XiaoMi-AI文件搜索系统
World File Search SystemHidden

学术“俘获”?企业隐性成本...
Ioannis Lianos * 摘要 本文探讨了企业资助如何影响法医经济学应用和学术研究环境中的竞争政策研究,最终影响竞争法的设计和实施。分析建立在竞争经济学包含两个截然不同但相互关联日益密切的群体的前提上:在公共和私营部门工作的法医经济学家,他们将经济原则应用于具体的竞争法执法案件;以及通过理论工作、实证研究和实验方法产生广泛适用的经济知识的学术经济学家。 分析分为四个部分。首先,它追溯了经济专家和顾问作为一个独特职业的出现,解释了这一发展如何将经济研究中的偏见问题推到风口浪尖,最初是在诉讼中提出的法医经济学中。其次,它研究了各种形式的专家偏见,超越了竞争监管应用经济专业知识的市场,涵盖了更广泛的竞争经济思想市场。第三,本文探讨了这些偏见不仅可能源于市场动态,也可能源于竞争经济学专业知识的集中结构,同时考虑到供需因素以及影响竞争政策话语的战略努力。最后,本文评估了现有的遏制法医经济学专业知识市场和竞争经济学知识市场中的偏见和俘获的工具,并提出了未来的监管改革,包括大型企业资助者强制披露资金和匹配资金要求,以使企业激励与公众对无偏见研究的兴趣保持一致。

存在隐藏信息的量子因果推断...
量子因果关系是一个新兴的研究领域,它有可能极大地促进我们对量子系统的理解。在本文中,我们提出了一种新的理论框架,通过利用熵原理将量子信息科学与因果推理相结合。为此,我们利用隐藏原因的熵和观测变量的条件互信息之间的权衡,开发了一种可扩展的算法方法,用于在量子系统中存在潜在混杂因素(共同原因)的情况下推断因果关系。作为一种应用,我们考虑一个由三个纠缠量子比特组成的系统,并通过单独的噪声量子信道传输第二和第三个量子比特。在这个模型中,我们验证了第一个量子比特是一个潜在混杂因素,也是第二和第三个量子比特的共同原因。相反,当准备好两个纠缠量子比特并将其中一个通过噪声信道发送时,不存在共同的混杂因素。我们还证明了,当变量为经典变量时,通过密度矩阵而不是联合概率分布利用变量之间的量子依赖性,所提出的方法优于 Tubingen 数据库的经典因果推理结果。因此,所提出的方法以原则性的方式统一了经典和量子因果推理。

揭露网络流量中的隐藏威胁
与应用相关的元数据提取进行深度数据包检查。应用程序元数据智能(AMI)扩展了从Gigamon应用程序可视化和过滤得出的应用层可见性,并支持获取应用程序行为的全面方法。它提供了有关东西方流量的宝贵信息,而无需捕获整个数据包。元数据提取有助于减少正在处理的数据量,从而使其更容易进行分析。它包含诸如源和目标IP地址,端口,协议,时间戳以及威胁检测和调查中使用的其他相关上下文信息之类的属性。Gigamon AMI支持近7,000个协议,应用程序,用户行为和L4 – L7属性,这些属性涉及超过4,000个标准和自定义应用程序。

遗产PAM的隐藏危险 - 饲养者
James Scobey是Keeper Security,Inc。的首席信息安全官(CISO)他之前曾在美国证券交易委员会(SEC)担任首席信息安全官。在SEC担任CISO之前,Scobey曾担任Sigmacyber的总裁兼首席执行官(CEO),首席技术官(CTO)兼SEC网络安全运营助理总监,以及联邦资助的研究和开发组织Miter的主要系统工程师和网络性能系统工程师。Scobey还曾在S2I2,联邦数据系统,USMAX Corporation,轻型专业IT服务和SMS数据产品组中担任领导力和工程角色。

约旦的隐性经济:MIMIC 方法
摘要:本文采用多指标多原因 (MIMIC) 方法确定 1980 年至 2018 年期间约旦隐性经济的年度规模和增长情况。我们发现,约旦隐性经济的主要因果变量是:女性劳动力参与率、通货膨胀率、失业率、总税收和预算赤字。这些因果变量的增长增加了约旦的隐性经济。根据我们的研究结果,1980 年至 2018 年隐性经济的估计平均值占官方 GDP 的 17.6%。因此,它占官方 GDP 的很大一部分。此外,我们的结果表明约旦隐性经济的规模从 1980 年的 11.8% 增加到 2018 年的 22.4%。总体结果可以帮助约旦的政策制定者打击和减少隐性经济的规模。

