XiaoMi-AI文件搜索系统
World File Search System线搜索

算法思维-Comp 182
Comp 182中的家庭作业和考试都是根据《赖斯荣誉法》条款作为承诺任务进行的。Comp 182中的考试是保证,您必须自己完成的时间限制任务。每次考试将对允许的任何资源都有明确的声明。不允许其他资源。关于作业,您可以与其他学生以及课程人员在高水平上讨论它们。这些讨论应仅限于理解问题并讨论解决方案的高级方法。您提交的工作必须是您自己的解决方案的综合。您无法从其他人那里获得详细的解决方案,也无法将其作为您自己的工作提交。如果您阅读书籍,在线站点或其他资源作为做作业过程的一部分,则必须明确引用它们。您不应在线搜索家庭作业解决方案。您不应向其他人提供解决方案的访问。您不应使用本课程早期版本中生成的解决方案(无论是来自讲师还是来自学生)。您不应将解决方案发布到公共领域(包括诸如Github之类的地方)。

西雅图,1月8日至11日,2025年第1203次会议的摘要
Victor H Moll*。整体故事:一些意外的连接。在学习演算过程中,人们观察到有一个明确定义的计算衍生品的规则列表:产品,商和链条规则是每个班级中首次教授的规则。另一方面,当一个人试图计算积分时,学生就会感觉到现在只有一系列技巧。没有明确的理由是,为什么可以集成$ e^{x} $是一种简单的方式,但是$ e^{x^{2}} $的积分更为复杂。通过与老年同学交谈或在线搜索它们,从讲师那里学习了这些技巧。最后,似乎没有系统的方式。值得注意的是,在寻找产生确定积分的封闭形式时,人们发现了许多有趣的连接与数学的显而易见部分。示例将包括$(1)$属性的属性,这些正整数集合出现在评估合理函数中,$(2)$一个与算术算法平均值变化相连的平面动力学系统和$(3)$涉及涉及γ功能的确定积分列表。演讲将适合本科生,其中包括有关演讲者如何参与此类项目的故事。(2024年2月7日收到)

哲学在尼日利亚可持续发展中的作用
哲学是每个国家实现全面转型和可持续发展的真正工具。作为一门对人类存在进行批判性和严格研究的学科,它有以下分支:认识论,研究人类知识的性质、来源和有效性;形而上学,研究存在或现实的本质;逻辑学,研究区分正确和错误推理或正确和错误论证的规则;伦理学,研究道德问题或对是非的判断;美学,研究对美和艺术作品的评价。因此,它涵盖了人类努力的各个方面,这些努力促进了社会的人类和可持续发展。然而,本研究采用了分析说明方法,数据来源于书籍、访谈和在线搜索引擎。因此,本研究发现,在尼日利亚,哲学作为一门学科仍然毫无价值,被贬低到学生不再接受它作为大学的一个学术研究领域的程度。忽视哲学导致了国家经济战略和发展步伐的停滞。因此,我们建议,为了更好地促进经济发展,哲学学科应该进行修改和重新战略化,并让学生重新认识哲学在我国的价值、需求和作用。

定量潮流
潮流已成为识别和跟踪消费者兴趣和行为的一般趋势的重要营销智能工具。目前,趋势范围是由趋势猎人进行定性进行的,他们在日常生活中梳理,以寻找表明消费者需求和需求的重大变化,或者是由分析师定量地转移的,分析师监视了单个指标,例如已经搜索,博客或在线搜索了一个关键字的次数。在这项研究中,作者证明了如何通过发现隐藏在大量指标的共同进化后面的常见轨迹来改善后者。作者提出了一个结构性动力学因子分析模型,该模型可用于同时分析数十个甚至数百个时间序列,将它们蒸馏成几个关键的潜在动态因子,从而将季节性循环运动分离出季节性的循环运动,使其与非季节的非组织趋势线分离。作者展示了一种新型的多元方法,用于在一个应用程序中进行定量趋势介绍,涉及有希望的新的营销智能来源 - 从Google的搜索搜索中的关键字搜索数据中的搜索中的关键字搜索数据 - 在他们分析了38个主要车辆的搜索量模式,以在81个月的时间内实现81个月的轻型车辆,以发现消费者汽车购物的关键趋势。

