XiaoMi-AI文件搜索系统
World File Search System第三人称

航空/航天教育与研究杂志
学术共享引用 学术共享引用 Oh, C., Lee, K., & Oh, M. (2021). 使用连接的 VR-MR 系统集成第一人称视角和第三人称视角进行飞行员训练。航空/航天教育与研究杂志,30(1)。https://doi.org/10.15394/jaaer.2021.1851

在儿童玛尼亚展览中的实施和互动
13 Steur,“摄影游戏或肉体中的游戏:通过将摄影主题调整为视频播放的现象来抓住Celeste,”89。14黑色,“为什么我可以看到我的头像?在第三人称视频游戏中体现了视觉参与,”190。15克里克,“游戏主体:迈向当代视频游戏的现象学”,259。16 Sobchack,“屏幕的场景”,108。同上,93。18克里克,261。

使用深度学习神经网络进行手势识别...
图 3.1:手势识别图 ................................................................................................................ 45 图 3.2:ZTM 手套。 .......................................................................................................................... 46 图 3.3:带有多个传感器的 MIT Acceleglove。 ...................................................................................... 47 图 3.4:CyberGlove III .................................................................................................................... 48 图 3.5:CyberGlove II。 .................................................................................................................... 48 图 3.6:5DT 动作捕捉手套和传感器手套 Ultra。 左:当前版本,右:旧版本。[73][74]。 ............................................................................................................................. 49 图 3.7:X-IST 数据手套 ............................................................................................................. 50 图 3.8:P5 手套。 ........................................................................................................................... 50 图 3.9:典型的基于计算机视觉的手势识别方法 .......................................................................... 51 图 3.10:手势识别中使用的相机类型 .......................................................................................... 52 图 3.11:立体相机。 ...................................................................................................................... 52 图 3.12:深度感知相机 ...................................................................................................................... 53 图 3.13:热像仪 ...................................................................................................................... 53 图 3.14:基于控制器的手势 ............................................................................................................. 54 图 3.15:单相机。 ............................................................................................................................. 54 图 3.16:布鲁内尔大学 3DVJVANT 项目的全息 3D 相机原型...................................................... 55 图 3.17:3D 积分成像相机 PL:定焦镜头,MLA:微透镜阵列,RL:中继透镜。 ... 55 图 3.18:方形光圈 2 型相机与佳能 5.6k 传感器的集成。 ................................................ 56 图 5.1:不同的手势。 ...................................................................................................................... 70 图 5.2:系统实现的图解框架。 ............................................................................................. 71 图 5.3:使用 WT 的 10 种不同运动的 IMF。 ............................................................................. 75 图 5.4:使用 EMD 的 10 种不同运动的 IMF。 ........................................................................... 76 图 5.5:WT 中 10 个不同类别的 ROC。 ......................................................................................... 79 图 5.6:EMD 中 10 个不同类别的 ROC。 ......................................................................................... 80 图 5.7:研究中使用的手势。 ......................................................................................................... 84 图 5.8:实施框架。 ........................................................................................................... 84 图 5.9:使用 WT 的 10 种不同动作的 IMF。 ........................................................................... 87 图 5.10:使用 EMD 的 10 种不同动作的 IMF。 ........................................................................... 89 图 5.11:WT 中 10 个不同类别的 ROC。 ......................................................................................... 91 图 5.12:EMD 中 10 个不同类别的 ROC。 ........................................................................................... 92 图 6.1:拔牙前第一人称短距离手部动作 .............................................................................. 97 图 6.2:拔牙后第一人称短距离手部动作 .............................................................................. 99 图 6.3:拔牙后第一人称短距离手部动作 ............................................................................. 100 图 6.4:拔牙前第二人称短距离手部动作 ............................................................................. 101 图 6.5:拔牙后第二人称短距离单人手部动作(LCR) ............................................................. 103 图 6.6:拔牙后第二人称短距离组合手部动作(LCR) ............................................................................. 105 图 6.7:拔牙前第三人称短距离手部动作 ............................................................................. 105 图 6.8:拔牙后第三人称短距离单人手部动作(LCR) ............................................................................................................................................................. 107................................................................ 89 图 5.11:WT 中 10 个不同类别的 ROC。 .............................................................................. 91 图 5.12:EMD 中 10 个不同类别的 ROC。 ........................................................................................... 92 图 6.1:拔牙前第一人称短距离手部动作 .............................................................................. 97 图 6.2:拔牙后第一人称短距离手部动作 .............................................................................. 99 图 6.3:拔牙后第一人称短距离手部动作 ............................................................................. 100 图 6.4:拔牙前第二人称短距离手部动作 ............................................................................. 101 图 6.5:拔牙后第二人称短距离单人手部动作(LCR) ............................................................. 103 图 6.6:拔牙后第二人称短距离组合手部动作(LCR) ............................................................................. 105 图 6.7:拔牙前第三人称短距离手部动作 ............................................................................. 105 图 6.8:拔牙后第三人称短距离单人手部动作(LCR) ............................................................................................................................................................. 107................................................................ 89 图 5.11:WT 中 10 个不同类别的 ROC。 .............................................................................. 91 图 5.12:EMD 中 10 个不同类别的 ROC。 ........................................................................................... 92 图 6.1:拔牙前第一人称短距离手部动作 .............................................................................. 97 图 6.2:拔牙后第一人称短距离手部动作 .............................................................................. 99 图 6.3:拔牙后第一人称短距离手部动作 ............................................................................. 100 图 6.4:拔牙前第二人称短距离手部动作 ............................................................................. 101 图 6.5:拔牙后第二人称短距离单人手部动作(LCR) ............................................................. 103 图 6.6:拔牙后第二人称短距离组合手部动作(LCR) ............................................................................. 105 图 6.7:拔牙前第三人称短距离手部动作 ............................................................................. 105 图 6.8:拔牙后第三人称短距离单人手部动作(LCR) ............................................................................................................................................................. 107