隐陪集及其在不可克隆密码学中的应用
量子力学的不可克隆原理断言量子信息不能被一般复制。这一原理对量子密码学有着深远的影响,因为它从根本上限制了恶意方可以实施的策略。其中一个影响是,量子信息可以实现经典加密无法实现的加密任务,最著名的例子就是信息论安全的密钥分发 [BB84]。除此之外,不可克隆原理还开辟了一条令人兴奋的途径来实现具有某种不可克隆性的加密任务,例如量子货币 [Wie83、AC12、FGH+12、Zha19a、Kan18]、用于数字签名的量子令牌 [BS16]、程序的复制保护 [Aar09、ALL+20、CMP20],以及最近的不可克隆加密 [Got02、BL19] 和解密 [GZ20]。在这项工作中,我们重新审视了 Aaronson 和 Christiano 提出的隐藏子空间思想,该思想已用于上述几个应用。我们提出了这一思想的概括,其中涉及隐藏陪集(仿射子空间),并展示了该思想在签名令牌、不可克隆解密和复制保护中的应用。给定一个子空间 𝐴 ⊆ 𝔽 𝑛 2 ,相应的子空间状态定义为子空间 𝐴 中所有字符串的均匀叠加,即
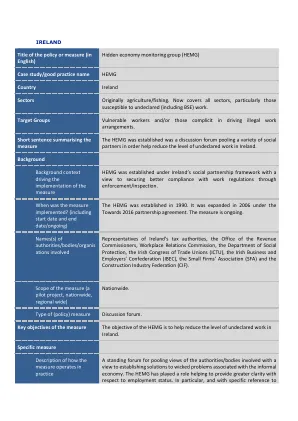
隐藏的经济监测组(HEMG)
尽管无法获得有关其使用或影响的数据,但确定个人的就业或自身就业状况的实践守则仍在爱尔兰的相关部门和执法机构继续使用(例如,与收入有关,社会保护部)。这可能被认为是与解决BSE的直接相关性的下摆的实现。

2020 年西巴尔干地区的隐性经济:
1 SELDI 选择使用“隐性”经济这一术语来表示参与其中的商业实体和工作者意图故意隐藏其部分或全部经济活动。它通常涉及隐藏合法(灰色经济)和非法(黑色经济)活动。然而,包括欧盟委员会使用的定义在内的最常见的定义将隐性经济称为非正规或未申报的经济,并将其定义为本质上合法但为逃避税收或其他监管而全部或部分未向公共当局申报的经济活动。在本文和其他 SELDI 论文中,我们交替使用“隐性”、“未申报”、“灰色”、“非正规”等词。 2 Borlea, S., Achim, M. (2017),腐败、影子经济和经济增长:对欧盟国家的实证调查。 3 OECD/ETF/EU/EBRD (2019),《中小企业政策指数:西巴尔干和土耳其 2019 年:评估《欧洲小企业法》实施情况》,《中小企业政策指数》,OECD 出版社,巴黎,第 602 页。 4 欧盟委员会 (2019),《阿尔巴尼亚、黑山、北马其顿、塞尔维亚、土耳其、波斯尼亚和黑塞哥维那以及科索沃 2019 年经济改革计划》,机构文件 107。 5 Peci, B. (2019),《非正规经济:科索沃肩上的魔鬼》,Prishtina Insight。 6 Vladimirov, M. 等人 (2018),《俄罗斯在巴尔干半岛的经济足迹。腐败与国家俘获风险》,索非亚:民主研究中心。

伪造零件 - 检测隐藏威胁
飞行安全基金会是一个致力于改善航空安全的国际会员组织。该基金会是非盈利和独立的,成立于 1945 年,旨在满足航空业对中立信息交换中心传播客观安全信息的需求,以及对一个可信和知识渊博的机构识别安全威胁、分析问题并提出切实可行的解决方案的需求。自成立以来,基金会一直致力于公众利益,对航空安全产生积极影响。如今,基金会为 75 个国家的近 600 个成员组织提供领导。

旋毛虫病:肉类消费中的隐藏威胁
摘要 旋毛虫是一种引起旋毛虫病的蛔虫,是全球主要的健康问题。这种疾病的主要传播方式是食用受感染牲畜的生肉或未煮熟的肉,而野猪在传播这种疾病方面发挥的作用越来越大。这种疾病会出现多种症状,如心肌梗塞、胃部不适和神经系统受累。旋毛虫物种的生命周期很复杂,包括肠道阶段和迁徙阶段。旋毛虫病在世界范围内并不常见,但它仍然是一个令人担忧的问题,特别是在食用生肉或未煮熟的肉很常见的欠发达国家。旋毛虫物种在世界各地的分布不同,欧洲的旋毛虫更常见。旋毛虫幼虫的感染期为肌肉期。这会导致组织损伤和严重炎症。由于幼虫体型小,检测方法有限,即使在没有记录病例的情况下,仍然很难识别受污染的肉类。旋毛虫病疫苗的开发采用了多种技术,包括 DNA、合成肽、减毒活疫苗和重组蛋白疫苗。抗原、佐剂的选择以及动物物种间免疫反应的变化对疫苗的生产提出了挑战。未来的工作应集中于开发基因工程工具和理解免疫逃避机制。引文 Arshad M、Maqsood S、Yaqoob R、Iqbal H、Rayshan AR、Mohsin R、Tahir I、Saleha Tahir、Shahid S、Anwar A 和 Qamar W,2023 年。旋毛虫病:肉类消费中的隐藏威胁。在:Abbas RZ、Hassan MF、Khan A 和 Mohsin M(编辑),人畜共患病,Unique Scientific Publishers,巴基斯坦费萨拉巴德,第 2 卷:306-318。 https://doi.org/10.47278/book.zoon/2023.72 章节历史 收稿日期:2023 年 1 月 28 日 修订日期:2023 年 4 月 15 日 接受日期:2023 年 7 月 20 日