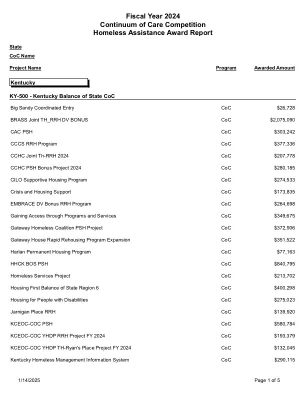
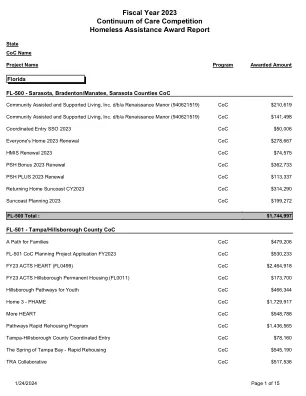
XiaoMi-AI文件搜索系统
World File Search SystemCoC



FCA US诉Kamax,C06 2024-205863-CB-密歇根州法院
原告必须首先提供歧视的“表面上的案例”。在这里,要求原告提出证据表明(1)[他]属于受保护的阶级,(2)[他]遭受了不利的就业行动,(3)[He]有资格担任该职位,(4)在某些情况下,这项工作给予了另一个人,从而引起了非法歧视的推论。[Hazle,464 Mich at463。]

认识到STCW COC 1类资格等效于
负责全球80%以上的海事行业依靠熟练的劳动力来确保安全,效率和可持续性。在海上资格的顶点,由国际海事组织(IMO)通过STCW公约管理的STCW COC 1级认证和首席工程师的STCW COC 1类认证,设定了严格的能力标准。尽管具有专业认可,但这些认证缺乏与学术硕士学位相同的等效性,这为寻求需要正式学历的基于海岸的角色的水手造成了障碍。本研究采用系统和比较研究方法来解决这一差距。分析涉及从海上学院,IMO模型课程和海事研究,工程和相关领域的学术硕士课程中收集数据。比较的关键领域包括教学大纲内容,联系时间,海上培训,实践能力和评估方法。定量数据,例如致力于培训和评估的总小时,并与领导力,技术专长和研究技能的定性比较进行了分析。研究还涉及检查实践培训的性质(例如,海上与实习或合作计划)和评估格式(例如,COC能力考试与学术论文)。合成了这些比较见解,以评估STCW COC 1类资格的学术等效性。但是,COC培训中的实际重点远远超出了学术计划的理论重点,这强调了对这些资格的正式认识的需求。调查结果表明,通过COC培训和硕士学位课程,尤其是领导力,安全管理和环境管理的能力的深度和广度有很大的重叠。这项研究主张识别STCW COC 1类认证等同于学术硕士学位,并提出将研究方法的整合到COC课程中,以弥合剩余的空白。该研究建议在IMO和学术机构之间建立合作框架,以标准化等效性,为水手们释放职业机会并增强全球海上劳动力。

PLEE 与数据决策:CoC 面临补偿
本材料全部或部分基于由美国住房和城市发展部授予 Cloudburst Consulting Group, Inc 的联邦奖项 H-19-TA-MD-0006 所支持的工作。本工作的实质和结果面向公众。美国政府及其任何雇员均不对所披露的任何信息、设备、产品或流程的准确性、完整性或实用性做任何明示或暗示的保证,也不承担任何法律责任或义务,也不表示其使用不会侵犯私有权利。本文中对任何个人、机构、公司、产品、流程、服务、商品名、商标、制造商或其他服务的引用并不构成或暗示作者、贡献者、美国政府或任何机构的认可、推荐或偏爱。本文中的观点均为作者的观点,并不一定反映 HUD 或任何联邦机构的官方立场或认可的立场。”

CoC规划项目申请详细说明:
HUD-2880 表格使用的联邦术语与 CoC 计划和项目申请中使用的术语并不完全一致。为了 CoC 计划的目的,HUD 正在澄清 HUD-2880 第 1 部分问题 1 和 2 中“特定项目或活动”和“此申请”的含义。HUD-2880 与 CoC 计划相关的法律要求意味着:任何单个组织/申请人都等于所有累积项目申请的一份申请,无论在 CoC 计划竞赛中提交了多少个单独的项目申请。因此,e-snaps HUD-2880 中的信息包括在 CoC 计划竞赛中申请资金的所有项目申请的总金额。例如,如果 XYZ 组织提交三份单独的项目申请,每份申请 100,000 美元,总金额为 300,000 美元,则 HUD-2880 第 1 部分问题 2 必须回答“是”——因为 XYZ 组织预计将获得超过 200,000 美元的援助。由于贵组织所申请的所有项目申请的总资金金额超过 200,000 美元,因此您必须填写 HUD-2880 的第 II 部分和第 III 部分。

UMP Classic (PEBB) 承保证书 (COC) 2024
致电:1-844-299-3041 周一至周五:早上 6 点至晚上 8 点;周六:早上 7 点至晚上 8 点;周日早上 8 点至晚上 8 点(太平洋时间)。如果您在美国境外,请拨打您所在国家/地区的出口代码(通常为 00),然后拨打 1-916-635-7373。聋人、聋盲人、晚期失聪和听力障碍成员致电 (TTY):1-800-428-4833 周一至周六:早上 6 点至下午 5 点;周日早上 5 点至晚上 8 点(太平洋时间)。

COC 计划 PAO 版本 - 网络卓越中心
在其职业生涯中,斯坦顿 MG 担任过多个指挥、参谋和联合职务,包括意大利维琴察第 1-508 步兵空降营战斗队排长、营人事官;德国施韦因富特第 26 步兵团第 1 营排长、作战官;肯塔基州坎贝尔堡第 1-502 步兵团助理作战官;肯塔基州坎贝尔堡第 1-502 步兵团 B 连指挥官,参与伊拉克自由行动;纽约西点军校计算机科学教员;马里兰州米德堡美国陆军网络司令部高级技术顾问;米德堡国家安全局研究员;米德堡美国网络司令部能力发展组主任;斯坦顿将军曾任驻乔治亚州戈登堡美国陆军网络保护旅指挥官、驻米德堡美国网络司令部作战副主任(J-3)。斯坦顿将军曾完成两项作战任务:在持久自由行动中担任阿富汗联合安全过渡司令部教员;在伊拉克自由行动中担任第 101 空降师第 1-502 步兵团 B 连指挥官。他获得了三个计算机科学学位:西点军校的学士学位、伊利诺伊大学的硕士学位和约翰霍普金斯大学的博士学位。他的军事教育包括步兵军官基础和高级课程、美国陆军指挥和参谋学院以及高级军事学院奖学金。他所获得的奖章和勋章对于他这个级别和服役时间的军官来说很典型。他与前妻诺米·哈里斯 (Nomi Harris) 结婚,育有三个孩子,汉娜 (Hannah)、夏洛特 (Charlotte) 和托比 (Toby)。