XiaoMi-AI文件搜索系统
World File Search SystemFlow

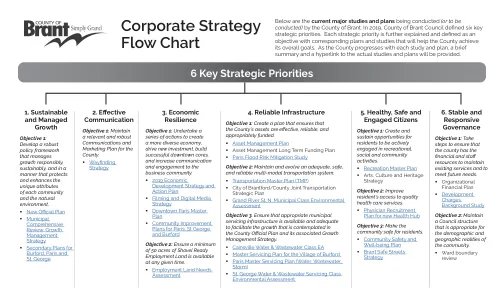

碳感知的最佳功率流
摘要 - 为了促进电能部门的有效脱碳化,本文引入了用于电力系统决策的通用碳感知最佳功率流(C-OPF)方法,该方法考虑了电网碳足迹的主动管理。建立在常规的最佳功率流(OPF)模型的基础上,提出的C-OPF模型进一步构建了碳发射流程方程和约束以及与碳相关的目标,以使电力电网的电力流量和碳发射流相比。本质上,提出的C-OPF可以看作是OPF的碳意识概括。此外,本文严格确定了保证碳排放流程方程的可行性和解决方案唯一性的条件,并提出了一种重新制定技术,以解决C-OPF模型中未确定的功率流方向的关键问题。此外,开发了两个用于能源储能系统的新型碳足迹模型,并将其整合到C-OPF方法中。数值模拟证明了C-OPF方法的特性和有效性。




钛铈电极-解耦氧化还原流...
燃烧涡轮总输出 (MWe) 2 x 238 2 x 169 HRSG 蒸汽循环 (psig/o F/o F) 2,393/1,085/1,085 N/A 1772/1050/1050 蒸汽涡轮功率 (MWe) 263 213 N/A 185 CO 2 回收负荷 (MWe) N/A 28 N/A 平衡。电厂负荷 (MWe) 14 16 18 19 电厂总负荷 (MW) 740 690 338 523 电厂净负荷 (MW) 727 646 320 504 LHV 电厂效率 (%) 59.4 52.8 35.9 53.6 LHV 热耗率 (Btu/kWh) 5,743 6,462 9,493 6,363 LHV CT 效率 (%) 39.0 35.9 NOx 控制 LNB 和 SCR LNB LNB 和 SCR CT 涡轮机规格 F 型框架 F 型框架 (501F-D2) 出口温度 ( o F) 1,156 1,116 电厂最低调节负荷 (%) 22.0 N/A 50.0 22.0 上升速率 (MW/分钟) 80.0 N/A tbd tbd 启动时间,RR 热(分钟) 25 > 25 tbd tbd 电气规格 电网互连(kV) 345 138

肠杆菌科细菌鉴定流程图
H2S + K/A 可能的生物 变形杆菌、爱德华氏菌、沙门氏菌、弗氏柠檬酸杆菌 你对这些知识了解多少? 2-4 进行并解释吲哚、MR-VP、柠檬酸盐、尿素酶、运动性和蔗糖发酵试验。陈述这些试验的目的和原理,并根据结果识别肠杆菌科的成员。描述细菌和病毒的繁殖和增殖方式。利用无菌技术安全处理微生物。应用各种实验室技术识别微生物的类型。识别主要微生物群的结构特征,比较原核细胞和真核细胞,对比各种微生物群的生理和生物化学。培养基:蔗糖发酵液、胰蛋白胨肉汤、MR-VP 肉汤、柠檬酸盐斜面、尿素斜面、运动琼脂。设备:接种线和接种环、原种培养物(产气克雷伯菌、大肠杆菌、奇异变形杆菌、肺炎克雷伯菌)。试剂:Kovac 试剂、甲基红、Barritt 试剂 A 和 B。肠杆菌科的革兰氏阴性杆菌在临床微生物实验室中很常见。这些细菌通常被称为“肠道菌”,是正常肠道微生物群的一部分。由于它们具有相似的革兰氏染色结果和细胞形态,因此需要进行生化测试以进行识别。编码在细菌基因组中的生化酶为每种菌种形成独特的“指纹”。从历史上看,IMViC 测试用于识别肠道菌。该首字母缩略词代表吲哚、甲基红、Voges-Proskauer 和柠檬酸盐测试。大肠杆菌曾被用作食物和水源中粪便污染的指标。虽然肠杆菌与大肠杆菌相似,但它在土壤和草丛中广泛存在,因此它是一种不太可靠的指标。大肠杆菌、克雷伯氏菌、肠杆菌和变形杆菌通常是正常肠道微生物群的一部分,但在不同情况下会导致疾病。真正的肠道病原体包括沙门氏菌,它因“食物中毒”而导致伤寒和胃肠炎,以及志贺氏菌,它因“食物中毒”而导致细菌性痢疾。市面上有 Enterotube 和 API20E 等商业试剂盒系统可用于识别肠杆菌科。此练习需要微型细菌分析练习小组工作。小组中的每个人都将使用一种彩色点培养物。有四种蔗糖发酵液测试可供选择。1. 获取蔗糖发酵液,其中含有糖和 pH 指示剂。2. 使用便签创建标签,上面写有您的姓名、指定的生物和培养基类型。 3. 从琼脂平板上取少量细菌,加入到每个发酵管中。 