XiaoMi-AI文件搜索系统
World File Search System单词
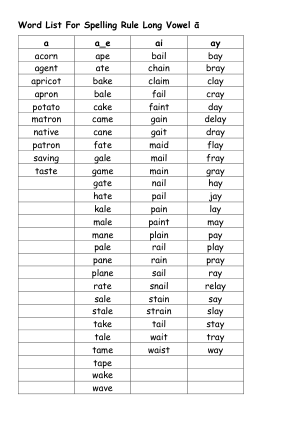
拼写规则 长元音 ā 的单词列表
e ee ea y ee 自我 啤酒 击败 婴儿 蜜蜂 埃及 爬行 欺骗 肚子 费用 平等 行为 奶油 爸爸 逃跑 甚至 鹿 梦想 小狗 免费 晚上 喂养 恐惧 快乐 李 邪恶 感觉 壮举 山丘 小便 唤起 脚 跳蚤 生气 看到 贪婪 齿轮 木乃伊 树 下面 脚跟 热 尿布 twee 细节 见面 餐 小狗 小猫 针 肉 流鼻涕 耶稣 窥视 豌豆 潮湿 仪表 女王 花生 湿漉漉的 报告 礁石 泥炭 阳光明媚 亮片 种子 恳求 泰迪熊 似乎 阅读 美味 渗透 印章 羊 座位 睡觉 小麦 速度 陡峭 扫掠 青少年 牙齿 杂草 哭泣 轮子


单词问题策略 - 三个读取协议目的
样本问题词干:朱迪的浆果朱迪喜欢吃早餐,午餐和晚餐吃浆果。她看到Clear Lake School正在筹集筹款活动来为一个新的操场筹集资金。学生正在出售水果篮来筹集资金。草莓的售价为每篮3美元。蓝莓的售价为每篮4美元。覆盆子的售价为每篮5美元。朱迪有20美元用于浆果。

复合单词变压器:学习构成全...
要将神经序列模型(例如变形金刚)应用于音乐发电任务,必须通过一系列有限的代币来代表一段音乐。这样的词汇通常涉及各种类型的令牌。例如,要描述音符,一个人需要单独的令牌来指示音符的音高,持续时间,速度(动态)和放置时间(起始时间)。虽然不同类型的令牌可能具有不同的适当性,但现有模型通常以与自然语言建模单词相同的方式对待它们。在本文中,我们提出了一种概念上不同的方法,该方法明确考虑了令牌的类型,例如注释类型和度量标准类型。,我们提出了一种新的变压器解码器 - 使用不同的馈送头来建模不同类型的kens。通过扩展压缩技巧,我们通过对相邻令牌进行分组,大大降低了令牌序列的长度,从而将一段音乐转换为一系列复合单词。我们表明,在动态有向超图中,可以将结果模型视为学习者。,我们采用它来学会创作全面的长度长度(每首歌曲最多涉及10k个个人to-kens)的表现力的流行钢琴音乐,无论是有条件地和无条件的)。我们的实验表明,与最先进的模型相比,所提出的模型在训练时收敛了5至10倍(即,在一天的GPU上,在具有11 GB内存的单个GPU上),并且在生成的音乐中具有可比的质量。


表征大脑中的动态单词含义表示
单词含义不仅仅是字典中的条目。它涉及大量的知识,这些知识将人们遇到的场景和经历(即,丰富的百科全书知识)(即适当地适用这个词(即男孩很生气),其他单词的组合以及词出现的语法结构。单词的含义因情况而异以及使用上下文各不相同。例如,用来描述蚊子,鲸鱼或行星时,“小”一词意味着不同的东西。与小小相关的属性在上下文依赖性方面有所不同:有必要知道单词的含义,但也必须知道所使用的上下文,以及如何结合单词以构建含义(Medin&Shoben,1988)。



拼写单词-列表 11 长 a: a, ai, ay
名词。为了表示所有权,当名词为单数时,添加撇号 (') 和 -s。当名词为复数时,只需添加撇号 (')。示例:火鸡的尾巴 ---- 兔子的尾巴