XiaoMi-AI文件搜索系统
World File Search SystemBLEU

使用变压器Palanichamy Naveen 1,Rajasekaran Thangaraj 2和M. Maraga使用变压器的增强机器翻译的上下文增强学习
抽象机器翻译在桥接语言障碍中起着至关重要的作用,但是产生适当的翻译仍然是一个挑战。增强学习技术与变压器模型的集成,以增强上下文相关翻译的产生。通过合并上下文策略梯度方法,一种考虑流利性和上下文的奖励功能,多代理强化学习,课程学习和交互式用户反馈,旨在提高机器翻译的质量。强化学习技术与变压器模型的集成提供了几种关键贡献。它使模型能够通过考虑源句子上下文,目标语言细节和用户偏好来优化翻译决策。拟议的奖励功能设计既包含传统的度量标准得分,又结合了上下文感知的指标,以促进流利性和连贯性。多代理强化学习增强了专门从事不同翻译方面的代理之间的协作。课程学习和用户反馈的互动学习有助于有效的培训和人为指导的微调。实验结果表明,与基线模型相比,翻译质量的显着改善。所提出的方法在评估指标(例如BLEU,流星,胭脂和TER)中获得了更好的分数。此外,定性分析强调了该模型在产生流利,准确和上下文相关的翻译方面的优势。总体而言,增强学习技术与变压器模型的集成在增强机器翻译系统方面有希望,使其更适应能力,以用户为中心,并且能够产生适当的上下文翻译。关键字1机器翻译,增强学习,变压器,交互式学习。

AI自动驾驶:机遇,挑战和...韩国戏剧对心理井的影响使用深度学习算法的图像字幕生成
文章信息abs tract本研究研究了使用VGG16和LSTM架构在FlickR8K数据集上使用图像字幕模型的有效性。通过细致的实验和评估,获得了对模型能力的有价值的见解,并获得了为图像生成描述性字幕的局限性。这些发现有助于对图像字幕技术的更广泛理解,并为该领域的未来进步提供指导。VGG16和LSTM架构的探索涉及数据预处理,模型培训和评估。FlickR8K数据集,包括8,000张与文本描述配对的图像,作为基础。进行了数据预处理,使用VGG16的特征提取和LSTM训练。进行了模型参数和超参数的优化,以实现最佳性能。评估指标(包括BLEU得分,语义相似性评分和胭脂分数)。虽然根据BLEU评分观察到带有参考标题的中等重叠,但该模型表现出高度的语义相似性。然而,通过分析胭脂分数,揭示了维持连贯性和捕获高阶语言结构的挑战。这项研究的含义扩展到诸如计算机视觉,自然语言处理和人类计算机互动之类的领域。通过弥合视觉内容和文本描述之间的语义差距,图像字幕模型可以增强可访问性,改善图像理解并促进人类机器通信。尽管有希望捕获语义内容的表现,但存在改进的机会,包括精炼模型体系结构,集成注意力机制以及利用较大的数据集。图像字幕中的持续创新承诺在行业和学科中广泛应用的高级系统。关键字:图像字幕,深度学习,VGG16,LSTM,FlickR8K数据集,评估指标,语义差距,人类计算机交互。

llm增强语义相似性指标...
在这项研究中,我们利用LLM来增强语义分析并为文本开发相似性指标,以解决传统无监督的NLP指标(如Ruge和Bleu)的局限性。我们开发了一个框架,其中LLM(例如GPT-4)用于放射学报告的零摄影文本标识和标签生成,然后将标签用作文本相似性的测量值。通过在模拟数据上测试提出的框架,我们发现GPT-4生成的标签可以显着提高语义相似性评估,而得分比传统的NLP指标更与临床基础真理紧密相符。我们的工作证明了使用LLMS对高度专业域的半定量推理结果对文本数据进行语义分析的可能性。虽然实施了用于放射学报告相似性分析的框架,但它的概念也可以扩展到其他专业领域。