引用:Boujarzadeh B,Ranjbar A,Banihashemi F等。预测产后出血的机器学习方法:系统的审查协议。
摘要引言产后出血(PPH)是分娩的最严重的临床问题,它在全球范围内对孕产妇死亡产生了重大贡献。该系统评价旨在根据机器学习(ML)方法来识别PPH的预测因子。方法和分析本评论遵守了系统评价和荟萃分析协议的首选报告项目的指南。该评论定于2023年1月10日开始,并于2023年3月20日结束。主要目的是识别和总结与PPH相关的预测因素,并提出基于ML的预测算法。从成立到2022年12月,将对经过同行评审的期刊文章和在线搜索记录进行以下电子数据库的系统搜索:Cochrane Central Register,PubMed,Embase,Embase(通过OVID),Scopus,Wos,Wos,Ieee Xplore,IEEE Xplore和Google Scholar搜索引擎。将考虑所有符合以下标准的研究:(1)它们包括对PPH诊断的明确定义的一般人群; (2)它们包括用于预测PPH的ML模型,并清楚地描述了ML模型; (3)他们证明了具有指标的ML模型的性能,包括接收器操作特征曲线下的区域,准确性,精度,灵敏度和特异性。非英语语言论文将被排除在外。数据提取将由两个研究者独立执行。总共包括20个信号,将用作评估每个纳入研究的偏见和适用性的工具。道德和传播道德批准不需要,因为我们的审查将包括已发布和公开访问的数据。本评论中的发现将通过同行评审期刊中的出版物传播。Prospero注册号本审查的协议在Prospero提交,ID编号CRD42022354896。

代理问:自主AI代理的高级推理和学习
大语言模型(LLM)在需要复杂推理的自然语言任务中表现出了显着的功能,但是它们在交互式环境中的代理,多步骤推理中的应用仍然是一个艰难的挑战。静态数据集上的传统监督预训练在实现在Web Navigation(例如Web Navigation)中执行复杂决策所需的自主代理能力时跌落。先前试图通过对精选的专家演示进行微调的微调来弥合这一差距 - 通常会遭受更复杂的错误和有限的勘探数据,从而导致了次优政策的结果。为了克服这些挑战,我们提出了一个框架,将带有指导的蒙特卡洛树搜索(MCTS)搜索与自我批评机制和使用直接优先优化(DPO)算法的非政策变体对代理相互作用进行迭代微调。我们的方法使LLM代理可以从成功和失败的轨迹中有效学习,从而改善其在复杂的多步推理任务中的概括。我们在网络商店环境(一个模拟的电子商务平台)中验证了我们的方法,在该平台上,它始终超过行为的克隆和加强基线,并在配备了进行在线搜索的能力时击败平均人类绩效。在实际预订方案中,我们的方法论将Llama-3 70B型号的零拍摄性能从18.6%升至81.7%的成功率(相对增长340%),经过一天的数据收集,并在线搜索中进一步增加到95.4%。我们认为,这代表了自主代理人能力的实质性飞跃,为在现实世界中更复杂和可靠的决策铺平了道路。

2023 年威斯康星州综合规划和地方土地法规清单报告
• 链接到当地政府的法令网页(如果有) 综合规划旨在作为当地政府在物质、社会和经济发展方面的指南。理想情况下,综合规划为土地法规提供了合理的基础,并为当地房地产市场提供了一定的可预测性。威斯康星州的《综合规划法》(第 66.1001 条)定义了综合规划的内容,其中包括 20 年愿景和未来土地使用地图。《综合规划法》实施的关键是一致性要求——要求当地政府的综合规划与其分区、细分(土地划分)和官方制图法令的变化保持一致。例如,如果一个拥有过时规划的地方政府想要重新划分土地,它必须首先通过公共规划流程来更新其综合规划,这可能是一个耗时的过程。如果地方政府在没有更新综合规划的情况下继续进行,公民或组织可以提起诉讼以使其行动无效,因为它与有效的综合规划缺乏一致性。综合规划必须至少每 10 年更新一次。清单分析发现,大多数综合计划在过去 10 年中没有得到全面更新或修改,因此现在已经过时。对于许多不执行市政土地法规的小村庄和乡镇来说,这可能无关紧要。然而,479 个地方政府执行自己的分区或细分法规,而没有采用当前的综合计划。在盘点分区和细分法令的过程中,寻找并在线搜索托管法令的网页。结果发现,虽然较大的地方政府通常使用 Municode 或 eCode360 等常见平台以易于搜索的方式在线发布法令,但大约 39% 的地方政府没有网站或似乎没有在其网站上发布完整的法令列表。在某些情况下,即使法令存在于网上,它们也会以低分辨率扫描或未加标签的不可搜索的 PDF 形式发布。当地法律无法在线访问,这与威斯康星州法律形成鲜明对比,威斯康星州法律完全可以通过法规编号或关键字进行搜索。本报告中提供的统计数据基于 2023 年 6 月 13 日的综合规划和土地法规清单。清单电子表格旨在成为一张动态表格,并将随着地方政府更新其综合计划、采用新的土地法规或创建法令网页而不断发展。请将综合计划的采用通知威斯康星州行政部 (DOA)。如有任何意见或更正,请发送电子邮件至 comp.planning@wisconsin.gov 或致电 608-267-3369。_

