XiaoMi-AI文件搜索系统
World File Search System线性回归

储能报告2024年2月
➢当预测的IB(feed)价格(feed)价格在下一个小时的下降(上述)较低(上)近期IB(Feed)价格(feed)价格时,被动不平衡交易策略就会产生一个短(或长)的职位。阈值是为每个市场独立定义的,以最大化收入。基于历史不平衡和盘中价格的多线性回归用于产生不平衡价格预测。被动不平衡交易的收入是根据实际不平衡价格的失衡计算的

CS184A/284A 生物和医学中的人工智能
● 简介。课程框架 ● 最近邻方法、线性回归 ● 感知器、逻辑回归、支持向量机、决策树 ● 应用 1:基因表达分析、生物标志物发现、精准医疗 ● 无监督学习、主成分分析、聚类 ● 应用 2:单细胞 RNA-seq 分析、其他基因组应用 ● 概率模型、马尔可夫模型、EM 算法 ● 应用 3:基因发现、调控基序发现、CpG 岛 ● 神经网络、深度学习 ● 应用 4:生物医学图像分析
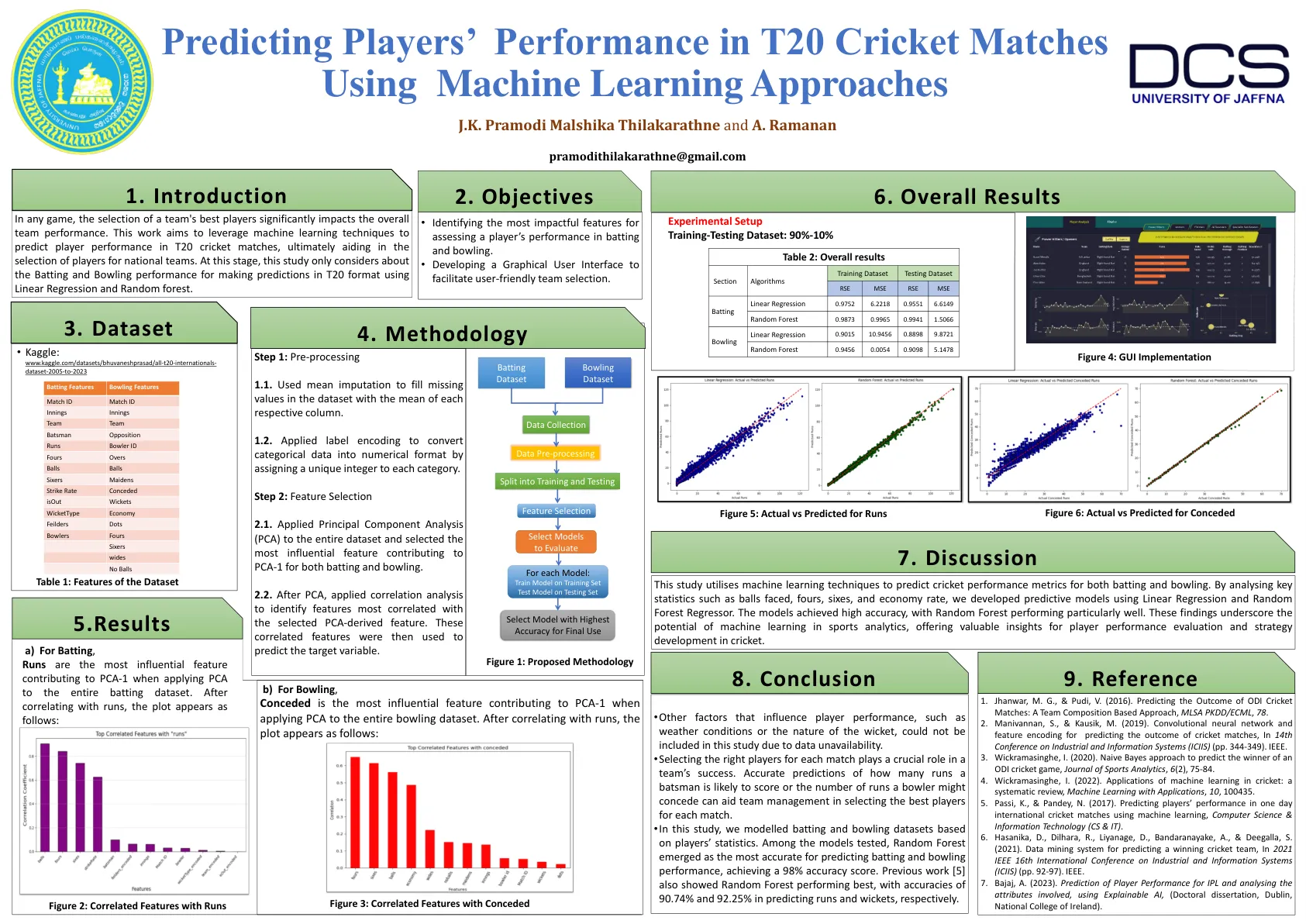
预测玩家在T20板球比赛中的表现...
这项研究利用机器学习技术来预测击球和保龄球的板球性能指标。通过分析关键统计数据,例如面对球,四分,六和经济速率,我们使用线性回归和随机森林回归制定了预测模型。模型达到了高精度,随机森林的性能特别出色。这些发现强调了运动分析中机器学习的潜力,为球员绩效评估和板球战略制定提供了宝贵的见解。

