XiaoMi-AI文件搜索系统
World File Search System学习过程
学习过程清单
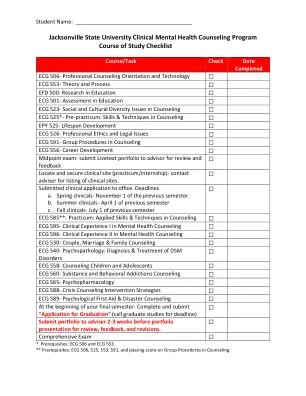
Course of Study Checklist Course/Task Check Date Completed ECG 506- Professional Counseling Orientation and Technology ☐ ECG 553- Theory and Process ☐ EFD 500- Research in Education ☐ ECG 501- Assessment in Education ☐ ECG 523- Social and Cultural Diversity Issues in Counseling ☐ ECG 525*- Pre-practicum: Skills & Techniques in Counseling ☐ EPY 525- Lifespan Development ☐ ECG 526-职业道德和法律问题☐ECG591-咨询中的小组程序☐ECG556-职业发展☐中点考试 - 中点考试 - 将LiveText Portfolio提交给顾问,以进行审查和反馈

与学生参与学习过程 -
国际教育技术杂志(IJTE)是经过同行评审的学术在线杂志。本文可用于研究,教学和私人学习目的。作者仅负责其文章内容。期刊拥有文章的版权。出版商不应对直接或间接导致或因使用研究材料而直接或间接引起的任何损失,诉讼,诉讼,需求或损害或损害或损害。所有作者都被要求披露任何实际或潜在的利益冲突,包括与其他人或组织有关提交工作的任何财务,个人或其他关系。

解构作为机器学习过程
摘要 连续数据流是现代信息处理中常见但具有挑战性的现象。将机器学习技术应用于此设置的传统方法,如离线和在线学习,已显示出几个关键的缺点。为了避免这两种方法的已知缺点,我们建议将它们的互补优势结合在一个称为解构的新型机器学习过程中。与监督学习和无监督学习类似,这种新颖的过程提供了一种模仿人类学习的基本学习功能。此功能集成了对训练数据进行分区、管理学习到的知识表示以及将新获得的知识与以前学习到的知识表示相结合的机制。此概念的先决条件是可以对学习数据进行分区,并且可以通过正式方式访问生成的知识分区。在所提出的方法中,这是通过最近引入的建构主义机器学习框架实现的,该框架允许创建、利用和维护知识库。在这项工作中,我们重点介绍了实施这种解构过程的设计概念。特别是,我们描述了所需的子过程以及如何将它们组合在一起。

AIH 第 3 章:学习过程
根据建构主义,人类通过将已有信息与从感官获得的信息相结合来构建独特的心理形象。学习是将新信息与已有信息进行匹配并将其整合成有意义的联系的结果。在建构主义思维中,学习者被赋予了更多的自由来成为有效的问题解决者,识别和评估问题,以及解释将他们的学习转移到这些问题上的方法,所有这些都培养了批判性思维技能。虽然学习者是这个过程的中心,但经验丰富的老师是必要的,以引导他们穿越信息丛林。建构主义技术适用于某些类型的学习、某些情况和某些个人,但并非全部。这一思想流派还鼓励教学习者如何使用布鲁姆分类学中所谓的高阶思维技能 (HOTS) 以及基于问题或场景的培训。建构主义是第 5 章“教学过程”中介绍的几种培训交付方法的基础。

人工智能促进学习过程的学习理论
摘要 本文讨论了一种三级模型,该模型综合并统一了现有的学习理论,以模拟人工智能 (AI) 在促进学习过程中的作用。该模型取材于发展心理学、计算生物学、教学设计、认知科学、复杂性和社会文化理论,包括一个因果学习机制,该机制解释了学习是如何在微观、中观和宏观层面发生和运作的。该模型还解释了通过学习获得的信息是如何在各个层面内和跨层面聚合或汇集、消散或释放和使用的。根据该模型的特点,提出了人工智能在教育中的十四种角色:四个角色在个人或微观层面,四个角色在团队和知识社区的中观层面,六个角色在文化历史活动的宏观层面。其中包括对研究和实践的影响、评估标准和局限性的讨论。有了提出的模型,人工智能开发人员可以专注于与学习设计师、研究人员和从业人员合作,利用提出的角色来改善个人学习、团队绩效和建立知识社区。

