XiaoMi-AI文件搜索系统
World File Search SystemAUPRC

基于儿科心电图的深度学习预测左心室功能障碍和重塑
结果:训练队列包括 92 377 个心电图-超声心动图对(46 261 名患者;中位年龄 8.2 岁)。测试组包括内部测试(12 631 名患者;中位年龄 8.8 岁;4.6% 综合结果)、急诊科(2 830 名患者;中位年龄 7.7 岁;10.0% 综合结果)和外部验证(5 088 名患者;中位年龄 4.3 岁;6.1% 综合结果)队列。内部测试和急诊科队列的模型性能相似,模型对左心室肥大的预测优于儿科心脏病专家基准。在模型中添加年龄和性别不会给模型性能带来任何好处。使用定量结果截止值时,内部测试(综合结果:AUROC,0.88,AUPRC,0.43;左心室功能障碍:AUROC,0.92,AUPRC,0.23;左心室肥大:AUROC,0.88,AUPRC,0.28;左心室扩张:AUROC,0.91,AUPRC,0.47)和外部验证(综合结果:AUROC,0.86,AUPRC,0.39;左心室功能障碍:AUROC,0.94,AUPRC,0.32;左心室肥大:AUROC,0.84,AUPRC,0.25;左心室扩张:AUROC,0.87,AUPRC,0.33)之间的模型性能相似,综合结果阴性预测值分别为 99.0% 和 99.2%。显着性映射突出显示了影响模型预测的 ECG 成分(所有结果的心前区 QRS 波群;LV 功能障碍的 T 波)。高风险 ECG 特征包括横向 T 波倒置(LV 功能障碍)、V1 和 V2 中的深 S 波和 V6 中的高 R 波(LV 肥大)以及 V4 至 V6 中的高 R 波(LV 扩张)。

SleepFM:在大脑活动,ECG和呼吸信号
睡眠是通过记录各种方式来评估一种复杂的生理过程。我们从14,000多个参与者中策划了一个大型的多模式睡眠记录的大型多摄影数据集。掌握了这个广泛的数据集,我们开发了SleepFM,这是第一个用于睡眠分析的多模式基础模型。我们表明,与标准的成对构造学习的表示相比,一种新颖的对比学习方法可以显着证明下游任务绩效。A logistic regression model trained on SleepFM 's learned embeddings out- performs an end-to-end trained convolutional neu- ral network (CNN) on sleep stage classification (macro AUROC 0.88 vs 0.72 and macro AUPRC 0.72 vs 0.48) and sleep disordered breathing de- tection (AUROC 0.85 vs 0.69 and AUPRC 0.77 vs 0.61)。值得注意的是,从90,000名候选人中获取其他响应的记录剪辑,学到的嵌入在检索其他方式的记录剪辑方面达到了48%的平均准确性。这项工作展示了整体多模式睡眠模型的价值,以完全捕获睡眠记录的丰富性。SleepFM是开源的,可在https://github.com/rthapa84/sleepfm-codebase上找到。

SleepFM:在大脑活动,ECG和呼吸信号
睡眠是通过记录各种方式来评估一种复杂的生理过程。我们从14,000多个参与者中策划了一个大型的多模式睡眠记录的大型多摄影数据集。掌握了这个广泛的数据集,我们开发了SleepFM,这是第一个用于睡眠分析的多模式基础模型。我们表明,与标准的成对构造学习的表示相比,一种新颖的对比学习方法可以显着证明下游任务绩效。A logistic regression model trained on SleepFM 's learned embeddings out- performs an end-to-end trained convolutional neu- ral network (CNN) on sleep stage classification (macro AUROC 0.88 vs 0.72 and macro AUPRC 0.72 vs 0.48) and sleep disordered breathing de- tection (AUROC 0.85 vs 0.69 and AUPRC 0.77 vs 0.61)。值得注意的是,从90,000个候选者中检索模态剪辑对时,学到的嵌入在检索模态剪辑对方面具有48%的平均准确性。这项工作展示了整体多模式睡眠建模的价值,以完全捕获睡眠记录的丰富性。SleepFM是开源的,可在https://github.com/rthapa84/sleepfm- codebase上找到。

