XiaoMi-AI文件搜索系统
World File Search SystemIma

预测和健康管理在航空电子设备中的应用...
摘要。目前,大多数飞机航电系统都是基于报告故障或定期系统更换进行维护的。然而,武器平台采购和保障需求的变化推动了预测与健康管理(PHM)概念从机械到电子系统再到航电系统维护的演变。同时,随着航电设计复杂性的不断提高,综合模块化航电(IMA)应运而生。IMA设计理念的出现标志着航电系统从分布式联合架构逐渐过渡到集成架构,也为PHM技术应用于航电系统提供了基础。本文综述了预测与健康管理系统技术在航电系统中的应用及研究现状。

综合模块化航空电子架构指标
集成模块化航空电子 (IMA) 架构是军用航空航天工业中一个新兴的概念,它已在商业领域成功实施。高度模块化的架构允许多个航空应用程序在同一硬件上执行,这要归功于航空无线电公司 (ARINC) 定义的标准。系统架构师负责设计和利用 IMA 架构来满足利益相关者设定的要求。他们在工作中非常依赖经验、系统知识和设计模式。本论文旨在为系统架构师在航空航天工业中开发 IMA 架构时找到相关指标。我们进行了一项指标调查,重点关注航空航天和密切相关的行业,并将其扩展到软件和实时指标。为了找到一到三个指标,我们与领域专家团队一起进行了多次演示和放映。选择了三个指标:使用香农熵的结构复杂性、不稳定性和抽象性指标以及复杂性和耦合性指标。我们详细描述并实施了这些指标。创建了一个小规模系统,以协助并更好地理解指标如何测量以及测量什么。所选指标是否适用于航空航天业的系统架构师仍有待实证验证。提出了一个建议的验证过程以供未来工作使用。
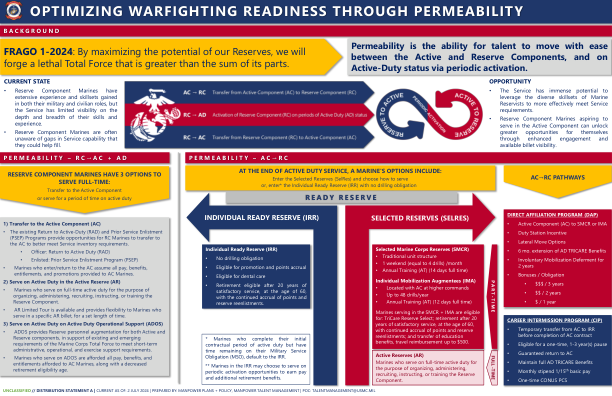
渗透性是指人才在现役和预备役部队之间轻松流动的能力,以及通过定期激活保持现役状态的能力。
在 SMCR + IMA 服役的海军陆战队员有资格享受:TriCare Reserve Select;服役 20 年后,在 60 岁时退休,继续累积积分和重新入伍预备役;以及教育福利转移,最高 500 美元的差旅报销。

交易账簿的基本面审查:内部模型方法的采用
输出底线旨在应用于第一支柱下所有风险类型的集团/顶层层面。某些司法管辖区的银行将受到输出底线的制约,因为相对于其交易足迹而言,其信贷组合规模要大得多,而交易足迹往往主导着底线消耗。因此,交易账簿资本部分的潜在收益通常有限,而更复杂的风险建模方法带来的好处也受到限制。银行指出,这消除了他们投资 IMA 的动力,因为在输出底线的背景下,资本效率方面的投资回报通常可以忽略不计。输出底线将在大多数司法管辖区分阶段实施(例如,在英国和欧盟大约需要五年时间),但加拿大等一些司法管辖区并未分阶段实施,这使得 IMA 成为一个更不具吸引力的选择。

