XiaoMi-AI文件搜索系统
World File Search System模拟数据

4M25-最终报告系统标识和基于模型的...
已经开发了一个简单的软操作器 - 一种仅在其底部致动的连续软杆,以探索这些模型。系统标识首先是使用全部信息,然后使用有限的信息来得出操纵器的动力学。然后,通过基于模型的RL对控制器进行训练,目的是将Ma-Nipulator保持在直立位置。这种方法通过通过学习动力学生成模拟数据来规避收集数据以进行无模型增强学习的效率低下。的目标是,通过对模拟动态进行训练,增强能够比实时培训更快,从而提高数据效率。比较了无模型和基于模型的方法以测试这一点。然后,还将增强学习与传统线性季节调节器(LQR)控制和比例积分衍生物(PID)控制的功效进行比较。作为外部影响和训练,有Pilco((Deisenroth&Rasmussen,2011)),这是一种基于Gaussian过程的控制学习计划,用于系统识别和策略搜索试验之间的控制。
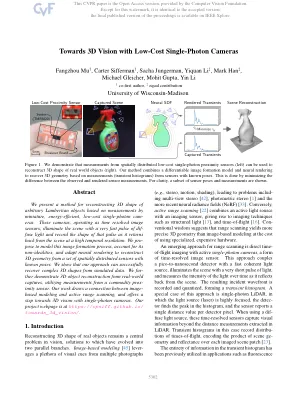
朝着低成本单光子摄像机迈向3D视觉
我们提出了一种基于微型,能量,低成本的单光子凸轮的测量值来重建任意兰伯特对象的3D形状的方法。这些摄像机作为时间解析的图像传感器运行,用非常快速的脉冲脉冲融合了光,并记录了该脉冲的形状,因为它以高时间分辨率从场景中返回。我们提出了模拟此图像形成过程的建模,解释其非理想性,并适应神经渲染以从一组具有已知姿势的空间分布的传感器中重建3D几何形状。我们表明,我们的方法可以从模拟数据中成功恢复复杂的3D形状。我们利用商品代理传感器的测量结果来证明实际捕获的3D对象重建。我们的工作在基于图像的建模和活动范围扫描之间建立了连接,并通过单光子摄像机朝着3D视觉提供了一步。我们的项目网页位于https://cpsiff.github.io/ toug_3d_vision/。

内容 - TeK Associates
Nuttall。这两种算法都在第 2 章中进行了描述。第 3 章描述了对模拟数据进行的实验,首先测试了为本次调查实施的软件工具,并在附录 D、E、F 和 G 中提供了支持性讨论。然后将这些工具应用于实际数据。这些实验指出了在寻求将多通道 LP 建模应用于雷达目标数据时遇到的这两种代表性算法的一些已知优势和劣势。附录 F 指出了在应用这些多通道 LP 算法时遇到的一些一般问题。第 4 章提供了仅使用自回归 (AR) 过程模型而不是显然更通用的自回归移动平均 (ARMA) 过程的考虑因素。第 5 章及其辅助附录 A 讨论了如何有效处理存在的雷达模糊函数效应,这些效应会影响处理结果,因此,如何根据计算的相干函数表示和相关的调节置信区域来缓和最终的互相关结果和结论。第 5 章将这些技术应用于 Tradex RV 尾流数据,作为对表示连续雷达距离门和/或

EC-GAN:通过生成对抗网络推断大脑有效连接
从功能性磁共振成像(fMRI)数据推断不同大脑区域之间的有效连接是近年来神经信息学领域的一项重要前沿研究。然而,由于fMRI数据噪声大、样本量小,目前的方法在有效连接研究中的应用受到限制。在本文中,我们提出了一种基于生成对抗网络(GAN)推断有效连接的新框架,称为EC-GAN。所提出的框架EC-GAN通过对抗过程推断有效连接,其中我们同时训练两个模型:生成器和鉴别器。生成器由一组基于结构方程模型的有效连接生成器组成,可通过有效连接生成每个大脑区域的fMRI时间序列。同时,采用鉴别器来区分真实的和生成的fMRI时间序列的联合分布。在模拟数据上的实验结果表明,与其他最新方法相比,EC-GAN可以更好地推断有效连接。真实世界的实验表明,EC-GAN 可以为分析 fMRI 数据的有效连接提供一个全新的、可靠的视角。

COVID-19 的传播与卡介苗
随着 COVID-19 在全球蔓延,一些观察人士注意到,在疫情爆发初期,仍在使用一种古老的结核病疫苗(卡介苗)的国家,其 COVID-19 病例和人均死亡人数较少。本文使用地理回归不连续性分析来研究 COVID-19 流行率在西德和东德旧边界是否以及如何不连续地变化。这条边界曾在冷战时期将两个疫苗接种政策截然不同的国家分隔开来。我们提供了正式证据,表明边境的 COVID-19 病例确实存在相当大的不连续性。然而,我们还发现,不同年龄组的新型冠状病毒流行率差异是一致的,并表明当考虑到通勤流量和人口统计数据时,这种不连续性就会消失。这些发现与卡介苗假设不符。然后,我们为东西方分歧提供了另一种解释。我们模拟了德国每个县的流行病的典型 SIR 模型,允许感染沿着通勤模式传播。我们发现,在模拟数据中,当人们从西向东跨越原边界时,病例数也会不连续地下降。