deepdra:使用多摩尼克数据集成与自动编码器进行重新利用
癌症治疗已成为当今世界上最大的挑战之一。使用不同的治疗方法针对癌症;基于药物的治疗结果显示出更好的结果。另一方面,为癌症设计新药是昂贵且耗时的。已经建议使用一些组合方法,例如机器学习和深度学习,以使用药物重新利用来解决这些挑战。尽管有望在重新利用癌症药物和预测反应中采用经典的机器学习方法,但深度学习方法的表现更好。本研究旨在开发一种深入学习模型,该模型可以根据多摩变数据,药物描述符和药物指纹预测癌症药物反应,并根据这些反应促进对药物的重新申请。为了降低多媒体数据的维度,我们使用自动编码器。作为多任务学习模型,自动编码器已连接到MLP。我们使用三个主要数据集对模型进行了广泛的测试:GDSC,CTRP和CCLE确定其功效。在多个实验中,我们的模型总体上优于现有的最新方法。与最先进的模型相比,我们的模型达到了令人印象深刻的AUPRC为0.99。此外,在跨数据库评估中,该模型在GDSC上进行了训练并在CCLE上进行了测试,它超过了先前的三项工作的表现,达到了0.72的AUPRC。总而言之,我们提出了一个深度学习模型,以优于当前有关概括的最新技术。我们的研究强调了高级深度学习的潜力,以提高癌症治疗精度。使用此模型,我们可以评估药物反应并探索药物的重新构成,从而发现新型癌症药物。

XSL•fo
背景:心脏骤停(CA)是重症患者死亡的主要原因。临床研究表明,对CA的早期鉴定会降低死亡率。算法能够使用多元时间序列数据来预测具有高灵敏度的Ca。但是,这些算法遭受了很高的错误警报率,它们的结果在临床上不可解释。目标:我们使用多分辨率统计特征和基于余弦相似性的特征提出了一种集成方法,以及时预测Ca。此外,这种方法提供了临床上可解释的结果,临床医生可以采用这些结果。方法:使用来自“重症监护IV数据库”和EICU协作研究数据库的医学信息MART的数据回顾性分析患者。基于被诊断为心力衰竭的成年人的24小时时间窗口的多元生命体征,我们提取了基于多解决的统计和基于余弦相似性的特征。这些功能用于构建和发展梯度提升决策树。因此,我们采用了对成本敏感的学习作为解决方案。然后,进行了10倍的交叉验证以检查模型性能的一致性,并使用Shapley添加说明算法来捕获所提出模型的整体可解释性。接下来,使用EICU协作研究数据库进行了外部验证以检查概括能力。根据CA的及时预测,提出的模型达到了高于0.80的AUROC,以预测提前6小时的CA事件。结果:所提出的方法在接收器工作特性曲线(AUROC)下产生了0.86的总面积,并且在Precision-Recall曲线(AUPRC)下为0.58。所提出的方法同时提高了精度和灵敏度以增加AUPRC,从而减少了错误警报的数量,同时保持了高灵敏度。此结果表明所提出的模型的预测性能优于先前研究中报告的模型的性能。接下来,我们证明了特征重要性对所提出方法的临床解释性的影响,并推断了非CA和CA组之间的影响。最后,使用EICU协作研究数据库进行了外部验证,并且在一般重症监护病房的人群中获得了0.74的AUROC,AUPRC为0.44。结论:拟议的框架可以为临床医生提供更准确的CA预测结果,并通过内部和外部验证降低错误警报率。此外,临床上可解释的预测结果可以促进临床医生的理解。此外,生命体征变化的相似性可以为患有心力衰竭相关诊断患者的CA预测的时间模式变化提供见解。因此,我们的系统足以适合常规临床使用。此外,关于拟议的CA预测系统,在未来的数字健康领域开发了临床成熟的应用程序。

