XiaoMi-AI文件搜索系统
World File Search SystemMDP

库库福门师型号,规格和价格2024 -Cupra
Cupra Connect服务只能通过使用可用的公共通信技术来运行。请注意,由于这些技术的开发,尤其是移动网络,Cupra不能保证在Cupra Connect Services期间所有国家 /地区的一致可用性。可能的技术变化可能会导致它们永久无法获得。*所有显示的价格均为MDP(制造商的直接价格),包括增值税。由英国大众集团有限公司的贸易部Cupra UK出售。MDP包括:交付给代理商,数字板,新车辆注册费,第一年的车辆消费税和增值税(计算为20%)。cupra UK可以随时更改MDP(这包括政府在法规和/或立法上发生变化的地方)。可能会延迟任何MDP价格正确显示在我们的材料上。

新型 HER2 靶向抗体-药物偶联物提供了以曲妥珠单抗等效暴露水平进行临床给药的可能性
潜在利益冲突:除 MDP 外,所有作者均为 Catalent Biologics 的员工,该公司拥有 CAT-01-106 分子。MDP 与 Roche/Genentech、Zymeworks、Astra-Zeneca/Daiichi Sankyo 有合作关系。

新型 HER2 靶向抗体-药物偶联物提供了以曲妥珠单抗等效暴露水平进行临床给药的可能性
潜在利益冲突:除 MDP 外,所有作者均为 Catalent Biologics 的员工,该公司拥有 CAT-01-106 分子。MDP 与 Roche/Genentech、Zymeworks、Astra-Zeneca/Daiichi Sankyo 有合作关系。

复合材料缠绕压力容器 (COPV)
产品规格 机械存储容量 400 in 3 、900 in 3 最大设计压力 (MDP) 5,000 psig 防爆系数 防爆:1.25x MDP,防爆:2x MDP 空重 9.1 lbm (400 in 3 )、15.4 lbm (900 in 3 ) 衬里材料 Inconel 718(可提供铝、耐腐蚀钢 (CRES)) 安装选项 多种。请咨询。注意:这些规格可以根据客户要求进行修改。请联系 Sierra Space 了解设计选项,以满足特定客户需求。

Cupra Leon
**仅库存。Cupra Connect服务只能通过使用可用的公共通信技术来运行。请注意,由于这些技术的开发,尤其是移动网络,Cupra不能保证在Cupra Connect Services期间所有国家 /地区的一致可用性。可能的技术变化可能会导致它们永久无法获得。*所有显示的价格均为MDP(制造商的直接价格),包括增值税。由英国大众集团有限公司的贸易部Cupra UK出售。MDP包括:交付给代理商,数字板,新车辆注册费,第一年的车辆消费税和增值税(计算为20%)。cupra UK可以随时更改MDP(这包括政府在法规和/或立法上发生变化的地方)。可能会延迟任何MDP价格正确显示在我们的材料上。


马尔可夫决策过程的时间串联
我们感兴趣的是设计计算高效的架构来解决有限时域马尔可夫决策过程 (MDP),这是一种流行的多阶段决策问题建模框架 [1,22],具有广泛的应用,从数据和呼叫中心的调度 [12] 到间歇性可再生资源的能源管理 [13]。在 MDP 中,在每个阶段,代理都会根据系统状态做出决策,从而获得即时奖励,并相应更新状态;代理的目标是找到一个最优策略,使时间范围内的总预期奖励最大化。虽然寻找解决 MDP 的有效算法一直是一个活跃的研究领域(有关调查请参阅 [20,17]),但我们将采取不同的方法。我们不是从头开始创建新算法,而是研究如何设计架构,以创造性的方式利用现有的 MDP 算法作为“黑匣子”,以获得额外的性能提升。作为朝这个方向迈出的第一步,我们提出了时间串联启发式方法,它沿时间轴采用分而治之的方法:对于具有水平线 { 0 ,... ,T − 1 } 的 MDP,我们将原始问题实例(I 0)在水平线上划分为两个子实例:0 ,... ,T

Lipschitz终身加固学习
•MDP空间中V ∗和Q ∗的Lipschitz连续性的理论研究; •根据MDP之间的局部距离提出的实用,非负转移方法; •在终身RL设置中应用此转移方法的PAC-MDP算法的建议和研究。

