是否适合试验设计,并且与标准RCT方案的偏差合理吗?Q5:治疗提供者失明的是那些接受治疗的人对小组分配失明以最大程度地减少绩效偏见?Q6:结果评估师失明是结果评估者对治疗分配失明以减少检测偏见?Q7:相同的治疗条件是实验组是否相同治疗,除了干预外,治疗组是否相同?Q8:随访完整的后续性完整性,并且随访的差异是否充分描述和分析?Q9:在他们被随机分析的组中分析了参与者的意向性分析?Q10:一致的结果测量是在治疗组之间始终如一地测量结果吗?Q11:可靠的测量是使用可靠方法测量结果的吗? Q12:适当的统计分析是适用于数据的适当统计分析吗? Q13:试验设计适当性是否适合试验设计,并且与标准RCT方案的偏差合理吗?Q11:可靠的测量是使用可靠方法测量结果的吗?Q12:适当的统计分析是适用于数据的适当统计分析吗? Q13:试验设计适当性是否适合试验设计,并且与标准RCT方案的偏差合理吗?Q12:适当的统计分析是适用于数据的适当统计分析吗?Q13:试验设计适当性是否适合试验设计,并且与标准RCT方案的偏差合理吗?Q13:试验设计适当性是否适合试验设计,并且与标准RCT方案的偏差合理吗?

人工智能与审美判断
摘要:生成式人工智能以人类的表达方式产生创造性的输出。我们认为,与现代生成式人工智能模型的输出的接触是由与我们与艺术品互动时组织相同的审美判断所介导的。我们对博物馆中发现的艺术品使用的解释程序不是人类天生的能力,而是由艺术史和艺术批评等学科在历史上发展起来的,以实现某些社会功能。这让我们在考虑对生成式人工智能的反应、我们应该如何对待这种新媒介以及为什么生成式人工智能似乎会引发对未来的如此多恐惧时停下来思考。我们自然而然地从艺术史中继承了一个因果推理的难题:一件作品可以被解读为影响其创作的文化条件的症状,同时又被框定为永恒的、看似无因果的永恒人类状况的提炼。在本文中,我们将重点关注在生成式人工智能的背景下将这一困境带到一起时产生的一个未解决的紧张关系:我们是在寻找证据证明生成的媒体反映了创造它的条件还是某种永恒的人类本质?当前的解读模式是否足以完成这项任务?从历史上看,新的艺术形式改变了人们解读艺术的方式,这种影响被用作艺术作品触及人类某些基本真理的证据。由于生成式人工智能影响当代审美判断,我们概述了在尝试审视人工智能生成的媒体意味着什么时遇到的一些陷阱和陷阱。

判断
7. 上诉人对裁决和命令不违宪的裁定提出上诉。此外,根据 Rahim J 对总统自由裁量权的观察,上诉人认为,2006 年法案第 75(a) 条与宪法第 80(1) 条一起阅读,要求总统在决定是否批准延期时自行决定,而不是根据内阁的建议行事,这是违法行为的另一个理由。上诉法院 (Moosai、Mohammed 和 Aboud JJA) 于 2024 年 5 月 8 日作出判决,驳回上诉,理由主要与 Rahim J 给出的一样:2006 年法案第 75(a) 条和宪法第 123 条之间没有矛盾,因为这两项规定涉及的是不同的问题,彼此之间没有重叠。上诉法院还裁定,第 75(a) 条并不违反权力分立原则或由此衍生的任何所谓的“隔离原则”。