融入人工智能技术加速学习过程
本研究探讨了人工智能技术在加速大学生外语习得方面的潜力。人工智能技术利用机器学习、数据分析和聊天机器人,有望以定制化和适应性的方式提高语言习得的效率。本研究探讨了在外语习得背景下整合人工智能的几种方法,并评估了它们对学生语言能力的影响。所采用的方法包括测试和调查,目的是收集实证数据。研究结果表明,利用人工智能技术可以加快知识获取过程,增强积极性,并优化外语习得结果。本研究的结果表明,人工智能技术具有相当大的能力,可以彻底改变高等教育机构的外语习得过程。

通过顺序学习过程列表以生成检索模型
最近,已经提出了一种新颖的生成检索(GR)范式,其中学会了单个序列到序列模型直接生成相关文档标识的列表(DOCID),给定查询。现有的GR模型通常采用最大似然估计(MLE)进行优化:这涉及给定输入查询的单个相关文档的可能性最大化,并假设每个文档的可能性独立于列表中的其他文档。我们将这些模型称为本文的重点方法。虽然在GR的上下文中已显示出侧面的方法是有效的,但由于其无视基本原则,即排名涉及对列表进行预测,因此被认为是次优的。在本文中,我们通过引入替代列表方法来解决此限制,该方法赋予GR模型以优化DOCID列表级别的相关性。从特定上讲,我们将排名copid列表的生成视为一个序列学习过程:在每个步骤中,我们学习了一个参数的子集,这些参数最大化了the DocID的相应生成可能性,给定(前面的)顶部 - 1个文档。为了形式化序列学习过程,我们为GR设计了位置条件概率。为了减轻梁搜索对推断期间发电质量的潜在影响,我们根据相关性等级对模型生成的文档的生成可能性执行相关性校准。我们对代表性的二进制和多层相关性数据集进行了广泛的实验。我们的经验结果表明,在检索性能方面,我们的方法优于最先进的基准。

通过顺序学习过程列表以生成检索模型
最近,已经提出了一种新颖的生成检索(GR)范式,其中学会了单个序列到序列模型直接生成有关查询的相关文档标识符(DOCID)列表。现有的GR模型通常采用最大似然估计(MLE)进行优化:这涉及给定输入查询的单个相关文档的可能性最大化,并假设每个文档的可能性独立于列表中的其他文档。我们将这些模型称为本文的重点方法。虽然在GR的背景下已显示出刻的方法有效,但由于其无视基本原则,即排名涉及对列表进行预测,因此被认为是最佳的。在本文中,我们通过引入替代列表方法来解决此限制,该方法赋予GR模型以优化DOCID列表级别的相关性。具体来说,我们将排名的DOCID列表的生成视为一个序列学习过程:在每个步骤中,我们都会学习一个参数子集,这些参数最大化了the -th docID的相应生成可能性,给定(前面)顶部𝑖 -1个文档。为了形式化序列学习过程,我们为GR设计了位置条件概率。为了减轻梁搜索对推断期间发电质量的潜在影响,我们根据相关性等级对模型生成的文档的生成可能性执行相关性校准。我们对代表性的二进制和多层相关性数据集进行了广泛的实验。我们的经验结果表明,在检索性能方面,我们的方法优于最先进的基准。

通过顺序学习过程列表以生成检索模型
最近,已经提出了一种新颖的生成检索(GR)范式,其中学会了单个序列到序列模型直接生成有关查询的相关文档标识符(DOCID)列表。现有的GR模型通常采用最大似然估计(MLE)进行优化:这涉及给定输入查询的单个相关文档的可能性最大化,并假设每个文档的可能性独立于列表中的其他文档。我们将这些模型称为本文的重点方法。虽然在GR的背景下已显示出刻的方法有效,但由于其无视基本原则,即排名涉及对列表进行预测,因此被认为是最佳的。在本文中,我们通过引入替代列表方法来解决此限制,该方法赋予GR模型以优化DOCID列表级别的相关性。具体来说,我们将排名的DOCID列表的生成视为一个序列学习过程:在每个步骤中,我们都会学习一个参数子集,这些参数最大化了the -th docID的相应生成可能性,给定(前面)顶部𝑖 -1个文档。为了形式化序列学习过程,我们为GR设计了位置条件概率。为了减轻梁搜索对推断期间发电质量的潜在影响,我们根据相关性等级对模型生成的文档的生成可能性执行相关性校准。我们对代表性的二进制和多层相关性数据集进行了广泛的实验。我们的经验结果表明,在检索性能方面,我们的方法优于最先进的基准。

将生成人工智能技术融入教学和学习过程的指南
视频或音乐。这些工具还根据书面说明产生结果,其中一些可以响应视觉或音乐提示。基于图像的 genAI 的一些主要代表是: Midjourney 、 DALL•E 和 Dreamstudio 。关于视频 genAI 最受欢迎的是 Runway 和 Heygen 。最后,在音乐 genAI 领域,以下是 Boomy 和 Voicemod 。