XiaoMi-AI文件搜索系统
World File Search SystemCosine

正弦余弦优化算法 - OAPEN
© 作者 2023。本书是开放获取出版物。开放获取 本书根据知识共享署名 4.0 国际许可证 ( http://creativecommons.org/licenses/by/4.0/ ) 的条款获得许可,允许以任何媒体或格式使用、共享、改编、分发和复制,只要您给予原作者和来源适当的信用,提供知识共享许可证的链接并指明是否进行了更改。本书中的图像或其他第三方材料包含在本书的知识共享许可证中,除非在材料的致谢中另有说明。如果材料未包含在本书的知识共享许可证中,并且您的预期用途不被法定法规允许或超出允许用途,则您需要直接从版权所有者处获得许可。本出版物中使用一般描述性名称、注册名称、商标、服务标记等。即使没有具体声明,也不意味着这些名称不受相关保护法律和法规的约束,因此可以自由使用。出版商、作者和编辑可以放心地认为,本书中的建议和信息在出版之日是真实准确的。出版商、作者或编辑均不对此处包含的材料或可能出现的任何错误或遗漏提供明示或暗示的保证。出版商对已出版地图和机构隶属关系中的司法管辖权主张保持中立。
正弦余弦优化算法 - OAPEN
© 作者 2023。本书是开放获取出版物。开放获取 本书根据知识共享署名 4.0 国际许可证 (http://creativecommons.org/licenses/by/4.0/) 的条款获得许可,允许以任何媒体或格式使用、共享、改编、分发和复制,只要您给予原作者和来源适当的信用,提供知识共享许可证的链接并指明是否进行了更改。本书中的图像或其他第三方材料包含在本书的知识共享许可证中,除非在材料的致谢中另有说明。如果材料未包含在本书的知识共享许可证中,并且您的预期用途不被法定法规允许或超出允许用途,则您需要直接从版权所有者处获得许可。本出版物中使用一般描述性名称、注册名称、商标、服务标记等。即使没有具体声明,也不意味着这些名称不受相关保护法律和法规的约束,因此可以自由使用。出版商、作者和编辑可以放心地认为,本书中的建议和信息在出版之日是真实准确的。出版商、作者或编辑均不对此处包含的材料或可能出现的任何错误或遗漏提供明示或暗示的保证。出版商对已出版地图和机构隶属关系中的司法管辖权主张保持中立。

余弦卷积神经网络及其应用
使用 c X 和基于 KL 散度的校准方法计算激活 Q 尺度 l act S 计算当前层激活的 Q 因子:1 / ( ) llll act A act MSSSS − Ω = 更新偏差项:lll act BSB = End for 计算最后一个卷积层的反量化因子:1/ l N deQ act MS =

基于余弦相似度的量子二元分类器 - IRIS
控制门 RY (0 . 49 π ) 所需的辅助量子位,q 5 是用于对数据进行幅度编码的 1 量子位寄存器,q 6 是编码标签的量子位。在 IBM 量子处理器 ibmq 16 melbourne 上运行该算法可提供 1024 次采样来对量子位 q 0 进行采样。获得的 P (1) 估计为 ˆ P = 490 / 1024 ≃ 0 . 48,则分配给 x = (0 . 884 , 0 . 468) 的标签为 y = − 1,正如预期的那样。尽管在此测试中分类正确,但与模拟器 ibm qasm simulator 的结果进行比较表明,所考虑的量子机过于嘈杂,无法通过算法 1 进行良好的分类。模拟器的输出统计数据提供 ˆ P = 273 / 1024 ≃ 0 . 27 。此结果与未分类数据向量 x 接近训练向量之间的中间点的事实一致。使用相同的训练点和新的未标记实例 x = (0 . 951 , 0 . 309)(其正确分类为 y = 1)重复实验,量子机失败。事实上 ibmq 16 melbourne 返回相对频率 ˆ P = 338 / 1024 ≃ 0 . 38 ,因此它将 x 归类为 y = − 1 。在同一个测试中,模拟器 ibm qasm simulator 返回 ˆ P = 244 / 1024 ≃ 0 . 24 正确分类。观察到的分类准确性不足取决于所考虑的量子处理器的低量子体积 1(QV = 8)。未来工作的内容可能是在更大、更可靠的硬件上进行测试(例如,具有 27 个量子比特和 QV=128 的 IBM 量子机器 ibmq montreal)。所提出的量子分类器的指数加速归因于在对数时间内有效准备量子态以及在恒定时间内执行分类本身(这取决于所需的准确性)。事实上,选择 QRAM 是出于对总体时间复杂度的明确估计,但允许使用其他有效的初始化来运行此量子分类器。