4. 培养发酵管直至下一次实验。培养后,观察每个蔗糖发酵管的外观: - 黄色发酵液:阳性(发酵蔗糖) - 红色发酵液:阴性(不发酵蔗糖) 将发酵管丢弃在实验室后面的废弃架中。 尿素酶测试 获取尿素琼脂斜面并贴上您的姓名、指定生物和培养基类型标签。 使用无菌环将细菌添加到整个斜面中。 孵育直到下一次实验课。 孵育后,观察尿素培养基的颜色变化: - 热粉色肉汤:阳性(产生尿素酶) - 淡鲑鱼肉汤:阴性(不产生尿素酶) 将尿素斜面丢弃在实验室后面的废弃架中。 吲哚测试 获取胰蛋白胨肉汤并贴上您的姓名、指定生物和培养基类型标签。 使用无菌环向每种培养物中添加少量细菌。 孵育直到下一次实验课。孵育后,向每种培养物中加入 10 滴 Kovac 试剂: - 红色环:阳性(产生吲哚) - 无红色环:阴性(不产生吲哚) 将胰蛋白胨管丢弃在通风橱中。MR-VPP 测试 获得一个 MRVP 肉汤管并贴上标签,写上您的名称、指定生物和培养基类型。使用无菌环向每种培养物中添加细菌。孵育至下一次实验课。孵育后,观察 MRVP 肉汤的外观: - 红色环:阳性(通过混合酸途径发酵葡萄糖) - 无红色环:阴性(不通过混合酸途径发酵葡萄糖) 1. 首先准备用于细菌分析的测试培养基。这涉及使用无菌接种环获取少量细菌并接种 MR-VP 肉汤。 2. 将接种管孵育至下一次实验课,之后将进行几项测试以分析细菌特性。 3. **MR 测试**:培养后,使用移液管将接种的肉汤分离到标有“MR”和“VP”的两个管中。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样品被丢弃在实验室的废弃架上。测试结果表明:大肠杆菌和奇异变形杆菌的运动性呈阳性,而肺炎克雷伯氏菌和沙门氏菌呈阴性。由于缺乏供应,未对志贺氏菌进行测试。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的脲酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯氏菌和大肠杆菌的测试结果呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他发现了主要组织相容性复合体基因,这些基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。Fc 受体由 Benacerraf 发现,同时还发现了 T 细胞和 B 细胞识别抗原并合作产生抗体反应的独特方式。尿素酶测试 获取尿素琼脂斜面并贴上您的名称、指定生物和培养基类型标签。用无菌环将细菌添加到整个斜面中。孵育至下次实验课。孵育后,观察尿素培养基的颜色变化: - 热粉色肉汤:阳性(产生尿素酶) - 淡鲑鱼色肉汤:阴性(不产生尿素酶) 将尿素斜面丢弃在实验室后面的废弃架中。吲哚测试 获取胰蛋白胨肉汤并贴上您的名称、指定生物和培养基类型标签。用无菌环向每种培养物中添加少量细菌。孵育至下次实验课。孵育后,向每种培养物中加入 10 滴 Kovac 试剂: - 红色环:阳性(产生吲哚) - 无红色环:阴性(不产生吲哚) 将胰蛋白胨管丢弃在通风橱中。 MR-VPP 测试 准备一个 MRVP 肉汤管,并在上面贴上您的姓名、指定生物和培养基类型标签。使用无菌环将细菌添加到每个培养物中。孵育至下一次实验。孵育后,观察 MRVP 肉汤的外观: - 红色环:阳性(通过混合酸途径发酵葡萄糖) - 无红色环:阴性(不通过混合酸途径发酵葡萄糖) 1. 首先准备用于细菌分析的测试培养基。这涉及使用无菌接种环获取少量细菌并接种 MR-VP 肉汤。 2. 孵育接种管直至下一次实验,之后将进行几项测试以分析细菌特性。 3. **MR 测试**:孵育后,使用转移吸量管将接种的肉汤分成两个标记为“MR”和“VP”的管。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样本被丢弃在实验室的废弃架上。检测结果表明:大肠杆菌和奇异变形杆菌运动性呈阳性,而肺炎克雷伯菌和沙门氏菌呈阴性。由于缺乏志贺氏菌,未进行检测。