平均收益,总收益和点回报目标的策略复杂性
背景。马尔可夫决策过程(MDP)是表现出随机行为和受控行为的动态系统的标准模型[18]。应用包括控制理论[5,1],运营研究和金融[2,6,20],人工智能和机器学习[23,21]和正式验证[9,3]。MDP是一个有向图,其中状态是随机或控制的。在随机状态下,根据固定概率分布选择下一个状态。在受控状态下,控制器可以在所有可能的后继状态下选择分布。通过修复控制器(和初始状态)的策略,可以获得MDP运行的概率空间。控制器的目标是优化运行中某些目标函数的预期值。实现ε最佳的策略类型(分别最佳值称为其策略复杂性。过渡奖励和liminf目标。MDP通过分配实现的奖励结构(分别为整数或理性)对每个过渡的奖励。每次运行都会诱导看到过渡奖励r 0 r 1 r 2的无限序列。。。。我们考虑了该序列的LIM INF,以及其他两个重要的衍生序列。1。点回报考虑了序列r 0 r 1 r 2的lim inf。。。直接。
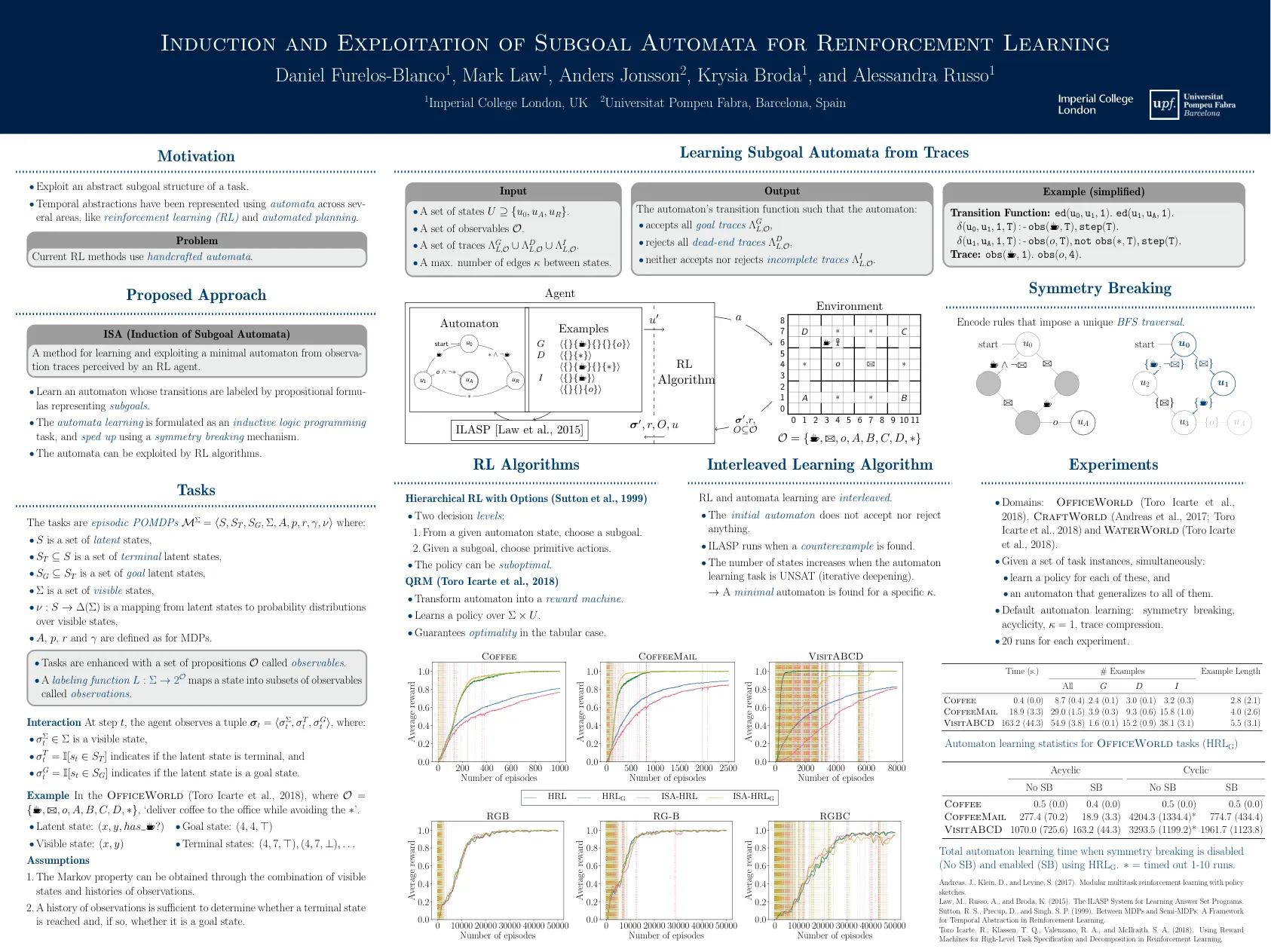
诱导和剥削亚属自动机进行加固学习
Andreas,J。,Klein,D。和Levine,S。(2017)。 模块化多任务增强措施学习政策草图。 Law,M.,Russo,A。和Broda,K。(2015)。 用于学习答案集程序的ILASP系统。 Sutton,R。S.,Precup,D。和Singh,S。P.(1999)。 MDP和半MDP之间:增强学习中时间抽象的框架。 Toro Icarte,R.,Klassen,T。Q.,Valenzano,R。A.和McIlraith,S。A. (2018)。 使用奖励机进行高级任务规范和强化学习中的分解。Andreas,J。,Klein,D。和Levine,S。(2017)。模块化多任务增强措施学习政策草图。Law,M.,Russo,A。和Broda,K。(2015)。 用于学习答案集程序的ILASP系统。 Sutton,R。S.,Precup,D。和Singh,S。P.(1999)。 MDP和半MDP之间:增强学习中时间抽象的框架。 Toro Icarte,R.,Klassen,T。Q.,Valenzano,R。A.和McIlraith,S。A. (2018)。 使用奖励机进行高级任务规范和强化学习中的分解。Law,M.,Russo,A。和Broda,K。(2015)。用于学习答案集程序的ILASP系统。Sutton,R。S.,Precup,D。和Singh,S。P.(1999)。MDP和半MDP之间:增强学习中时间抽象的框架。Toro Icarte,R.,Klassen,T。Q.,Valenzano,R。A.和McIlraith,S。A.(2018)。使用奖励机进行高级任务规范和强化学习中的分解。