伊利诺伊州Sudors数据的见解
了解与美沙酮参与无意药过量死亡相关的死者特征的知识可以帮助您努力干预这些死亡。ML模型具有现有数据,提供具有成本效益的手段来帮助创建有效的干预措施。在这项研究中,我们旨在开发一种优化的ML算法,用于使用伊利诺伊州州非明显药物过量报告系统(SUDORS)的数据来预测通过美沙酮过量死亡的方法。我们利用IL SUDORS 2019-2022数据进行培训(n = 11931),带有选定的指标(n = 28)。为了解决与非甲基阿达酮相关死亡的不平衡,我们采用了合成少数族裔的过度采样技术。接下来,我们评估了各种机器学习模型,包括逻辑回归,支持向量机,随机森林,神经网络和山脊回归。使用METIC评估模型性能,例如精度,精度,Precision-Recall曲线(AUPRC)等。利用单独的培训(n = 15813),验证(n = 3388)和测试(n = 3389)数据集,随机森林模型的表现优于所有其他模型,具有92%的精度,91%的精度,93%的召回率和0.97 AUPRC。值得注意的是,这些外部是使用主要是人口统计指标实现的。通过分析部分依赖图,我们能够看到每个指标的变化如何动态影响与美沙酮相关的死亡。这项研究证明了ML模型在鉴定美沙酮参与无意药过量死亡中的潜力,并有助于预防这些死亡的知识库。利用SUDORS数据,随机森林模型表现出了出色的表现,突出了其对医疗保健专业人员,预防和减少危害专家的价值以及决策者。
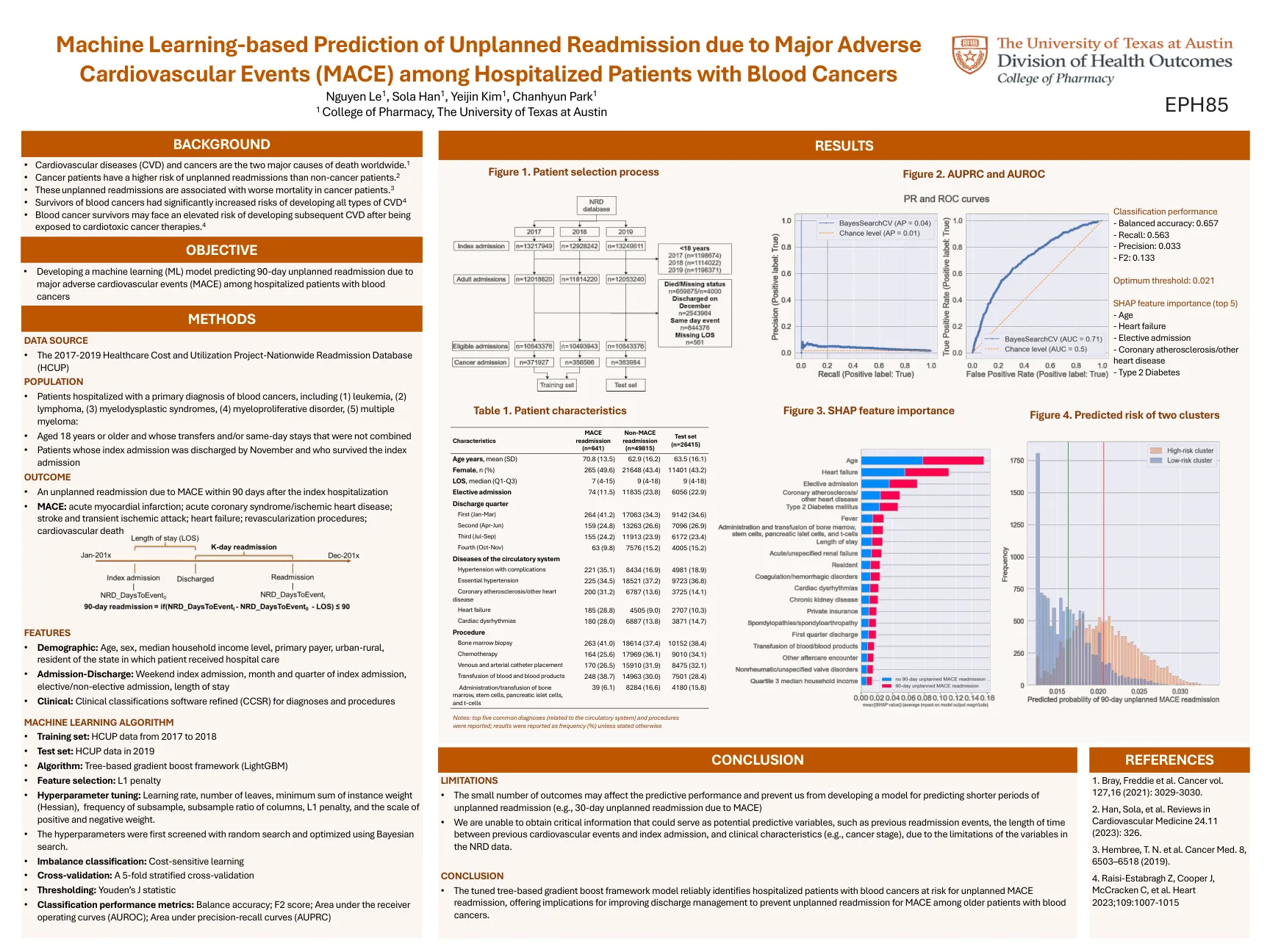
基于机器学习的预测未计划的重新入学,这是由于主要不利
MACHINE LEARNING ALGORITHM • Training set: HCUP data from 2017 to 2018 • Test set: HCUP data in 2019 • Algorithm: Tree-based gradient boost framework (LightGBM) • Feature selection: L1 penalty • Hyperparameter tuning: Learning rate, number of leaves, minimum sum of instance weight (Hessian), frequency of subsample, subsample ratio of columns, L1 penalty, and the scale of positive and negative weight.•首先对超参数进行筛选,并使用贝叶斯搜索进行优化。•不平衡分类:成本敏感的学习•交叉验证:5倍分层的交叉验证•阈值:Youden的J统计量•分类性能指标:平衡精度; F2分数;接收器操作曲线(AUROC)下方; Precision-Recall曲线(AUPRC)下的区域