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的脲酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯菌和大肠杆菌的检测呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他确定了主要组织相容性复合体基因,该基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。 Fc 受体以及 T 细胞和 B 细胞识别抗原和协作产生抗体反应的独特方式都是由 Benacerraf 发现的。尿素酶测试 获取尿素琼脂斜面并贴上您的名称、指定生物和培养基类型标签。用无菌环将细菌添加到整个斜面中。孵育至下次实验课。孵育后,观察尿素培养基的颜色变化: - 热粉色肉汤:阳性(产生尿素酶) - 淡鲑鱼色肉汤:阴性(不产生尿素酶) 将尿素斜面丢弃在实验室后面的废弃架中。吲哚测试 获取胰蛋白胨肉汤并贴上您的名称、指定生物和培养基类型标签。用无菌环向每种培养物中添加少量细菌。孵育至下次实验课。孵育后,向每种培养物中加入 10 滴 Kovac 试剂: - 红色环:阳性(产生吲哚) - 无红色环:阴性(不产生吲哚) 将胰蛋白胨管丢弃在通风橱中。 MR-VPP 测试 准备一个 MRVP 肉汤管,并在上面贴上您的姓名、指定生物和培养基类型标签。使用无菌环将细菌添加到每个培养物中。孵育至下一次实验。孵育后,观察 MRVP 肉汤的外观: - 红色环:阳性(通过混合酸途径发酵葡萄糖) - 无红色环:阴性(不通过混合酸途径发酵葡萄糖) 1. 首先准备用于细菌分析的测试培养基。这涉及使用无菌接种环获取少量细菌并接种 MR-VP 肉汤。 2. 孵育接种管直至下一次实验,之后将进行几项测试以分析细菌特性。 3. **MR 测试**:孵育后,使用转移吸量管将接种的肉汤分成两个标记为“MR”和“VP”的管。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样本被丢弃在实验室的废弃架上。检测结果表明:大肠杆菌和奇异变形杆菌运动性呈阳性,而肺炎克雷伯菌和沙门氏菌呈阴性。由于缺乏志贺氏菌,未进行检测。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的脲酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯菌和大肠杆菌的检测呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他确定了主要组织相容性复合体基因,该基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。 Fc 受体以及 T 细胞和 B 细胞识别抗原和协作产生抗体反应的独特方式都是由 Benacerraf 发现的。观察尿素培养基的颜色变化: - 热粉色肉汤:阳性(产生尿素酶) - 淡鲑鱼肉汤:阴性(不产生尿素酶) 将尿素斜面丢弃在实验室后面的废弃架中。吲哚测试 获取胰蛋白胨肉汤并贴上您的名称、指定生物和培养基类型标签。使用无菌环向每种培养物中添加少量细菌。孵育至下一次实验课。孵育后,向每种培养物中添加 10 滴 Kovac 试剂: - 红环:阳性(产生吲哚) - 无红环:阴性(不产生吲哚) 将胰蛋白胨管丢弃在通风橱中。MR-VPP 测试 获取 MRVP 肉汤管并贴上您的名称、指定生物和培养基类型标签。使用无菌环向每种培养物中添加细菌。孵育至下一次实验课。培养后,观察 MRVP 肉汤的外观: - 红环:阳性(通过混合酸途径发酵葡萄糖) - 无红环:阴性(不通过混合酸途径发酵葡萄糖) 1. 首先准备用于细菌分析的测试培养基。这涉及使用无菌接种环获取少量细菌并接种 MR-VP 肉汤。 2. 将接种管培养至下一个实验环节,之后将进行几项测试以分析细菌特性。 3. **MR 测试**:培养后,使用移液器将接种的肉汤分离到标有“MR”和“VP”的两个管中。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样品被丢弃在实验室的废弃架中。测试结果表明:大肠杆菌和奇异变形杆菌具有阳性运动能力,而肺炎克雷伯菌和沙门氏菌则呈阴性。由于缺乏供应,未对志贺氏菌进行测试。