基于以上为中心的视觉模型,基于便携式实时智能助手
图4。Egovideo-VL模型的概述。 eGovideo-VL是一种旨在实时自我中心的理解和援助的多模式视觉语言模型。 该模型包含五个关键组件:(1)遵循Egovideo [58]的设计模态编码器,并包括一个视频编码器和用于多模式特征提取的文本编码器; (2)存储模块,该模块存储历史上下文以实现时间基础,摘要和个性化互动; (3)大型语言模型(LLM),该模型执行多模式推理和响应生成; (4)生成模块,该模块综合了视觉动作预测,以指导用户完成任务; (5)检索模块,该模块检索第三人称专家演示以补充以自我为中心的理解。Egovideo-VL模型的概述。eGovideo-VL是一种旨在实时自我中心的理解和援助的多模式视觉语言模型。该模型包含五个关键组件:(1)遵循Egovideo [58]的设计模态编码器,并包括一个视频编码器和用于多模式特征提取的文本编码器; (2)存储模块,该模块存储历史上下文以实现时间基础,摘要和个性化互动; (3)大型语言模型(LLM),该模型执行多模式推理和响应生成; (4)生成模块,该模块综合了视觉动作预测,以指导用户完成任务; (5)检索模块,该模块检索第三人称专家演示以补充以自我为中心的理解。

360+X:一个庞大的多模式场景理解数据集
人类对世界的看法是由多种观点和方式塑造的。许多现有数据集从某个角度专注于场景理解(例如以中心的或第三人称的视图),我们的数据集提供了一个全景视角(即具有多种数据模式的多个观点)。具体而言,我们封装了第三人称全景和前视图,以及以富裕方式,包括视频,多频道音频,定向双耳延迟,位置数据数据和文本场景描述,在每个场景中,呈现世界的全面实现,呈现了全世界的全面实现。据我们所知,这是第一个涵盖具有多种数据模式的多个观点的数据库,以模仿现实世界中如何访问每日信息。 通过我们的基准分析,我们在建议的360+x数据集上介绍了5个不同的场景理解任务,以评估综合场景理解中每种数据模式和观点的影响和好处。 我们希望这个独特的数据集能够扩大理解场景的范围,并鼓励社区从更多样化的角度解决这些问题。据我们所知,这是第一个涵盖具有多种数据模式的多个观点的数据库,以模仿现实世界中如何访问每日信息。通过我们的基准分析,我们在建议的360+x数据集上介绍了5个不同的场景理解任务,以评估综合场景理解中每种数据模式和观点的影响和好处。我们希望这个独特的数据集能够扩大理解场景的范围,并鼓励社区从更多样化的角度解决这些问题。

Taser Energy武器
成员不需要在使用或威胁要对其或第三人称使用致命的物理力量的情况下使用Taser Energy武器。Taser Energy武器不能取代成员枪支,除非是唯一可用的选择,否则不应在致命的物理武力情况下单独使用。在致命的身体部队情况下,成员只应在其他成员出席时才使用Taser Energy武器,并通过部门发行的手枪,shot弹枪或步枪提供致命的掩护。在考虑使用致命覆盖物的致命物理武力情况下使用TASER能量武器时可能会考虑的因素包括但不限于:

