XiaoMi-AI文件搜索系统
World File Search System缩放


缩放澳大利亚的大气重新分析
气象局建议,本出版物中包含的信息包括基于科学研究的一般陈述。建议读者,需要意识到在任何特定情况下可能不完整或无法使用此类信息。因此,在不寻求先前的专业专业,科学和技术建议的情况下,必须对该信息做出任何依赖或行动。在法律和气象局允许的范围内(包括其每个员工和顾问),对任何后果的所有责任都排除了所有责任,包括但不限于所有损失,损害,成本,费用和任何其他赔偿,直接或间接地引起,而不是使用此出版物(部分或总而言之)以及所包含的任何信息,以及所包含的任何信息。
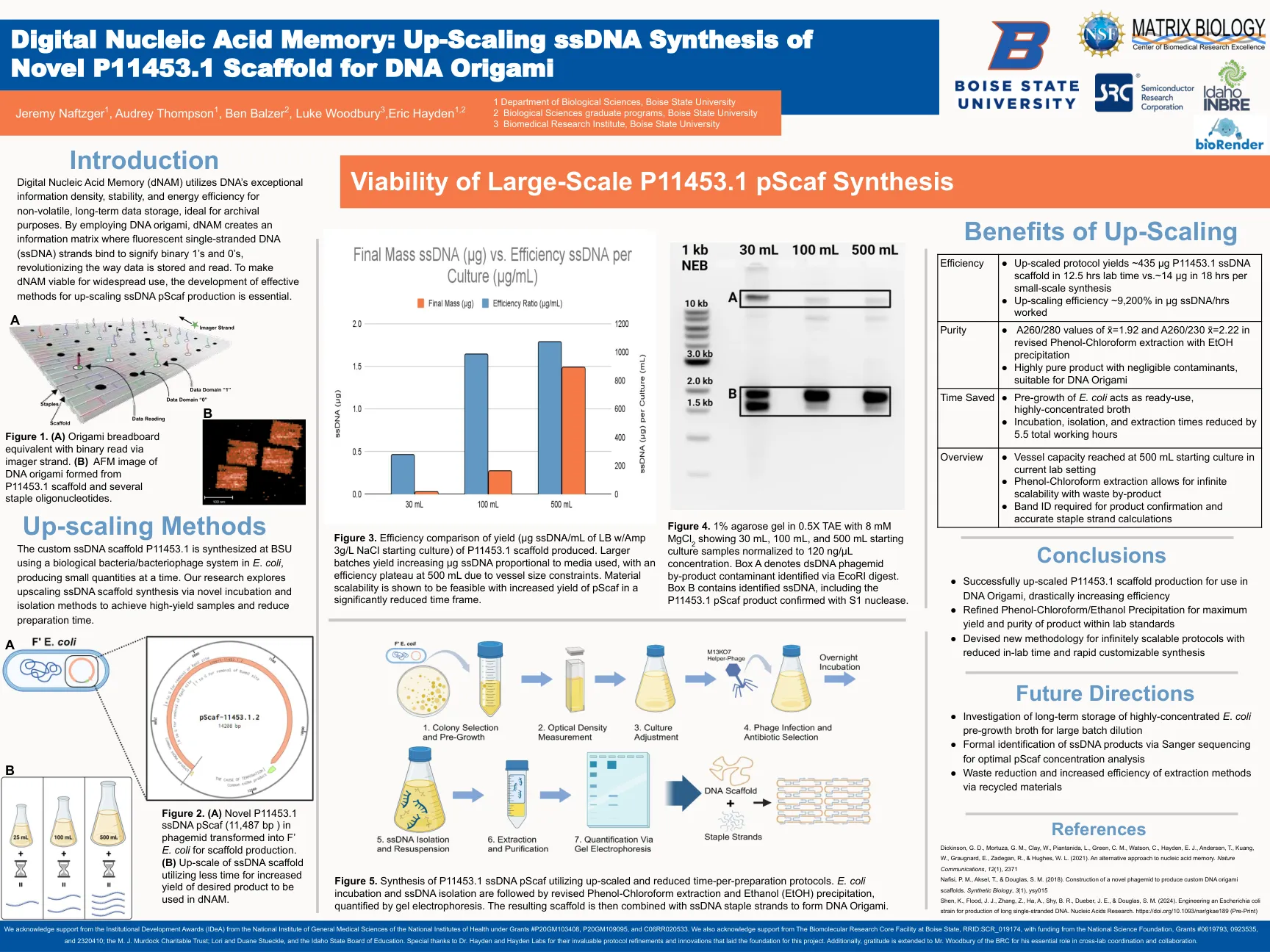
数字核酸记忆:新型P11453.1 DNA折纸的脚手架的缩放ssDNA合成
数字核酸记忆(DNAM)利用DNA的非挥发性,长期数据存储的DNA的特殊信息密度,稳定性和能源效率,非常适合档案目的。通过使用DNA折纸,DNAN创建了一个信息矩阵,其中荧光单链DNA(SSDNA)链结合以表示二进制1和0,从而革新了数据存储和读取的方式。使DNAM适用于广泛使用,开发了提高SSDNA PSCAF生产的有效方法是必不可少的。