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的尿素酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯菌和大肠杆菌的检测结果呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他确定了主要组织相容性复合体基因,该基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。Benacerraf 发现了 Fc 受体,以及 T 细胞和 B 细胞识别抗原并协作产生抗体反应的独特方式。观察尿素培养基的颜色变化: - 热粉色肉汤:阳性(产生尿素酶) - 淡鲑鱼肉汤:阴性(不产生尿素酶) 将尿素斜面丢弃在实验室后面的废弃架中。吲哚测试 获取胰蛋白胨肉汤并贴上您的名称、指定生物和培养基类型标签。使用无菌环向每种培养物中添加少量细菌。孵育至下一次实验课。孵育后,向每种培养物中添加 10 滴 Kovac 试剂: - 红环:阳性(产生吲哚) - 无红环:阴性(不产生吲哚) 将胰蛋白胨管丢弃在通风橱中。MR-VPP 测试 获取 MRVP 肉汤管并贴上您的名称、指定生物和培养基类型标签。使用无菌环向每种培养物中添加细菌。孵育至下一次实验课。培养后,观察 MRVP 肉汤的外观: - 红环:阳性(通过混合酸途径发酵葡萄糖) - 无红环:阴性(不通过混合酸途径发酵葡萄糖) 1. 首先准备用于细菌分析的测试培养基。这涉及使用无菌接种环获取少量细菌并接种 MR-VP 肉汤。 2. 将接种管培养至下一个实验环节,之后将进行几项测试以分析细菌特性。 3. **MR 测试**:培养后,使用移液器将接种的肉汤分离到标有“MR”和“VP”的两个管中。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样品被丢弃在实验室的废弃架中。测试结果表明:大肠杆菌和奇异变形杆菌具有阳性运动能力,而肺炎克雷伯菌和沙门氏菌则呈阴性。由于缺乏供应,未对志贺氏菌进行测试。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的尿素酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯菌和大肠杆菌的检测结果呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他确定了主要组织相容性复合体基因,该基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。Benacerraf 发现了 Fc 受体,以及 T 细胞和 B 细胞识别抗原并协作产生抗体反应的独特方式。向每种培养物中加入 10 滴 Kovac 试剂: - 红色环:阳性(产生吲哚) - 无红色环:阴性(不产生吲哚) 将胰蛋白胨管丢弃在通风橱中。MR-VPP 测试 获得一个 MRVP 肉汤管并贴上标签,写上您的名称、指定生物和培养基类型。使用无菌环向每种培养物中添加细菌。孵育至下一次实验课。孵育后,观察 MRVP 肉汤的外观: - 红色环:阳性(通过混合酸途径发酵葡萄糖) - 无红色环:阴性(不通过混合酸途径发酵葡萄糖) 1. 首先准备用于细菌分析的测试培养基。这涉及使用无菌接种环获取少量细菌并接种 MR-VP 肉汤。 2. 将接种管孵育至下一次实验课,之后将进行几项测试以分析细菌特性。 3. **MR 测试**:培养后,使用移液管将接种的肉汤分离到标有“MR”和“VP”的两个管中。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样品被丢弃在实验室的废弃架上。测试结果表明:大肠杆菌和奇异变形杆菌的运动性呈阳性,而肺炎克雷伯氏菌和沙门氏菌呈阴性。由于缺乏供应,未对志贺氏菌进行测试。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的脲酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯氏菌和大肠杆菌的测试结果呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他发现了主要组织相容性复合体基因,这些基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。