XiaoMi-AI文件搜索系统
World File Search System视觉模型

通过推断出明显的摘要 - 特征夹子凝视:通过视觉语言模型进行一般凝视估计
凝视估计方法由于测试和训练数据之间的域间隙,在跨不同领域进行评估时,经常会出现明显的表现降解。现有方法试图使用各种主要的概括方法来解决此问题,但由于凝视数据集的多样性有限,例如外观,可穿戴和图像质量,因此很少成功。为了克服这些限制,我们提出了一个名为Clip Gaze的新型框架,该框架利用预先训练的视觉模型来利用其可转移的知识。我们的框架是第一个利用视觉和语言跨模式的方法来进行凝视任务。具体来说,我们通过将其从凝视式的功能推开,可以通过语言描述灵活构建,从而提取了与凝视的功能。要学习更多合适的提示,我们建议一种个性化的上下文优化方法,以提示提示。此外,我们还利用凝视样本之间的关系来完善视线相关特征的分布,从而提高了凝视估计模型的概括能力。的实验实验表明,在四个跨域评估上,夹具凝视的表现出色。

clearclip:分解剪辑表示密集的视觉语言推理
摘要。尽管大规模预处理的视觉模型(VLM)尤其是在各种开放式播放任务中的剪辑,但它们在语义细分中的应用仍然具有挑战性,从而产生了带有错误分段区域的嘈杂分段图。在本文中,我们仔细地重新调查了剪辑的架构,并将残留连接确定为降低质量质量的噪声的主要来源。通过对剩余连接中统计特性的比较分析和不同训练的模型的注意力输出,我们发现剪辑的图像文本对比训练范式强调了全局特征,以牺牲局部歧视,从而导致嘈杂的分割结果。在响应中,我们提出了一种新型方法,该方法是分解剪辑的表示形式以增强开放式语义语义分割的。我们对最后一层介绍了三个简单的修改:删除剩余连接,实现自我关注并丢弃馈送前进的网络。ClearClip始终生成更清晰,更准确的绘制图,并在多个基准测试中胜过现有的方法,从而确认了我们发现的重要性。

UAD:机器人操纵中无监督的负担蒸馏
摘要:了解机器人必须在给定开放式任务中的非结构化环境中操纵对象。但是,现有的视觉负担预测方法通常仅在一组预定义的任务上手动注释的数据或条件。我们介绍了无监督的负担蒸馏(UAD),这是一种将负担知识从基础模型提炼到任务条件的辅助模型的方法,而无需任何手动注释。通过利用大型视觉模型和视觉模型的互补优势,UAD自动注释了一个具有详细的<指令,Visual Profiseance> Pairs的大规模数据集。仅在冷冻功能上训练一个轻巧的任务条件解码器,尽管仅在模拟中接受了对渲染的对象的培训,但UAD对野外机器人场景和各种人类活动表现出显着的概括。UAD提供的可负担性作为观察空间,我们展示了一项模仿学习政策,该政策证明了有希望的概括,可以看到对象实例,对象类别,甚至在培训大约10次演示后进行任务指令的变化。项目网站:https://gpt-affordance.github.io/。

ClearClip:分解密度的剪辑表示...
摘要。尽管大规模预处理的视觉模型(VLM)尤其是在各种开放式播放任务中的剪辑,但它们在语义细分中的应用仍然具有挑战性,从而产生了带有错误分段区域的嘈杂分段图。在本文中,我们仔细地重新调查了剪辑的架构,并将残留连接确定为降低质量质量的噪声的主要来源。通过对剩余连接中统计特性的比较分析和不同训练的模型的注意力输出,我们发现剪辑的图像文本对比训练范式强调了全局特征,以牺牲局部歧视,从而导致嘈杂的分割结果。在响应中,我们提出了一种新型方法,该方法是分解剪辑的表示形式以增强开放式语义语义分割的。我们对最后一层介绍了三个简单的修改:删除剩余连接,实现自我关注并丢弃馈送前进的网络。ClearClip始终生成更清晰,更准确的绘制图,并在多个基准测试中胜过现有的方法,从而确认了我们发现的重要性。

intel®GETI™平台
医疗保健从业人员可以用来增强患者护理和康复的助手。通过快速训练和部署实用的AI动力计算机视觉模型,可以更快地检测到以进行治疗。AI和机器学习算法可以识别医学文献,患者记录和遗传数据之间的模式和关联,这些模式和关联可以更准确,快速鉴定出存在罕见疾病并实现早期检测和干预。易于使用的英特尔Geti的性质使医生可以通过轻松的点击格式将其专业知识转移到加速注释和模型创建中,而无需或时间学习广泛的AI技术技能。随着组织获得更多的患者扫描,随着时间的推移,可以重新训练并改进使用Intel Geti平台的初始模型。将更多的数据和专家反馈集成到模型中,只会进一步帮助医生,并提高患者诊断的速度和准确性。AI和英特尔Geti平台正在帮助改变医疗服务 - 以及许多其他行业,从制造环境中的缺陷检测到智能农业技术。
![arxiv:2409.02914v1 [cs.cv] 4月4日2024](/simg/2\2c59d05176315666685a9c6e7ce046d3e8571f66.webp)
arxiv:2409.02914v1 [cs.cv] 4月4日2024
大型视觉模型(LVLM)最近引起了极大的关注,许多努力旨在利用其一般知识来增强自主驾驶模型的可靠性和鲁棒性。但是,LVLM通常依靠大型通用数据集,并且缺乏专业驾驶所需的专业专业知识。现有的视觉驱动数据集主要关注场景的理解和决策,而无需提供有关交通规则和驾驶技能的明确指导,这是与驾驶安全直接相关的关键方面。为了弥合这一差距,我们提出了IDKB,这是一个大规模数据集,其中包含从各个国家 /地区收集的一百万个数据项,包括驾驶手册,理论测试数据和模拟道路测试数据。很像获得驾驶执照的过程,IDKB几乎涵盖了从理论到实践所需的所有明确知识。在特殊情况下,我们对IDKB进行了15 lvlms的全面测试,以评估其在自治驾驶的背景下的可靠性,并提供了广泛的分析。我们还微调了流行模型,实现了显着的性能改进,这进一步验证了我们数据集的重要性。项目页面可以在以下网址找到:https:// 4dvlab.github.io/project_page/idkb.html

