XiaoMi-AI文件搜索系统
World File Search System计划者
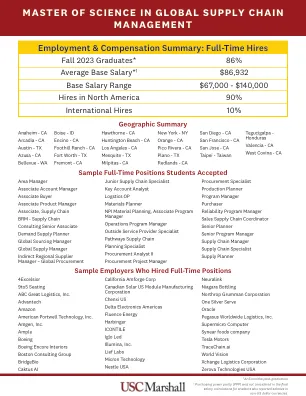
全球供应链中的科学硕士...
初级供应链专家关键帐户分析师Logstics OP材料计划者NPI材料计划,副计划经理运营计划经理外部服务提供商专家途径供应链供应链计划专家采购分析师II采购项目经理

计费代码6717-01-P
2。in No.901,根据FPA的第215(d)(5)条,委员会指示NERC向NEW或修改后的可靠性标准提交给注册IBR的新的或修改后的可靠性标准,除其他方面,以解决问题监控数据共享,绩效要求和事后绩效验证。5委员会指示NERC考虑IBR所有者的负担,以收集和提供由干扰监控设备收集的数据,同时确保批量功率系统运营商和计划者拥有所需的数据来准确进行干扰监控和分析。6委员会还指示NERC提交新的或修改后的可靠性标准,这些标准“要求发电机所有者与相关的计划协调员,传输计划者,可靠性协调员,传输操作员和平衡当局进行实际扰动后扰动率的速率平衡。” 7委员会指示NERC在2024年11月4日之前向委员会提交新的或修改的可靠性标准。8


srlm:具有大语言模型和深度强化学习
摘要 - 交互式社交机器人助手必须在复杂而拥挤的空间中提供服务,同时根据实时人类语言命令或反馈来调整其行为。在本文中,我们提出了一种新型的混合方法,称为社会机器人计划者(SRLM),该方法集成了大型语言模型(LLM)和深度强化学习(DRL),以浏览人体充满的公共空间并提供多种社会服务。srlm实时从人类中的命令中注入全球计划,并将社会信息编码为基于LLM的大型导航模型(LNM),以进行低级运动执行。此外,基于DRL的计划者旨在维持基准测试性能,该性能由大型反馈模型(LFM)与LNM混合,以解决当前文本和LLM驱动的LNM的不稳定性。最后,SRLM在广泛的实验中表现出了出色的表现。有关此工作的更多详细信息,请访问:https://sites.google.com/view/navi-srlm。
MPC计划安全和可信赖的机器人动议
摘要 - 安全人类机器人相互作用(HRI)的策略,例如已建立的安全运动单元,为生物力学上安全的机器人运动提供了速度缩放。此外,值得信赖的HRI需要基于心理的安全方法。此类方案可以非常保守,并且在机器人运动计划中应效率地符合此类安全方法。在这项研究中,我们通过模型预测控制机器人运动计划器提高了先前引入的基于心理安全性的安全性方法的效率,该方法同时调整了笛卡尔路径和速度,以最大程度地减少到目标姿势的距离。下属实时运动发生器通过整合安全运动单元来确保人体安全。我们的运动计划者通过两个实验验证。同时调整路径和速度可以实现高度时间的机器人运动,同时考虑了人类的身体和心理安全。与直接路径速度缩放方法相比,我们的计划者可以实现28%的运动执行。

不可观察的蒙特卡洛计划非骚扰重排任务
摘要 - 在这项工作中,我们提出了一位用于创建开环轨迹的计划者,该轨迹可以使用非恐怖分子的方法来解决不确定性下的重排计划问题。我们首先将蒙特卡洛树搜索算法扩展到了不可观察的域。然后,我们提出了两项默认政策,使我们能够快速确定实现目标的潜力,同时考虑到重新安排计划至关重要的联系。第一个策略使用从一组用户演示中生成的学习模型。可以快速查询此模型的一系列动作,这些操作试图创建与对象并实现目标。第二策略在全州空间的子空间中使用了启发式指导计划者。使用这些目标知情政策,我们能够快速找到该问题的初始解决方案,然后在时间允许的情况下不断地重新填充解决方案。我们在桌子上的7个自由度操纵器移动对象上演示了我们的算法。

