XiaoMi-AI文件搜索系统
World File Search System医学知识

多范围:多方面的评估,以探测掌握医学知识的LLMS
大型语言模型(LLM)在跨领域表现出色,在医学评估基准(例如MEDQA)上也提供了显着的表现。但是,在现实世界中医学场景中,报告的性能与实际有效性之间仍然存在显着差距。在本文中,我们旨在通过采用多方面的检查模式来系统地探索当前LLM的实际掌握医学知识的掌握,以探讨这一差距的原因。具体而言,我们开发了一种新颖的评估框架多叶序,以检查LLM在多个方面的编码和掌握医学知识中的范围和覆盖范围。基于多叶术框架,我们构建了两个多方面的评估数据集:Multidisek(通过从临床疾病知识库中产生问题)和MultiMEDQA(通过将Medical Benchmark MedQA从Medical Benchmark MedQa重新提出每个问题,以进行多方面的问题)。这些模拟数据集的实验结果表明,掌握医学知识的当前LLM的程度远低于其在现有医疗基准上的表现,这表明它们缺乏深度,预见和在掌握知识中的全面性。因此,当前的LLM尚未准备好在现实世界中的任务中应用。代码和数据集可在https://github.com/thumlp/multifaceteval上找到。


MKECL:医学知识增强的对比度学习,用于几次疾病诊断
抽象人工智能(AI)辅助疾病预测由于其支持临床决策的能力而获得了广泛的研究兴趣。现有作品主要将疾病预测作为多标签分类问题,并使用历史电子病历(EMR)来培训监督模型。然而,在现实世界中,这种纯粹的数据驱动方法提出了两个主要挑战:1)长尾巴问题:常见疾病的EMR过多,并且对于罕见疾病的EMR不足,因此对不平衡的数据集进行培训可能会导致在诊断中忽略偏见模型的偏见模型; 2)很容易误诊疾病:某些疾病很容易区分,而另一些疾病则更加困难。一般分类模型而不强调容易诊断的疾病可能会产生错误的预测。为了解决这两个问题,我们在本文中提出了一种医学知识增强的对比学习方法(MKECL)方法。MKECL将医学知识图和医学许可考试纳入建模中,以弥补有关稀有疾病的足够信息;为了处理难以诊断的疾病,MKECL引入了一种对比度学习策略,以分离容易被误诊的疾病。此外,我们建立了一个名为Jarvis-D的新基准,其中包含从各种医院收集的临床EMR。对实际临床EMR的实验表明,拟议的MKECL优于现有的疾病预测方法,尤其是在几乎没有射击和零拍的情况下。

解锁患者护理和疗法突破与生物医学知识的突破。
AI药物解决方案可满足药物伙伴在改善药物发现和开发方面的复杂需求,分子健康已建立了一种服务模型,该模型将Dataome的全面内容与使用AI方法,图形分析和疾病模型设计的量身定制的分析汇总在一起。分子健康的完整智力和技术力量流入旨在加速药物开发和降低成本的服务项目。从了解基于更好的目标疾病关系的复杂疾病的生物学来增强管道药物候选物的价值并优化临床试验设计的价值,AI Pharma Solutions以一种变革性的方式利用了生物医学数据。通过三角剖分患者,疾病和分子数据,AI Pharma Solutions在开发过程中的任何一点都揭示了化合物的治疗影响,而不仅仅是化合物的化学行为。

HOMEDOCTOR APP:将医学知识纳入GPT供个人健康咨询
对医疗保健专业人员的工作量不断增加的需求正在导致系统性超负荷,从而导致公共卫生服务效率下降。这种情况需要开发解决方案,这些解决方案可以减轻医生的负担,同时确保全面的患者护理。生成人工智能的最新进步,尤其是在医学领域,已经表明,大型语言模型(LLMS)可以超越特定任务的医生,从而将其作为减少医疗保健提供者压力的有价值的工具高发。这项研究的重点是归档应用程序的开发,该应用程序将额外的医学知识集成到GPT-4O LLM中。此应用程序的目的和增强的LLM是为用户提供可靠的访问医疗聊天机器人的访问,能够提供与健康相关的查询的准确及时响应。与一组医生合作,对聊天机器人的Be-Havior进行了精心测试和完善。这项研究的发现提供了有关此类系统开发的见解,并探索了他们在斯洛文尼亚医疗保健系统中的潜在应用。


嵌入医学概念的多信息源
摘要。在改善公共医疗保健应用(例如计算机辅助诊断系统)方面,学习医学障碍的低维表示非常重要。现有方法依靠电子健康记录(EHR)作为其唯一的信息来源,并且不利用丰富的外部医学知识,因此它们忽略了医疗概念之间的相关性。为了解决这个问题,我们提出了一种新颖的多信息源杂种信息网络(HIN),以建模EHR,同时纳入了外部医学知识,包括ICD-9-CM和网格,以进行丰富的网络架构。我们的模型非常了解EHR的结构以及它所指的医学概念之间的相关性,并学习了语义反射医学概念的嵌入。在例外,我们的模型在各种医疗数据挖掘任务中都优于无监督的基线。
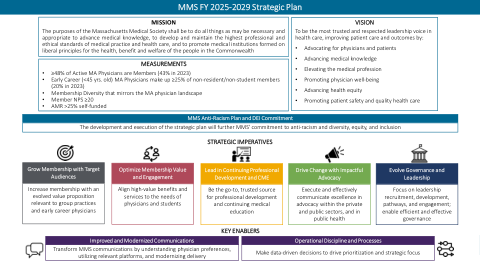
MMS 2025-2029 财年战略计划
使命马萨诸塞州医学会的宗旨是尽一切必要和适当的努力来促进医学知识的发展,发展和维护医疗实践和医疗保健的最高专业和道德标准,并促进以自由主义原则为基础的医疗机构的发展,以造福联邦人民。

ME 医疗电子手册
医学电子学硕士 (ME Medical Electronics) 是一个为期两年的研究生课程;它是一门专业学科,通过跨学科活动将电子和工程科学与生物医学和临床实践相结合,提高工程和医学知识。本课程将生物学和医学知识与工程原理和实践相结合,帮助开发解决医学和健康相关问题的设备和程序。它提供基于研究和实践导向的强化学习,并在以下领域进行专业化:SSN 的医学电子课程课程在制定时考虑到学生需要接受培训以应对现代医疗器械行业的挑战,通过提供必要的工程知识和技能来分析问题、设计和开发解决方案。它使学生能够熟练地使用现代工具(包括数据科学、机器学习和虚拟现实)来解决医学问题。基于选择的专业化包括:

如何引用本文Terwilliger E,Bcharah G,Bcharah H等。 (2024年7月9日)进步医学教育:生成人造
AI的出现自然提出了有关如何将生成AI模型用作医学领域工具的问题,例如用于研究目的。董事会考试代表了大多数医学生和居民的医学知识的关键里程碑。回答董事会式问题的能力通常是多维的,要求学员使用知识和判断来得出结论性的答案。董事会提供了1248个练习问题,以模拟居住结束时耳鼻喉科委员会考试的问题样式和内容。问题以三种方式过滤:问题状态,难度水平和主题[13]。这项研究旨在研究三种主要的AI模型(CHATGPT,GPT-4或Google Bard)的准确性,以及用于查询板风格的,耳鼻喉科学 - 特定医学知识的效用。此外,使用基于图像的问题[7,14]中的基于图像的问题,分别测试了GPT-4和BARD的新发布的GPT-4和BARD的图像 - 交易功能,分别于09/25/2023和09/19/2023进行了测试。