使用机器学习的房屋价格预测-IJRPR
机器学习模型,例如线性回归,随机森林,梯度提升和SVM,对房价预测有效。回归技术捕获特征关系,而高级方法处理复杂的模式。预处理和功能工程可显着提高模型性能。将算法结合到整体方法中可确保可靠的预测和适应性。全面的数据集和用户友好的接口改善了实用性。此策略为房地产估值提供了准确的见解,并支持利益相关者的知情决策。

慢性淋巴细胞白血病:2022 年诊断和治疗程序更新
4. 进行性淋巴细胞增多,2 个月内增多≥50%,或淋巴细胞倍增时间(LDT)小于 6 个月。LDT 可通过在 2-3 个月的观察期内每隔 2 周获得的绝对淋巴细胞计数(ALC)的线性回归外推获得;初始血液淋巴细胞计数<30 000/μL 的患者可能需要更长的观察期来确定 LDT。应排除除慢性淋巴细胞白血病之外的其他导致淋巴细胞增多的因素(例如感染、类固醇给药)
![人工智能与机器学习 [R20A0566] 讲义](/simg/b\b769bf1f3708ae9e757fd53b21477151fccb345d.png)
人工智能与机器学习 [R20A0566] 讲义
提供对各种机器学习算法的理解以及评估 ML 算法性能的方法 UNIT - I:简介:人工智能问题、代理和环境、代理结构、问题解决代理基本搜索策略:问题空间、无信息搜索(广度优先、深度优先搜索、深度优先与迭代深化)、启发式搜索(爬山法、通用最佳优先、A*)、约束满足(回溯、局部搜索) UNIT - II:高级搜索:构建搜索树、随机搜索、AO* 搜索实现、极小极大搜索、Alpha-Beta 剪枝基本知识表示和推理:命题逻辑、一阶逻辑、前向链接和后向链接、概率推理简介、贝叶斯定理 UNIT - III:机器学习:简介。机器学习系统,学习形式:监督学习和非监督学习,强化学习 – 学习理论 – 学习的可行性 – 数据准备 – 训练与测试和拆分。第四单元:监督学习:回归:线性回归、多元线性回归、多项式回归、逻辑回归、非线性回归、模型评估方法。分类:支持向量机 (SVM)、朴素贝叶斯分类第五单元:无监督学习最近邻模型 – K 均值 – 围绕中心点聚类 – 轮廓 – 层次聚类 – kd 树、聚类树 – 学习有序规则列表 – 学习无序规则。强化学习 – 示例:迷路 – 状态和动作空间

课程结构 M.Tech.(ECE)
第 2 单元监督机器学习回归(线性回归、岭回归、回归树、非线性回归、贝叶斯线性回归、多项式回归、套索回归、梯度下降)分类(随机森林、决策树、逻辑回归、朴素贝叶斯分类器、多类分类)最大似然估计、正则化/ MAP、软/硬边距 SVM、SVM 对偶组件 2 第 3 单元无监督机器学习聚类(K 均值聚类(软/硬)、KNN(k 最近邻)、层次聚类、异常检测、神经网络、主成分分析、独立成分分析、先验算法、后验算法、奇异值分解)关联(隐马尔可夫模型、高斯混合模型、高斯混合模型-通用背景模型、联合因子分析、i-向量、i-向量/PLDA 方法)第 4 单元强化机器学习 强化学习概述、学习任务、Q 学习、非确定性 Q 学习、时间差分学习、RL-General 公式、多臂赌博机、马尔可夫决策过程和深度强化学习 6. 教科书和参考文献: 1. 《模式识别与机器学习》,Bishop 编著,Springer,2006 年。 2. 《机器学习:概率视角》,Kevin P. Murphy 编著,麻省理工学院出版社,2012 年 3. 《统计学习要素》,第二版,Hastie、Tibshirani 和 Friedman 编著,Springer-Verlag,

大规模水文模型和跨界河流
摘要:大规模的水文建模是河流水文学中的一种新兴方法,尤其是在有限的可用数据的地区。这项研究重点是评估希腊五个跨界河流的两个知名大规模水文模型,即电子型和lisflood的性能。为此,将两种模型的河流插座上的排放时间序列与观察到的数据集进行了比较。比较是使用确定的确定系数,偏差百分比,nash – utcliffe效率,根平方误差和kling-gupta效率进行比较。随后,水文模型的时间序列分别通过缩放因子,线性回归,增量变化和分数映射方法纠正。然后使用相同的统计措施重新评估输出对观测值进行重新评估。结果表明,两个大规模的水文模型都没有持续优于另一个模型,因为一个模型在某些盆地中的表现更好,而另一个模型在其余情况下表现出色。偏差校正过程将线性回归和分位数映射确定为案例研究盆地最合适的方法。此外,该研究还评估了上游水域对河流预算的影响。该研究强调了大型模型在跨界水文学中的重要性,它在全球范围内对其在任何河流盆地中的适用性提出了一种方法论方法,并强调了产出在国际水域合作管理中的有用性。