观察机器人排斥对儿童的效率...
关于机器人排斥的研究仍然很少,并且仅探索了其对成年人种群的效果。尽管结果揭示了机器人排除的属性结转效果,但尚无证据表明这些结果发生在儿童机器人相互作用中。本文首先提供了对儿童机器人排斥的探索。,我们以第三人称视角使用了机器人网络范式进行了一项研究,其中52名FVE年龄在10岁之间的儿童样本。实验研究有两个条件:排除和包容。在排除条件下,儿童观察到一个同伴被两个机器人排除在外。在包含条件下,观察到的对等与机器人平均相互作用。值得注意的是,即使是5岁的孩子,当机器人排除另一个机器人

儿童和青少年心理治疗师
• 想象最坏的情况无法改变不想要的情况,但有时可以改变青少年对这种情况的看法。 • 不要专注于帮助青少年对情况感到高兴,而是帮助他们更加现实地对待情况。 • 培养冷静观察感受的能力:采取注意感受但不参与其中的视角会有所帮助。 • 听音乐的沉浸式情感体验已被发现可以加速青少年走出负面情绪的另一面。 • 帮助青少年从第三人称视角观察情况可以减轻痛苦,让他们更理性地思考挑战。 • 把他们的名字放在他们对自己提出的任何批评前面,事实证明我们对自己更好,我们这样做,“我太蠢了”比“索菲亚,你太蠢了”更容易说。 • 帮助青少年拉开距离也很有用。 “你认为未来你会如何评价你现在正在经历的事情?”如何帮助不愿意说话的青少年
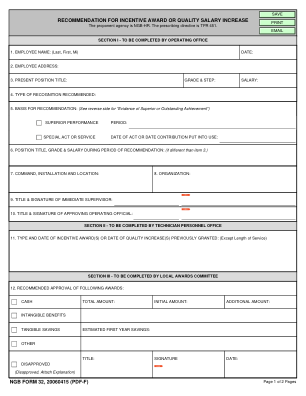
NGB 表格 32,20060415 (PDF-F)
1. 附上主要职责说明和推荐所依据职位的职位描述副本。 2. 附上推荐信的详细具体事实陈述。这必须是对员工实际绩效的性质和优点的事实陈述,并表明其如何超出员工职位的正常绩效要求。指出绩效带来的收益以及特殊行为或服务的重要性。如果成就在行动中产生了有形收益,请提供此类收益的详细计算和分析。 3. 如果不适用有形收益,请说明无形收益的相对重要性类型。还要说明成就对指挥部的重要性。 4. 如果推荐荣誉奖,请附上拟议的嘉奖草稿,以第三人称书写,字数不超过 70 字。使用 8 X 10 1/2 英寸的纸张。

人工智能聊天机器人有写作风格吗?...
摘要:尽管 Turnitin 可以生成 AI(人工智能)写作检测报告,但这些 AI 报告不得用于惩罚目的,因为本研究表明,Turnitin AI 报告的准确率远低于 Turnitin 声称的 98%。为了帮助教授、教师和内容评估利益相关者识别 AI 生成的材料,本研究通过探索句子长度、段落结构、词汇选择、情绪、时态、语态、代词、关键词密度、词汇密度、词汇多样性和阅读难易程度,研究了案例研究、商业信函和学术写作 ChatGPT-4 生成的回复的文体特征。研究表明,ChatGPT-4 案例研究生成的回复以 2 到 3 个句子的段落形式生成,每个句子有 16 到 18 个单词。这些句子主要以祈使语气形成。第二人称代词“你”和第二人称所有格限定词“你的”的使用很普遍。关键词和词汇密度较低,词汇多样性一般,阅读难易度较高。研究还发现,ChatGPT-4商务信函回复以2-3句16-20词的段落形式生成。句子主要以陈述语气生成,使用一般现在时和主动语态,使用第三人称单数代词。使用技术词汇和缩写时没有说明其含义。关键词密度、词汇密度和词汇多样性较高,阅读难易度较低。研究还发现,ChatGPT-4学术写作回复以3-4句16-19词的段落形式生成。句子主要以陈述语气生成,使用主动语态,时间上无主体被动语态,使用多种现在时态。关键词和词汇密度较高,词汇多样性较低,因此阅读难度处于平均水平(未定义缩写除外)。值得注意的是,ChatGPT-4 有意使用第三人称复数代词“they”来指代单数,以支持跨性别运动。