使用多模式大语言模型(MLLM)进行运输中的对象检测:全面的审查和经验测试
本研究旨在全面审查和经验评估多模式大语模型(MLLM)和大型视觉模型(VLM)在运输系统的对象检测中的应用。在第一个折叠中,我们提供了有关MLLM在运输应用中的潜在好处的背景,并在先前的研究中对当前的MLLM技术进行了全面审查。我们强调了它们在各种运输方案中对象检测中的有效性和局限性。第二倍涉及在运输应用程序和未来方向中概述端到端对象检测的概述。在此基础上,我们提出了对三个现实世界传输问题测试MLLM的经验分析,其中包括对象检测任务,即道路安全属性提取,安全至关重要的事件检测和热图像的视觉推理。我们的发现提供了对MLLM性能的详细评估,揭示了优势和改进领域。最后,我们讨论了MLLM在增强运输中对象检测方面的实际限制和挑战,从而为该关键领域的未来研究和发展提供了路线图。

一种简单的背景增强方法,用于使用扩散模型的对象检测
摘要。在计算机视觉中,众所周知,缺乏数据会损害模型性能。在这项研究中,我们应对加强数据集多样性问题的挑战,以使各种下游任务(例如对象检测和实例segmentation)受益。我们通过利用生成模型中的进步,特别是文本对图像合成技术(如稳定扩散)提出了一种简单而有效的数据增强方法。我们的方法着重于标记的真实图像的变化,利用生成对象和背景增强通过indpainting来增强现有的培训数据,而无需其他注释。我们发现,尤其是背景增强,显着提高了模型的鲁棒性和泛化能力。我们还调查了如何提示和掩盖以确保生成的内容符合现有注释。通过对可可数据集的全面评估和其他几个关键对象检测基准测试,我们的增强技术的功效得到了验证,这表明在不同情况下,模型性能没有提高。这种方法为数据集启用的挑战提供了有希望的解决方案,这有助于开发更准确,更健壮的计算机视觉模型。

基于人工智能的犯罪现场调查技术
犯罪现场重建 (CSR) 是刑事调查的重要组成部分,需要仔细检查可用数据以查明导致犯罪的事件链。自人工智能 (AI) 出现以来,对使用基于 AI 的技术进行犯罪现场重建的需求不断增加。我们比较了基于 AI 的犯罪现场重建系统的发展、缺点和潜在应用。我们发现机器学习模型、计算机视觉模型、自然语言处理模型、深度学习模型和图形分析模型在犯罪现场重建方面都取得了显著进展。然而,使用基于 AI 的技术也存在局限性,包括需要大量高质量数据、数据或算法中可能存在偏差以及结果的可解释性。为了克服这些限制,未来的研究应该侧重于开发更强大、更透明的基于 AI 的模型,这些模型集成了多种技术并对结果提供清晰的解释。在过去的几十年里,3D 建模一直是广泛研究的主题。总体而言,基于人工智能的技术有可能彻底改变犯罪现场重建,但需要进一步研究以优化其在刑事调查中的应用。这篇比较评论探讨了人工智能现在和未来在法医科学中的应用。
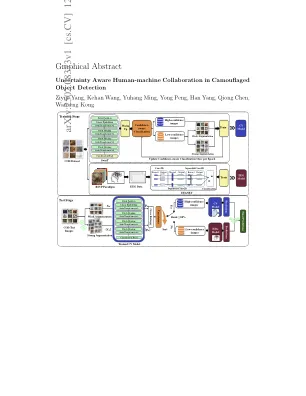
不确定性意识到伪装对象检测中的人机合作
伪装的对象检测(COD)是识别在其环境中识别对象的任务,由于其广泛的实际应用范围很快。开发值得信赖的COD系统的关键步骤是对不确定性的估计和有效利用。在这项工作中,我们提出了一个人机协作框架,用于对伪装物体的存在进行分类,利用计算机视觉模型(CV)模型的互补优势和无创的脑部计算机界面(BCIS)。我们的方法引入了一个多视障碍,以估计简历模型预测中的不明显,利用这种不确定性在培训过程中提高效率,并通过基于RSVP的BCIS在测试过程中为人类评估提供了低信任案例,以实现更可靠的决策。我们在迷彩数据集中评估了框架,与现有方法相比,平衡准确性(BA)的平均平均提高为4.56%,F1得分的平均提高为4.56%。对于表现最佳的细节,BA的改善达到7.6%,F1分数为6.66%。对培训过程的分析表明,我们的信心措施和精度之间存在很强的相关性,而消融研究证实了拟议的培训政策和人机合作的有效性