惊奇与恐惧:基于人工智能的自然语言生成对写作教学的影响 Chris M. Anson 北卡罗来纳州立大学
惊讶与惶恐:基于人工智能的自然语言生成对写作教学的影响 Chris M. Anson 美国北卡罗来纳州立大学 Ingerid S. Straume 挪威奥斯陆大学 摘要 基于人工智能的自然语言生成系统目前能够在极少的人为干预下生成独特的文本。 由于这类系统的改进速度非常快,如果教师期望学生自己写作——参与产生和组织想法、研究主题、起草连贯的文章,并利用反馈进行原则性修改等复杂过程,这些修改既能提高文本质量,又能帮助他们成长为作家——那么他们将面临这样的前景:学生可以使用这些系统生成看起来像人类的文本,而无需参与这些过程。 在本文中,我们首先描述基于人工智能的自然语言生成系统(如 GPT-3)的性质和功能,然后就教师如何应对系统日益改进及其对学生的可用性所带来的挑战提出一些建议。简介 教育工作者长期以来一直担心新技术的进步会颠覆学生的学习过程——这种担忧在电子计算器出现后的几十年里一直存在于数学教师中(见 Banks,2011)。互联网的出现首先引发了学生对资料来源使用的偏执,因为只需点击几下鼠标,就可以获得大量信息,而且复制粘贴成为学生在不注明出处的情况下将他人的文字拼接到自己的文章中的一种简单方法。文本可以在屏幕上进行操作以达到所需的长度(例如,通过不知不觉地增加逗号和句号的字体大小或更改字符宽度)。精通技术的学生很快就能通过用系统无法识别的西里尔字体替换看起来相同的字母、在行末添加不可见的单词(白色字体)或添加虚构的参考资料来欺骗抄袭检测工具。手机使人们能够通过发短信、存储信息或在线搜索在课堂考试中作弊。论文写作服务在互联网上蓬勃发展。与此同时,更复杂的翻译程序继续困扰着外语教师和那些与 L2 学生一起工作的人(Karbach,2020 年)。然而,与基于人工智能的语言生成技术的潜力相比,这些偷偷摸摸的逃避将显得微不足道:系统可以自动生成与人类书写完全或几乎完全一样的文字。这种下一代自然语言处理技术为写作教育者提出了关键问题。在本文中,我们首先简要描述了 GPT-3 等能够生成、总结、组织和翻译自然语言文本的人工智能系统的发展,并提供了一些这些系统功能的示例,既有帮助又令人不安。然后,我们讨论这些系统对学术写作教学的影响,在这些系统中,它们将越来越普及,并可供学生使用。