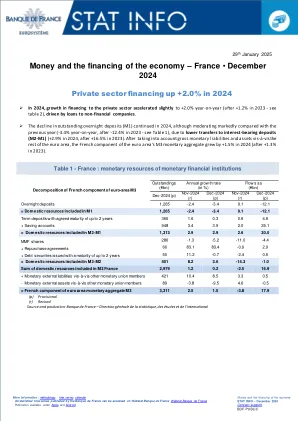
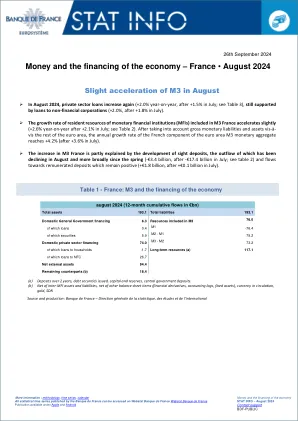
数字欧元将如何影响欧盟参与者的战略意义?
关于卡支付:我们知道国际卡计划正试图排挤国家卡计划,并且已经在许多成员国取得了成功。其中一个例子是万事达卡最近决定废除 maestro,这意味着国家借记卡系统(例如 Carte bleu、Girocard、Bancontact)将不再适用于其他成员国,取而代之的是收取更高商户费用的万事达卡和 Visa 借记卡。2 这表明 PSP 普遍倾向于废除其国家借记卡系统,鼓励消费者使用万事达卡和 Visa 卡。其背后的原因是,PSP 通过发行万事达卡和 Visa 卡比使用自己的国家借记卡系统赚更多的钱。数字欧元提供了 Visa 和万事达卡的替代方案,将抵消这种市场集中度。此外,数字欧元还提供了国家卡计划无法提供解决方案的用例:在线和在另一个成员国进行卡支付。

chie:具有正确性,帮助性,无关紧要和外在性方面的文化质量上下文QA的生成性MRC评估
对Ma-Chine阅读理解(MRC)中生成模型的评估带来了不同的困难,因为Bleu,Rouge,Meteor,Ectect匹配和F1得分等传统指标通常很难捕获细微的和多样化的响应。虽然嵌入基于Bertscore和Bartscore之类的基于基于的指标专注于语义相似性,但它们仍然无法完全解决诸如识别附加有用的信息和奖励忠诚的方面。基于大语言模型(LLM)指标的最新进展提供了更多细粒度的评估,但仍然存在分数聚类等挑战。本文介绍了一个多相关的评估框架,chie,结合了c orcretness,h Elpullness,i rrelevance and e extranesents的各个方面。我们的方法使用二进制分类值而不是连续的评分量表,与人类判断良好,表明其潜力是一种全面有效的评估方法。

深入加固学习的邀请
培训深层神经网络以最大程度地提高目标,已成为过去十年来成功机器学习的标准配方。如果目标目标是可区分的,则可以通过有监督的学习对这些网络进行操作。但是,许多有趣的问题并非如此。共同的目标,例如联合(IOU)的交集以及双语评估研究(BLEU)分数或奖励,无法通过有监督的学习来优化。一个常见的解决方法是定义可区分的替代损失,从而导致相对于实际目标的次优解决方案。强化学习(RL)已成为一种有前途的替代方法,用于优化深度神经网络,以最大程度地提高非差异性目标。示例包括通过人类反馈,代码生成,对象检测或控制问题对齐大语言模型。这使得RL技术与较大的机器学习受众相关。然而,由于大量方法以及通常高度理论上的表现,该主题是在很密集的时间。该专着采用了一种与经典RL教科书不同的替代方法。而不是专注于表格

昏暗:用于机器翻译的迭代非Aut-Autore-ReRoRe-ReReRexression Transformer的多个步骤
随着解码步骤的数量增加,迭代非自回旋变压器的计算益处减小。作为一种补救措施,我们介绍了DI仍然是Untiple S Teps(Dims),这是一种简单而有效的蒸馏技术,以减少达到一定的翻译质量所需步骤的数量。截止的模型享有早期迭代的计算益处,同时从几个迭代步骤中保留了增强性。暗示着两个模型,即学生和老师。在多个解码步骤后,在老师通过缓慢移动的平均值跟随学生的同时,对学生进行了优化,以预测老师的输出。移动平均线使教师的知识更新,并提高了老师提供的标签的质量。在推断期间,学生用于翻译,并且不添加其他构成。我们验证了DIMS对在WMT'14 DE-EN的蒸馏和原始验证上获得7.8和12.9 BLEU点改进的各种模型的有效性。此工作的完整代码可在此处提供:https://github.com/ layer6ai-labs/dims。

文学文本的机器翻译:体裁、时代和体系
近年来,由于深度学习方法的出现,机器翻译 (MT) 得到了迅猛发展,而神经机器翻译 (NMT) 则显著提高了自动翻译的质量。虽然大多数工作涵盖了技术、法律和医学文本的自动翻译,但机器翻译在文学文本中的应用以及人类在这一过程中的作用尚未得到充分探索。为了弥补这一研究不足领域的空白,本文介绍了一项研究的结果,该研究旨在评估三种机器翻译系统对两种不同文学体裁、两部小说(乔治·奥威尔的《1984》和简·奥斯汀的《傲慢与偏见》)和两首诗(艾米莉·狄金森的《我感受到了大脑中的葬礼》和玛格丽特·阿特伍德的《海妖之歌》)的性能,这代表了不同的文学时期和时间线。评估通过自动评估指标 BLEU 进行,以客观评估机器翻译系统在每种体裁中的表现。本研究还概述了其局限性。