比较医学概念表示和患者轨迹预测的神经语言模型
医学概念的有效表示对于电子健康记录的次要分析至关重要。神经语言模型在自动从临床数据中得出医学概念表示方面已显示出希望。但是,尚未对不同语言模型的比较性能,用于创建这些经验表示形式及其编码医学语义的程度,尚未得到广泛的研究。本研究旨在通过评估三种流行语言模型的有效性 - word2vec,fastText和手套 - 在创建捕获其语义含义的医学概念嵌入中的有效性。通过使用大量的数字健康记录数据集,我们创建了患者轨迹,并用它们来训练语言模型。然后,我们通过与生物医学术语进行明确比较来评估学到的嵌入式编码语义的能力,并通过预测具有不同级别可用信息的患者结果和轨迹来隐含。我们的定性分析表明,FastText学到的嵌入的经验簇与从生物医学术语获得的理论聚类模式表现出最高的相似性,分别在0.88、0.80和0.92的经验簇和0.92之间的诊断,过程和医疗代码分别为0.88、0.80和0.92之间。相反,为了预测,Word2Vec和Glove倾向于优于快速文本,而前者的AUROC分别高达0.78、0.62和0.85,分别用于现场长度,再入院和死亡率预测。在预测患者轨迹中的医疗法规时,手套在诊断和药物代码(分别为0.45和0.81)的最高级别上达到了语义层次结构的最高性能(AUPRC分别为0.45和0.81),而FastText优于其他模型的过程代码(AUPRC为0.66)。我们的研究表明,子词信息对于学习医学概念表示至关重要,但是全球嵌入向量更适合于更高级别的下游任务,例如轨迹预测。因此,可以利用这些模型来学习传达临床意义的表示形式,而我们的见解突出了使用机器学习技术来编码医学数据的潜力。