在人工智能时代将缩放到1,000层3D NAND -MEDISEROMER
3D NAND垂直堆栈缩放缩放量主要是在膜沉积和蚀刻方面引起的挑战,这与设备通过功能尺寸减小进行缩放不同。与图案,隔离并连接垂直集成的3D存储器设备,需要难以高纵横比(HAR)蚀刻。通常将孔或沟槽的纵横比定义为深度与孔或沟槽宽度的比率。3D NAND制造中的关键过程包括替代堆栈膜沉积,高纵横比蚀刻和文字线金属化。找到位密度,读写速度,功率,可靠性和成本之间的平衡对于应用至关重要。当我们在结构中添加更多层,并且还有额外的资本支出,随着层的数量增加,增加更多的存储容量变得越来越昂贵。
将扩散模型缩放到现实世界3D激光雷达场景完成
计算机视觉技术在自动驾驶汽车的感知堆栈中起着核心作用。使用此类方法来感知给定数据的车辆周围环境。3D激光雷达传感器通常用于从场景中收集稀疏的3D点云。然而,根据人类的看法,这种系统努力鉴于那些稀疏的点云,因此很难塑造现场的看不见的部分。在此问题中,场景完成任务旨在预测LiDAR测量中的差距,以实现更完整的场景表示。鉴于最近扩散模型作为图像的生成模型的有希望的结果,我们建议将其扩展以实现单个3D LIDAR扫描的场景。以前的作品使用了从LiDAR数据提取的范围图像上使用扩散模型,直接应用了基于图像的扩散方法。差不多,我们建议直接在这些点上操作,并介绍尖锐的和降解的扩散过程,以便它可以在场景规模上有效地工作。与我们的方法一起,我们提出了正规化损失,以稳定在denoising过程中预测的噪声。我们的实验评估表明,我们的方法可以在单个LIDAR扫描中完成场景,作为输入,与最新场景完成方法相比,产生了更多详细信息的场景。我们认为,我们提出的扩散过程公式可以支持应用于场景尺度点云数据的扩散模型中的进一步研究。1

基于磁隧道结换能器的缩放多数逻辑合成自旋电子电路的基准测试
摘要 — 自旋电子逻辑器件最终将用于混合 CMOS-自旋电子系统,该系统通过传感器在磁场和电域之间进行信号相互转换。这强调了传感器在影响此类混合系统整体性能方面的重要作用。本文探讨了以下问题:基于磁隧道结 (MTJ) 传感器的自旋电子电路能否胜过其最先进的 CMOS 同类电路?为此,我们使用 EPFL(洛桑联邦理工学院)组合基准集,在 7 nm CMOS 和基于 MTJ 传感器的自旋电子技术中合成它们,并在能量延迟积 (EDP) 方面比较这两种实现方法。为了充分利用这些技术的潜力,CMOS 和自旋电子实现分别建立在标准布尔门和多数门之上。对于自旋电子电路,我们假设域转换(电/磁到磁/电)是通过 MTJ 执行的,计算是通过基于域壁 (DW) 的多数门完成的,并考虑了两种 EDP 估计方案:(i) 统一基准测试,忽略电路的内部结构,仅将域传感器的功率和延迟贡献纳入计算,以及 (ii) 多数-反相器-图基准测试,还嵌入了电路结构、相关关键路径延迟和 DW 传播的能量消耗。我们的结果表明,对于统一情况,自旋电子路线更适合实现具有少量输入和输出的复杂电路。另一方面,当也通过多数和反相器综合考虑电路结构时,我们的分析清楚地表明,为了匹配并最终超越 CMOS 性能,MTJ 传感器的效率必须提高 3-4 个数量级