Li, L.-L., Lou, J.-L., Tseng, M.-L., Lim, MK 和 Tan, RR (2022) 一种用于平衡运营成本的混合动态经济环境调度模型
平衡可再生能源运行成本与污染物排放的混合动态经济环境调度模型:一种新的改进蜉蝣算法摘要本研究提出一种结合火电机组、风电机组、光伏和储能装置的混合动态经济环境调度模型,在稳定可再生能源出力的前提下,实现运行成本与污染物排放的平衡。随着越来越多的可再生能源接入电网,大多数研究都针对经济和环境问题进行优化调度,而忽略了可再生能源出力的稳定性。针对可再生能源出力不稳定的问题,提出一种风光稳定出力策略,并利用储能装置合理控制可再生能源调度功率。改进适应度函数,提出一种采用混沌初始化、惯性权重和变异策略的改进蜉蝣(IMA)算法来寻优,并在两个不同配置的系统上验证了算法的性能。此外,还考虑了功率平衡、各发电设备出力、储能装置能量等约束。结果表明:IMA算法的运行成本分别比MA、MFO和PSO算法降低4.12%、13.21%和15.14%,采用IMA算法的模型能有效实现经济与环境的平衡并获得稳定的可再生能源出力。该研究为多种可再生能源接入条件下电网的稳定运行提供了有益参考。

未来航空电子架构的新挑战。
航空电子系统在飞机成本中所占的比例越来越大:民用飞机占 35% 至 40%,军用飞机占 50% 以上。这些系统负责各种应用,例如导航、制导、稳定性、燃料管理、空中/地面通信、乘客娱乐等。它们的复杂性不断增加(需要集成的功能越来越多,飞机成为真正的信息系统)。与此同时,通信和信息管理技术也在不断发展,新的航空电子解决方案也不断涌现。现代民用(B787、A350)和军用(阵风、鹰狮、A400M 等)航空电子系统的实施飞机倾向于依赖 IMA(集成模块化航空电子)架构,而不是更经典的联合架构。在联合架构中,每个系统都有私有的航空电子资源,而在 IMA 架构中,航空电子资源可以由多个系统共享。通常的航空电子资源类型

可持续发展报告 - 苏丹王子大学
Mohammad Nurunnabi 教授,博士(爱丁堡)、SFHEA、FRSA、FAIA(Acad)、CMBE、FFA、FIPA、CMA、CPA 是沙特阿拉伯苏丹王子大学可持续发展与气候中心主任、排名与国际化校长助理以及会计系主任。他是英国牛津大学圣安东尼学院的学术访问者(高级会员)。此前,他曾在英国东伦敦大学、贝德福德大学和埃奇希尔大学任教。在从事学术生涯之前,他曾在英国伦敦的 ADVFN Plc(覆盖全球 70 多个证券交易所)担任财务团队成员。他拥有英国爱丁堡大学的博士学位,并且完全通过(无需更正)。他是注册会计师 (CPA)、特许管理会计师 (CMA)、英国高等教育学院 (SFHEA) 高级研究员、国际会计师协会 (FAIA-Acad) 学术研究员、皇家艺术学会 (FRSA) 研究员、注册管理与商业教育家 (CMBE)、财务会计师协会 (FFA) 研究员和公共会计师协会 (FIPA) 研究员。他是管理会计师协会 (IMA)、欧洲会计协会 (EAA)、英国会计与金融协会 (BAFA) 和美国会计协会 (AAA) 的学术成员。他在会计行业非常活跃,是沙特阿拉伯 IMA 利雅得分会的副总裁(教育)和美国 IMA 多元化思想领导力管道 (DTLP) 委员会的全球顾问成员。在他的领导下,苏丹王子大学(PSU)于2022年成为全球第二所(美国以外)获得AACSB会计认证的私立大学。最近,他担任美国会计协会(AAA)国际会计部门教学与课程委员会联合主席。

CY22B 预备役学校选拔委员会简报
第三小组 Julie Smith 上校 空军空中交通管制中心主任、SG 办公室主任 Sean Heup 上校 美国空军学院预备役顾问 William Gutermuth 上校 第 514 空中机动联队指挥官 Eltressa Spencer 上校 AU/CC 预备役顾问兼总裁

适当使用政府信息和信息技术政策(适当使用政策)
员工必须遵循适用的立法,政策和标准,以在工作过程中管理信息。这包括根据IMA首席记录官批准的适用信息时间表的管理政府信息,并遵循以下要求。要了解有关信息时间表和事工的更多信息,请参阅管理政府信息政策。

AFR 发展教育常见问题解答
RDEDB:一旦申请资金并反映在 BRS 中;TR、IMA 和 ART 成员必须根据当地流程处理订单。AGR 成员将从 ARPC/DPAA 收到订单。HQ AFRC/A1KO 将发布培训线号 (TLN),其中包含各自学校的报告不早于日期 (RNETD) 和报告不晚于日期 (RNLTD)。