使用前瞻性代表性数据
目的:本研究使用来自印度南部的前瞻性代表性数据集来开发和评估多模式机器学习模型,以区分细菌和真菌性角膜炎。设计:机器学习分类器培训和验证研究。参与者:印度马杜赖(Madurai)的Aravind Eye Hospital诊断出患有急性感染性角膜炎的五百九十九名受试者。方法:我们使用了前瞻性的,连续收集的,代表性的数据集(Madurai数据集)收集的前瞻性,连续收集的代表性数据集,并比较了3种预测模型,以区分细菌和真菌角膜炎。这些模型包括一个临床数据模型,使用效率网状结构的计算机视觉模型以及将成像和临床数据都结合在一起的多模式模型。我们将Madurai数据集分为70%的火车/验证和30%的测试集。进行了模型训练,并进行了五重交叉验证。我们还比较了由Madurai训练的计算机视觉模型的性能与具有相同架构的模型,但对从多个先前的细菌和真菌性角膜炎随机临床试验(RCT)(RCT训练的计算机视觉模型)进行了培训。主要结果指标:主要评估度量是Precision-Recall曲线(AUPRC)下的面积。二级指标包括接收器操作特征曲线(AUROC),准确性和F1分数下的区域。与计算机视觉模型相比,多模式模型并不能显着提高性能。眼科科学2025; 5:100665ª2024,美国眼科学会。结果:由Madurai训练的计算机视觉模型优于临床数据模型和持有测试集的RCT训练的计算机视觉模型,其AUPRC 0.94(95%的置信间隔:0.92 E 0.96),AUROC 0.81(0.76 E 0.85)(0.76 E 0.85)(0.76 E 0.85),精度为77%和F1 0.85。结论:传染性角膜炎的表现最佳的机器学习分类是使用Madurai数据集训练的计算机视觉模型。这些发现表明,基于图像的深度学习可以显着增强感染性角膜炎的诊断能力,并强调使用前瞻性,连续收集的,代表性的机器学习模型培训和评估的重要性。财务披露:本文末尾的脚注和透视性可以在脚注和验证中找到。这是CC BY-NC-ND许可证(http://creativecommons.org/licenses/by-nc-nd/4.0/)下的开放访问文章。

一种新型的基于电子健康记录的机器学习模型,可预测严重低血糖症,导致老年人的糖尿病住院治疗:全领域的同类和建模研究
我们采用了一个病例对照设计,用于回顾性领土范围内的队列,由364,863个独特的老年人(65岁)和至少1洪孔医院的授权从2013年到2018年至2018年。我们在一年的时间内使用了258个预测因素,包括人口统计学,录取,诊断,药物和常规实验室测试,以预测在接下来的12个月内需要住院的SH事件。该队列以7:2:1的比率随机分为训练,测试和内部验证集。六种ML算法,包括逻辑回归,随机森林,梯度增压机,深神经网络(DNN),XGBOOST和RULEFIT。我们在香港糖尿病登记册中与2018年定义的预测因子和2019年定义的结果事件的时间验证队列中测试了我们的模型。使用接收器操作特征曲线(AUROC),精确召回曲线(AUPRC)统计的区域以及正预测值(PPV)评估了预测性能。我们确定了在观察期间需要住院的11,128个SH事件。XGBoost模型