气候变化对生态系统和物种的影响
本卷中的论文说明了有关环境变化的范围和不确定性,这些变化可能由于气候变化和大气二氧化碳浓度的增加而预期发生。尽管当前的技术和方法适合符合特定要求,但它们对这些变化的结果的预测具有更普遍的适用性。论文还强调了计划者和经理的需求

trelpy:用于任务相关的感知评估的工具箱
摘要 - 在安全 - 关键的自治系统中,得出系统级保证需要以与系统级任务一致的方式评估单个子系统。这些安全保证需要仔细的理由,以了解如何评估每个子系统,并且评估必须与子系统的相互作用和其中所做的任何假设一致。一个常见的例子是感知与计划之间的相互作用。Trelpy是一个基于Python的工具箱,可以评估感知模型的性能,并通过概率模型检查在计算系统级保证中利用这些评估。该工具为流行检测指标(例如混淆矩阵)实现了这一框架,并实现了新的指标,例如命题标记的混淆矩阵。选择混淆矩阵标签的命题公式,以使混淆矩阵与下游计划者和系统级任务相关。Trelpy还可以通过Egentric距离或相对于自我车辆进行方向分组对象,以进一步使混乱矩阵更多的任务相关。这些指标被利用以计算感知和计划者的综合性能,并计算系统级要求的满意度概率。
机器人加速器的碰撞预测
摘要 - 动态环境中的动作计划是自动机器人技术的重要任务。新兴方法采用可以通过观察(例如人类)专家来学习的神经网络。此类运动计划者通过不断提出候选路径以实现目标来对环境做出反应。这些候选路径中的一些可能是不安全的,即导致碰撞。因此,必须使用碰撞检测检查提议的路径以确保安全。我们观察到,如果我们可以预期哪些查询将返回不安全的结果,则可以消除25% - 41%的碰撞检测查询。我们利用这一观察结果提出了一种机制坐标,以预测沿拟议路径的给定机器人位置(姿势)是否会导致碰撞。通过优先考虑对预测碰撞的详细评估,坐标可以快速消除神经网络和其他基于采样的运动计划者提出的无效路径。坐标通过利用不同机器人姿势的物理空间位置并使用简单的哈希和饱和计数器来实现这一目标。我们证明了在包括CPU,GPU和ASIC在内的不同计算平台上碰撞预测的潜力。我们进一步提出了一个硬件碰撞预测单元(COPU),并将其与现有的碰撞检测加速器集成在一起。这平均17。2% - 32。跨不同运动计划算法和机器人的碰撞检测查询数量减少了1%。当应用于最先进的神经运动计划者[41]时,坐标会提高性能/瓦特1。平均而言,针对不同难度水平的运动计划查询。此外,我们发现碰撞预测的好处随着运动计划查询的计算复杂性增加并提供1。30×在狭窄的段落和混乱的环境中进行性能/瓦特的迹象。索引术语 - 机器人,硬件加速度,运动计划,碰撞检测,碰撞预测
![arxiv:2406.06978v4 [CS.CV] 2024年8月30日](/simg/0\0e09b061d49570ad773a0a825e2a80bd33b33716.webp)
arxiv:2406.06978v4 [CS.CV] 2024年8月30日
端到端的自主驾驶涉及学习具有原始传感器输入的神经计划者,被认为是实现完全自治的承诺方向。尽管在该领域取得了令人鼓舞的进展[11,12],但最近的研究[4,8,14]已经暴露了多个漏洞和模仿学习方法的局限性(IL)方法,尤其是开环评估中固有的问题,例如功能失调的指标和隐式偏见[8,14]。这至关重要,因为它无法保证安全,效率,舒适性和遵守交通规则。为了解决这一主要局限性,几项作品提出了合并闭环指标,通过确保机器学习的计划者符合基本标准,这些封闭环指标更有效地评估了端到端的自主驾驶,而不仅仅是模仿人类驾驶员。因此,端到端计划是理想情况下的多目标和多模式的任务,其中多目标计划涉及符合开环和闭环设置的各种评估指标。在这种情况下,多模式指示每个度量的多个最佳解决方案。现有的端到端方法[4,11,12]经常尝试