MCGNet+:基于余弦相似度的改进运动想象分类
解决运动想象分类问题一直是脑信息学领域的难题。由于计算能力和算法可用性无法满足复杂的脑信号分析,准确度和效率是过去几十年运动想象分析的主要障碍。近年来,机器学习(ML)方法的快速发展使人们能够用更有效的方法来解决运动想象分类问题。在各种ML方法中,图神经网络(GNN)方法在处理相互关联的复杂网络方面显示出了其效率和准确性。GNN的使用为从大脑结构连接中提取特征提供了新的可能性。在本文中,我们提出了一种名为MCGNet +的新模型,它提高了我们之前的模型MutualGraphNet的性能。在这个最新的模型中,输入列的互信息形成了列间余弦相似度计算的初始邻接矩阵,从而在每次迭代中生成一个新的邻接矩阵。动态邻接矩阵与时空图卷积网络(ST-GCN)相结合,比不变矩阵模型具有更好的性能。实验结果表明,MCGNet+具有足够的鲁棒性来学习可解释的特征,并且优于目前最先进的方法。

基于连续分式余弦变换的自适应语言合成模型
现代语音信号识别系统集成了信号处理、模式识别、自然语言和语言学等现代科学领域的技术。这些系统在信号处理中得到了广泛的应用,推动了数字信号处理 (DSP) 的真正繁荣。以前,该领域以面向矢量的处理器和代数数学仪器为主,而当前一代 DSP 依赖于复杂的统计模型并使用复杂的软件进行实际实现。现代语音信号识别模型能够理解操作环境中由数十万个单词组成的词典的连续输入语言。语音信号的线性预测分析历来是语音分析技术中最重要的。其基础是滤波源模型,它是一种理想的线性滤波器。

Kathiravan 的研究将为澳大利亚航天局的优先领域做出巨大贡献,即地球观测技术的地球应用
cosine 将物理和技术相结合,为我们的客户带来创新的测量解决方案。cosine 开发和构建用于太空、空中和地面的光学和现场测量系统。这些系统用于科学、工业、医疗、环境、能源、农业/食品、安全、半导体和空间应用,客户范围从小型高科技公司到欧洲航天局和美国宇航局。cosine 团队由 50 多名受过高等教育的人组成,他们与客户密切合作,透明地进行开发。凭借我们在不同技术领域的丰富经验,我们提供开箱即用的测量解决方案。技术涵盖应用物理领域,在光谱学、激光系统和辐射成像系统方面拥有丰富的经验。我们利用我们在物理、电子和软件方面的知识以创新的方式解决问题。我们提供高光谱成像产品,

M.Tech课程
总数of Lectures –28 Lecture wise breakup Number of Lectures 1 FOURIER TRANSFORMS Fourier Integral as the limit of a Fourier series, Dirichlet conditions, Fourier Integral Theorem, Fourier sine and cosine integrals, Fourier transform and its inverse, Basic properties, Convolution Theorem, Parseval's relation, Dirac Delta Function and its Fourier transform, Fourier transform of partial derivatives, Fourier cosine and sine傅立叶余弦和正弦变换的变换及其逆,基本特性,对工程问题的应用。
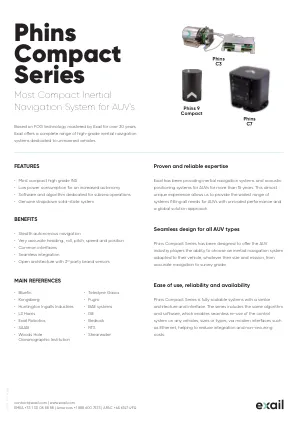
phins紧凑型系列
(1)CEP:50%的循环误差概率。DVL辅助位置精度取决于DVL性能。(2)典型的性能,取决于外部传感器特性(3)RMS值。(4)割线latitute = 1 / cosine latitude < / div>
2.Mech-r23-ii.B.Tech syllabus.pdf
单元I:拉普拉斯变换:某些功能的定义和拉普拉斯变换 - 转移定理;衍生物和积分的拉普拉斯转换 - 单位步骤功能 - 迪拉克的dilta函数,周期性函数。反向拉普拉斯转换-Convolution定理(无证明)。应用程序:使用拉普拉斯变换求解普通微分方程(初始值问题)。单元-II:傅立叶级数和傅立叶变换:傅立叶序列:简介,周期功能,一系列周期函数,差异和奇数函数,偶数和奇数功能,间隔的变化,半范围傅立叶正弦和余弦系列。傅立叶变换:傅立叶积分定理(无证明) - 曲线和余弦的正弦和余弦变换 - 跨性别者(文本book-i中的第22.5条) - 逆变换 - 卷积定理(没有证明)有限的傅立叶变换。