XiaoMi-AI文件搜索系统
World File Search System钟摆
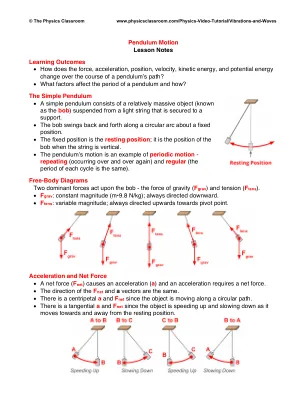
钟摆运动 - 课堂笔记
• 净力(F net )产生加速度(a),加速度需要净力。• F net 和 a 矢量的方向相同。• 由于物体沿圆形路径移动,因此存在向心 a 和 F net。• 由于物体在运动过程中不断加速和减速,因此存在切向 a 和 F net

设计富有同情心的框架
核心引擎是一个深度学习框架,它能够分析数据并形成概念。神经网络的不同隐藏层将代表概念。例如,深度学习框架分析来自摆动钟摆的数据。它将构建该数据的内部模型表示并发现像振荡周期这样的不变量(图 2)[1]。深度学习框架还将分析这些数据并形成钟摆周期的概念。这还将通过人类输入关于该概念实际含义的信息以及通过解析来自开源知识语料库(如维基百科)的相应定义来强化(如图 2 所示)。我们假设这些机器将这些不同的信息源连接得越多并形成概念,

讲座 - PCB 压电电子学(1)
• 当机械结构失去平衡并围绕平衡点产生振荡运动时,就会发生振动。振荡可能是周期性的,例如钟摆的运动,也可能是随机的,例如飞行过程中机翼上的负载。振动下的机械系统的特征由加速度、速度和位移分量组成。

计算机和信息科学与工程 (CISE)
麻省理工学院的研究人员发现了一种将量子信息存储在原子对振动运动中的方法,类似于两个由弹簧连接的钟摆的摆动运动。量子系统包含数百对振动量子比特,或量子位,研究人员可以连贯地控制它们超过 10 秒。图片来源:Sampson Wilcox/RLE


大脑互动,思维同步
摘要 我们生活在一个相互交流的社会世界中。神经反馈 (NFB) 是这种互动中不可或缺的元素。使用脑电图 (EEG) 或其他神经影像记录的单人 NFB 研究已被广泛报道。然而,使用脑间同步 (IBS) 作为 NFB 特征的超扫描研究却完全未知。在本研究中,我们提出了两种不同的实验设计,其中 IBS 以视觉反馈的形式反馈,要么是两个球互相接近(所谓的“球”设计),要么是两个钟摆反映两个参与者的振荡活动(所谓的“钟摆”设计)。NFB 以两种 EEG 频率(2.5 和 5 Hz)提供,并通过增强(假条件)和逆反馈进行操纵。我们表明,参与者能够通过使用 NFB 来增加 IBS,尤其是当它以 theta 频率反馈时。除了脑内和脑间耦合外,与休息时相比,任务期间的其他振荡活动(例如功率谱密度、峰值幅度和峰值频率)也发生了变化。此外,所有测量值都与主观的调查后项目分数具有特定的相关性,反映了主观感受和评价。我们得出结论,以 IBS 作为反馈特征的超扫描似乎是研究社会互动和集体行为神经机制的重要工具。

实现“GRACE-I”卫星任务,用于并行观测
o 例如,在具有大倾斜角的钟摆轨道上飞行(这会增加对东西重力变化的敏感性)将需要进一步研究,因为由此产生的两个航天器的相对速度可能对于 LRI 操作来说太高。o 对于低于 420 公里的高度(为了进一步增加对重力变化的敏感性),非重力力的增加幅度可能对于加速度计来说太大,可能需要更复杂的 AOCS。o 将航天器的分离从 220 公里增加到 300 或 400 公里(这将降低加速度计误差的影响)另一方面会增加两颗卫星之间的指向要求,这可能会抵消大距离的积极影响。所有这三个都需要在后续研究中进一步调查。

滑翔机和滑翔 1993 - Amazon S3
1.拖车越重、功率越大越好。2.后轴到球的距离越短越好(例如,轻型后备箱车,如福特 Orion,不是理想的拖车)。3.拖车后悬架越硬越好。4.一般而言,拖车前部重量越大越好。但是,不应过重,以免拖车前轴卸载并影响转向。5.为了保持稳定性,我更喜欢拖车上硬且充气良好的交叉层轮胎。6.双轴拖车通常比单轴拖车更稳定。7.尽可能减少拖车的转动惯量。即通过将任何可移动的重量加载到中心来减少钟摆效应。而不是拖车的末端。更好的是,将其装载在车上。
滑翔机和滑翔 1993 - Amazon S3
1. 拖车越重、功率越大越好。2. 后轴到球的距离越短越好(例如,轻型拖车,例如 Ford Orion,不是理想的拖车)。3. 拖车后悬架越硬越好。4. 一般来说,拖车鼻梁重量越大越好,而不是越小越好。但是,不应过重,以免拖车前轴负载过大,影响转向。5. 为了稳定,我更喜欢拖车使用坚硬、充气良好的交叉帘布层轮胎。6. 双轴拖车通常比单轴拖车更稳定。7. 尽可能减少拖车的转动惯量,例如,将任何可移动的重量加载到拖车中心,而不是末端,以减少钟摆效应。更好的是,将其加载到车上。
滑翔机和滑翔 1993 - Amazon S3
1. 拖车越重、功率越大越好。2. 后轴到球的距离越短越好(例如,轻型拖车,例如 Ford Orion,不是理想的拖车)。3. 拖车后悬架越硬越好。4. 一般来说,拖车鼻梁重量越大越好,而不是越小越好。但是,不应过重,以免拖车前轴负载过大,影响转向。5. 为了稳定,我更喜欢拖车使用坚硬、充气良好的交叉帘布层轮胎。6. 双轴拖车通常比单轴拖车更稳定。7. 尽可能减少拖车的转动惯量,例如,将任何可移动的重量加载到拖车中心,而不是末端,以减少钟摆效应。更好的是,将其加载到车上。