Fc 受体由 Benacerraf 发现,同时还发现了 T 细胞和 B 细胞识别抗原并合作产生抗体反应的独特方式。向每种培养物中加入 10 滴 Kovac 试剂: - 红色环:阳性(产生吲哚) - 无红色环:阴性(不产生吲哚) 将胰蛋白胨管丢弃在通风橱中。MR-VPP 测试 获得一个 MRVP 肉汤管并贴上标签,写上您的名称、指定生物和培养基类型。使用无菌环向每种培养物中添加细菌。孵育至下一次实验课。孵育后,观察 MRVP 肉汤的外观: - 红色环:阳性(通过混合酸途径发酵葡萄糖) - 无红色环:阴性(不通过混合酸途径发酵葡萄糖) 1. 首先准备用于细菌分析的测试培养基。这涉及使用无菌接种环获取少量细菌并接种 MR-VP 肉汤。 2. 将接种管孵育至下一次实验课,之后将进行几项测试以分析细菌特性。 3. **MR 测试**:培养后,使用移液管将接种的肉汤分离到标有“MR”和“VP”的两个管中。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样品被丢弃在实验室的废弃架上。测试结果表明:大肠杆菌和奇异变形杆菌的运动性呈阳性,而肺炎克雷伯氏菌和沙门氏菌呈阴性。由于缺乏供应,未对志贺氏菌进行测试。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的脲酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯氏菌和大肠杆菌的测试结果呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他发现了主要组织相容性复合体基因,这些基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。Fc 受体由 Benacerraf 发现,同时还发现了 T 细胞和 B 细胞识别抗原并合作产生抗体反应的独特方式。之后将进行几项测试以分析细菌特性。 3. **MR 测试**:培养后,使用移液器将接种的肉汤分离到两个标记为“MR”和“VP”的管中。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样品被丢弃在实验室的废弃架上。测试结果表明:大肠杆菌和奇异变形杆菌的运动性呈阳性,而肺炎克雷伯氏菌和沙门氏菌呈阴性。由于缺乏供应,没有测试志贺氏菌。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的脲酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯氏菌和大肠杆菌的检测结果呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他发现了主要组织相容性复合体基因,这些基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。Fc 受体由 Benacerraf 发现,同时还发现了 T 细胞和 B 细胞识别抗原并合作产生抗体反应的独特方式。之后将进行几项测试以分析细菌特性。 3. **MR 测试**:培养后,使用移液器将接种的肉汤分离到两个标记为“MR”和“VP”的管中。将甲基红试剂添加到“MR”管中,并记录任何反应或结果。琼脂样品被丢弃在实验室的废弃架上。测试结果表明:大肠杆菌和奇异变形杆菌的运动性呈阳性,而肺炎克雷伯氏菌和沙门氏菌呈阴性。由于缺乏供应,没有测试志贺氏菌。大多数菌株的蔗糖发酵呈阴性,但奇异变形杆菌除外,其发酵呈阳性。不同细菌的脲酶活性各不相同,奇异变形杆菌呈阳性。不同物种的吲哚生成也不同,肺炎克雷伯氏菌和大肠杆菌的检测结果呈阳性。在 1940 年代的研究中,Baruj Benacerraf 博士对免疫学做出了重大贡献。他发现了主要组织相容性复合体基因,这些基因对于区分自身和非自身至关重要。他的工作还阐明了巨噬细胞的吞噬活性并描述了 IgG 亚类的功能。Fc 受体由 Benacerraf 发现,同时还发现了 T 细胞和 B 细胞识别抗原并合作产生抗体反应的独特方式。