数值优化
3行搜索方法30 3.1步长。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。31沃尔夫条件。。。。。。。。。。。。。。。。。。。。。。。。。。。33戈德斯坦条件。。。。。。。。。。。。。。。。。。。。。。。。。36足够的减少和回溯。。。。。。。。。。。。。。。。。。。37 3.2线路搜索方法的收敛性。。。。。。。。。。。。。。。。。。。37 3.3收敛速率。。。。。。。。。。。。。。。。。。。。。。。。。。。。41最陡下降的收敛速率。。。。。。。。。。。。。。。。。。。42牛顿的方法。。。。。。。。。。。。。。。。。。。。。。。。。。。。。44个准Newton方法。。。。。。。。。。。。。。。。。。。。。。。。。。46 3.4 Hessian修饰的牛顿方法。。。。。。。。。。。。。。。48特征值修改。。。。。。。。。。。。。。。。。。。。。。。。。。49添加一个身份的倍数。。。。。。。。。。。。。。。。。。。。。51修改的cholesky分解。。。。。。。。。。。。。。。。。。。。。52修改对称的不合格分解。。。。。。。。。。。。。。。54 3.5步长选择算法。。。。。。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>6插值。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>57初始步长。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>59和wolfe条件的线搜索年龄。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>60个注释和参考。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>62个练习。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 。 div> 63 div>62个练习。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>63 div>
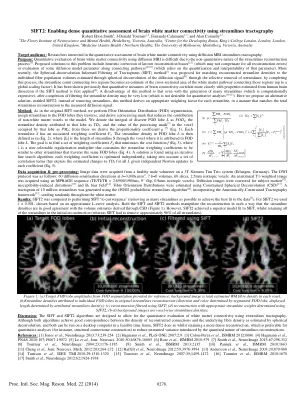
SIFT2:利用流线纤维束成像技术对大脑白质连接进行密集定量评估
目标受众:对使用扩散 MRI 流线纤维束成像定量评估大脑白质连接感兴趣的研究人员。目的:由于流线重建过程的非定量性质 [1],使用扩散 MRI 定量评估大脑白质连接非常困难。针对该问题提出的解决方案包括启发式校正已知的重建偏差 [2,3](可能无法补偿所有重建误差)或评估连接路径上某些扩散模型参数 [4,5,6](依赖于该参数的量化和可解释性)。最近,提出了球面反卷积信息纤维束成像滤波 (SIFT) 方法 [7],通过选择性去除流线,将重建的流线密度与通过扩散信号球面反卷积估计的单个纤维群体积 [8] 进行匹配;完成此过程后,连接两个区域的流线计数变为连接这些区域的白质通路横截面积的估计值(最高可达全局缩放因子)。之前已证明,如果首先应用 SIFT 方法 [9],大脑连接的定量测量与从人脑解剖估计的特性会更加密切相关。这种方法的缺点是,即使生成了许多流线(计算成本高昂),完成过滤后,流线密度可能非常低(这对于定量分析来说是不可取的 [10,11])。在这里,我们提出了一种替代解决方案,称为 SIFT2:此方法不是去除流线,而是为每条流线得出合适的加权因子,以使总流线重建与测量的扩散信号相匹配。方法:与原始 SIFT 方法一样,我们执行纤维方向分布 (FOD) 分割,将流线分配给它们穿过的 FOD 叶,并得出一个处理掩模,以减少非白质体素对模型的贡献。我们将离散 FOD 叶 L 的积分表示为 FOD L ,将归因于该叶的流线密度表示为 TD L ,将处理掩模 [7] 在该叶所占体素中的值表示为 PM L ;从这些中我们得出比例系数 μ [7](等式 1)。每条流线 S 都有一个关联的加权系数 FS 。FOD 叶 L 中的流线密度定义为(等式 2),其中 | SL | 是流线 S 穿过归因于 FOD 叶 L 的体素的长度。目标是找到一组加权系数 FS ,以最小化成本函数 f(等式 3),其中 λ 是用户可选择的正则化乘数,它将流线加权系数约束为与穿过相同 FOD 叶的其他流线相似(等式 4)。使用迭代线搜索算法可以找到解决方案:每个加权系数都经过独立优化,同时考虑一组相关项,这些相关项表示在对每个系数进行独立牛顿更新的情况下所有 L 的 TD L 的估计变化(等式 5)。数据采集和预处理:图像数据是从健康男性志愿者的 3T Siemens Tim Trio 系统(德国埃尔朗根)上采集的。DWI 协议如下:60 个弥散敏化方向,b =3,000s.mm -2,7 b =0 体积,60 个切片,2.5mm 各向同性体素。使用 MPRAGE 序列(TE/TI/TR = 2.6/900/1900ms,9° 翻转,0.9mm 各向同性体素)获取解剖 T1 加权图像。对弥散图像进行了校正以适应受试者运动 [12]、磁化率引起的扭曲 [13] 和 B 1 偏置场 [14]。使用约束球面反卷积 (CSD) [15] 估计纤维取向分布。使用 iFOD2 概率流线算法 [16] 生成了 1000 万条流线的纤维束图,该算法结合了解剖约束纤维束成像框架 [17] ,随机分布在整个白质中。结果:将 SIFT2 与执行 SIFT“收敛”(移除尽可能多的流线以实现与数据的最佳拟合 [7] )进行了比较。对于 SIFT2,我们使用了 λ = 0.001,这是基于近似 L 曲线分析选择的。SIFT 和 SIFT2 方法都以这样一种方式操纵重建,使得流线密度与通过 CSD 得出的体积估计值高度一致(图 1)。然而,SIFT2 实现了比 SIFT 更优秀的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须去除大约 96% 的流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。