大型飞机的缩放氢 - 电推进| ...
受控的煮沸管理是一个关键挑战。船上的低温坦克需要在飞机不运行的情况下最大程度地减少沸腾的时间。在飞行的所有阶段中,提取的氢气需要应对由燃料电池系统本身和周围环境引起的热流引起的储罐内的沸腾。如果无法实现这一目标,则存储系统将需要主动冷却系统或增强的绝缘材料,均增加重量。最关键的时期将是在飞行前后的地面上持有时间,这些时间可以确定存储系统的设计要求。

b'o一个书面叙述,详细介绍了请求,业务/使用操作信息,未来开发计划,站点和建筑改进,暂定开发时间表以及估计的项目价值。 o可能适用的缩放图纸,包括但不限于;现场计划,评分/侵蚀控制计划,初步的雨水管理计划,景观计划,照明计划,建筑物高程,有色效果图,标志细节和自然资源描述。所有以数字格式(Adobe PDF)提供的应用材料。材料可以在USB闪存驱动器上提交,也可以通过电子邮件发送至hurd@pewaukee.wi.us。注意十二(12)个计划委员会将需要进行十二(12)个计划委员会的其他计划。应根据需要对员工的评论进行修订。 '
b'o一个书面叙述,详细介绍了请求,业务/使用操作信息,未来的开发计划,站点和建筑物改进,暂定开发时间表以及估计的项目价值。o规模的图纸,包括但不限于;现场计划,评分/侵蚀控制计划,初步的雨水管理计划,景观计划,照明计划,建筑物高程,有色效果图,标志细节和自然资源描述。所有以数字格式提供的应用材料(Adobe PDF)。材料可以在USB闪存驱动器上提交,也可以通过电子邮件发送至hurd@pewaukee.wi.us。注释十二(12)委员会将需要进行其他计划。应根据需要对员工评论进行修订。 '

缩放数据以根据脑信号重建视频
摘要。脑刺激重建领域在过去几年中取得了重大进展,但技术仍然是针对特定主题的,并且通常在单个数据集上进行测试。在这项工作中,我们提出了一种新技术,用于从功能性磁共振成像 (fMRI) 信号重建视频,该技术旨在跨数据集和跨人类参与者进行性能测试。我们的流程利用多数据集和多主题训练,从来自不同参与者和不同数据集的大脑活动中准确地生成 2 秒和 3 秒的视频片段。这有助于我们回归预训练的文本到视频和视频到视频模型的关键潜在和条件向量,以重建与参与者观察到的原始刺激相匹配的精确视频。我们流程的关键是引入一种 3 阶段方法,首先将 fMRI 信号与语义嵌入对齐,然后回归重要向量,最后使用这些估计生成视频。我们的方法展示了最先进的重建能力,并通过定性和定量分析(包括众包人工评估)进行了验证。我们展示了跨两个数据集以及多主题设置的性能改进。我们的消融研究揭示了不同的对齐策略和数据缩放决策如何影响重建性能,并且我们通过分析随着更多主题数据的利用,性能如何演变来暗示零样本重建的未来。

Skywork-Math:大型语言模型中数学推理的数据缩放定律——故事还在继续
在本文中,我们研究了可能增强大型语言模型 (LLM) 数学推理能力的潜在因素。我们认为,现代 LLM 中数学推理能力的数据缩放规律远未饱和,这突显了模型质量如何随着数据量的增加而提高。为了支持这一说法,我们使用我们提出的 2.5M 实例 Skywork-MathQA 数据集在常见的 7B LLM 上引入了 Skywork-Math 模型系列,该模型系列进行了监督微调 (SFT)。仅使用 SFT 数据,Skywork-Math 7B 在竞赛级 MATH 基准上实现了 51.2% 的惊人准确率,在 GSM8K 基准上实现了 83.9% 的惊人准确率,在 MATH 上的表现优于 GPT-4 的早期版本。 Skywork-Math 模型的卓越性能为我们新颖的两阶段数据合成和模型 SFT 流程做出了贡献,其中包括三种不同的增强方法和多样化的种子问题集,从而确保了 Skywork-MathQA 数据集在不同难度级别上的数量和质量。最重要的是,我们提供了一些实用的要点,以增强 LLM 中的数学推理能力,无论是在研究还是在行业应用中。