机构名称:
¥ 2.0
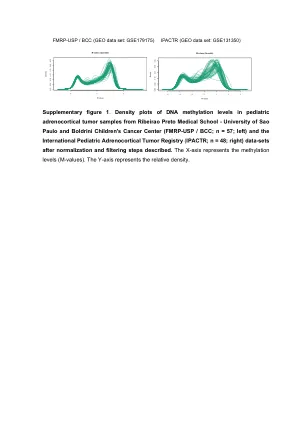
摘要。尽管大规模预处理的视觉模型(VLM)尤其是在各种开放式播放任务中的剪辑,但它们在语义细分中的应用仍然具有挑战性,从而产生了带有错误分段区域的嘈杂分段图。在本文中,我们仔细地重新调查了剪辑的架构,并将残留连接确定为降低质量质量的噪声的主要来源。通过对剩余连接中统计特性的比较分析和不同训练的模型的注意力输出,我们发现剪辑的图像文本对比训练范式强调了全局特征,以牺牲局部歧视,从而导致嘈杂的分割结果。在响应中,我们提出了一种新型方法,该方法是分解剪辑的表示形式以增强开放式语义语义分割的。我们对最后一层介绍了三个简单的修改:删除剩余连接,实现自我关注并丢弃馈送前进的网络。ClearClip始终生成更清晰,更准确的绘制图,并在多个基准测试中胜过现有的方法,从而确认了我们发现的重要性。
ClearClip:分解密度的剪辑表示...
主要关键词





相关文件推荐