噪声量子硬件上双点动态平均场理论的量子经典模拟
摘要 我们报告了使用双点动态平均场理论 (DMFT) 对单波段哈伯德模型进行量子经典模拟。我们的方法使用 IBM 的超导量子比特芯片在时间域中计算零温度杂质格林函数,并使用经典计算机拟合测量的格林函数并提取其频域参数。我们发现量子电路合成 (Trotter) 和硬件错误会导致频率估计不正确,随后导致从自能的频率导数计算时准粒子权重不准确。这些错误会产生错误的杂化参数,从而阻止 DMFT 算法收敛到正确的自洽解。为了避免这个陷阱,我们通过对谱函数中的准粒子峰进行积分来计算准粒子权重。这种方法对 Trotter 误差的敏感度要低得多,并且在将量子误差缓解技术应用于量子模拟数据后,算法可以收敛到半填充 Mott 绝缘系统的自洽性。

介导药物处置 (TMDD)
摘要靶介导药物处置 (TMDD) 模型用于模拟非线性药代动力学 (PK),因为一种药物与其药理靶标以高亲和力结合,影响药代动力学特性。TMDD 近似模型的出现是因为在有限的数据下难以实现完整的 TMDD 模型来解决复杂模型的过度参数化问题。传统的群体 TMDD 模型开发既耗时又主观,需要建模者的经验。本论文提出了一种 TMDD 模型开发和排序策略,可以实现自动 TMDD 模型开发。当前的工作旨在建立一种可以自动化扩展到 Pharmpy/Pharmr 包的 TMDD 模型开发策略,以使自动模型开发 (AMD) 工具能够对非线性 PK 进行更复杂的描述。使用已发布的五种化合物 TMDD 模型的模拟数据来开发和测试 TMDD 模型开发策略。首先,根据文献和自动模型开发程序的实际考虑选择合适的估计方法,以提高建模效率。其次,提出了一种在模型开发过程中设置新参数初始估计值的算法,并在两个具有潜在代表性的 TMDD 近似模型上进行了测试,以便于估计收敛。测试了似然比检验 (LRT) 和贝叶斯信息准则 (BIC) 作为模型选择标准。最后,提出了完整的 TMDD 模型开发策略,并用五个模拟数据进行了测试。在结构模型搜索后,选择准稳态模型 (QSS) 而不是米氏近似模型 (MMAPP) 作为代表性 TMDD 近似模型,并发现足以识别正确的结构模型。其他 TMDD 模型从 QSS 模型更新了初始估计值,其中目标降解速率常数 (KDEG) 和基线目标浓度 (R0) 的初始估计值的不同梯度也提供了合理的目标函数值 (OFV)。鉴于 BIC 的排序标准和模型开发策略,每个数据的最佳模型至少与模拟模型一样复杂。此外,4/5 的数据对那些非目标相关参数给出了准确的估计,并且 OFV 并不比以“真实”参数作为初始估计的模型差很多。总之,所提出的 TMDD 模型开发策略简化了 TMDD 模型的开发和选择,并且有可能在 AMD 中实施以实现自动 TMDD 模型开发。

通过时间对自旋玻璃进行量子过程断层扫描......
在表征量子系统时,量子过程层析成像 (QPT) 是标准基元。但由于量子系统的高度复杂性和维数灾难,QPT 在处理大量量子比特时变得不切实际。另一方面,将 QPT 与机器学习相结合在最近的研究中取得了巨大的成功。在本文中,我们探索了将 QPT 与机器学习和参数化量子电路相结合的机会,以重建自旋玻璃的汉密尔顿量。这产生了一个相当简单和直接的算法。为此,首先推导出必要的量子电路。借助此,重建了 Ising 自旋的汉密尔顿量。最后,我们切换到与 Ising 自旋没有太大区别的自旋玻璃,并在此执行相同的操作。从此,系统随后通过获得的汉密尔顿量完全表征。这些方法适用于高达 12 个量子比特的系统大小,但也可以采用更多的量子比特。使用伊辛模型和自旋玻璃的模拟数据,重建结果达到高保真度值,展示并强调了所提出算法的效率。

使用卷积神经网络
声音分类在当今世界的各个领域都有其用途。在本文中,我们将借助机器生成的声音数据来介绍声音分类技术,以检测故障机器。重点是确定音频分类方法的相关性,以通过声音检测有故障的电动机;在嘈杂和无噪声的情况下;因此,可以减少工厂和行业的人类检查要求。降低降噪在提高检测准确性方面起着重要的作用,一些研究人员通过为基准测试其模型而添加噪声来模拟数据。因此,降噪广泛用于音频分类任务。在各种可用方法中,我们实施了一种自动编码器来降低噪声。我们使用卷积神经网络对嘈杂和DeNo的数据进行了分类任务。使用自动编码器将分类的分类准确性与嘈杂的数据进行了比较。进行分类,我们使用了频谱图,MEL频率CEPSTRAL CO-EFIFIED(MFCC)和MEL光谱图图像。这些过程产生了令人鼓舞的结果,从而通过声音区分了故障的电动机。

表征相似性分析对计算神经科学模型选择和评估的评价
神经科学的一个重要目标是确定不同大脑区域代表哪些类型的信息。在研究大脑表征的一种策略中,研究人员首先记录大脑对不同刺激的反应。然后使用统计方法来评估刺激和大脑反应之间关系的强度。然后使用这些统计评估结果推断感兴趣区域中编码的表征空间。认知神经科学家可以使用许多统计技术。它们包括统计参数映射方法 [12]、多元模式分析 (MVPA) 技术 [4] 和编码模型 [16]。一种常见的 MVPA 分析类型是表征相似性分析 (RSA;[10])。RSA 之所以被广泛采用,部分原因是它计算简单。然而,迄今为止很少有研究探索 RSA 的有效性。 10 在本文中,我们使用模拟数据和真实数据来评估 RSA 作为模型评估和模型选择方法的有效性,更广泛地说,作为计算神经科学的工具。模型评估是指在刺激和反应之间存在显著关系时,检测刺激和反应之间显著关系的能力。