XiaoMi-AI文件搜索系统
World File Search SystemReward

大脑奖励系统及其体积研究...
已经表明,在许多类型的成瘾中,大脑中发生结构变化,并可能对维持成瘾行为产生影响,这可以通过治疗改善。这项研究旨在鉴定出酒精使用障碍大脑奖励系统的结构变化。采用结构磁共振成像比较了总白质和灰质的体积,以及伏隔核,腹侧对盖面积,杏仁核和海马的体积,其中15个人患有酒精使用障碍和17个健康对照。对密歇根州酒精中毒筛查测试,酒精依赖问卷的严重程度和酒精使用障碍识别测试进行了给参与者,以揭示酒精使用的模式和依赖性的严重程度。患有酒精疾病的人群的右海马体积显着减少。在其他大脑区域方面,两组之间没有发现差异。总而言之,这项研究表明,酒精使用障碍患者的髋关节体积减少。这表明结构变化在酒精使用障碍中常见的认知障碍的病因中起作用。关键字:酒精,大脑奖励系统,神经影像学,中皮质胶质系统

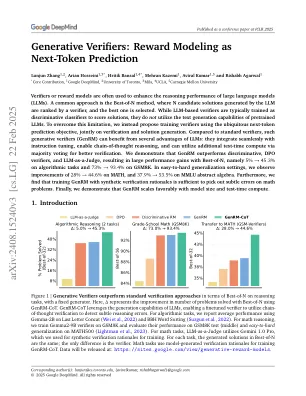
生成验证者:作为下一句话预测的奖励建模
验证者或奖励模型通常用于增强大语言模型(LLM)的推理性能。一种常见的方法是最好的N方法,其中LLM生成的N候选解决方案由验证者排名,并且选择了最好的解决方案。基于LLM的验证者通常被培训为判别性分类器以评分解决方案,但它们并未利用验证的LLM的文本生成能力。为了克服这一限制,我们使用无处不在的下一步预测目标提出了培训验证仪,共同核对和解决方案生成。与标准验证符相比,这种生成验证符(GENRM)可以从LLM的几个优点中受益:它们与指导调整无缝集成,启用了经过思考的推理,并且可以通过多数投票利用额外的测试时间计算来获得更好的验证。我们证明GENRM的表现优于歧视性,DPO验证者和LLM-AS-A-a-gudge,导致了最佳N的性能增长,即5%→45。算法任务的3%和73%→93。GSM8K的4%。 在易于硬化的概括设置中,我们观察到28%→44的改善。 数学的6%,37。 9%→53。 MMLU摘要代数为5%。 此外,我们发现具有合成验证原理的训练GENRM足以在数学问题上发现微妙的错误。 最后,我们证明GENRM会以模型大小和测试时间计算来表现出色。GSM8K的4%。在易于硬化的概括设置中,我们观察到28%→44的改善。数学的6%,37。 9%→53。 MMLU摘要代数为5%。 此外,我们发现具有合成验证原理的训练GENRM足以在数学问题上发现微妙的错误。 最后,我们证明GENRM会以模型大小和测试时间计算来表现出色。数学的6%,37。9%→53。MMLU摘要代数为5%。 此外,我们发现具有合成验证原理的训练GENRM足以在数学问题上发现微妙的错误。 最后,我们证明GENRM会以模型大小和测试时间计算来表现出色。MMLU摘要代数为5%。此外,我们发现具有合成验证原理的训练GENRM足以在数学问题上发现微妙的错误。最后,我们证明GENRM会以模型大小和测试时间计算来表现出色。

奖励灵敏度在动态风险决策中的作用
目的:我们研究的主要目标是深入探索(SS),奖励灵敏度(RS)和风险调整(RA)之间的关系。通过整合从动态风险中获得的强化学习模型和神经措施 - 我们旨在探讨这些人格特征如何影响个人决策过程以及与风险相关的活动的参与。我们旨在剖析这种相互作用的神经和认知机制,从而阐明稳定的基于大脑的特征,这有助于观察到的风险和决策行为的可变性。理解这些链接可能会显着增强我们预测风险偏好中个体差异并制定有针对性的干预措施来管理跨不同情况下的风险行为的能力。

流感疫苗会员奖励限时优惠(...
为了鼓励更多会员接种流感疫苗,华盛顿莫利纳医疗中心很高兴为未接种疫苗的 Apple Health(医疗补助)会员*(6 个月以上)提供流感疫苗会员奖励。如果会员在 2023 年 9 月 1 日至 2024 年 2 月 29 日期间接种流感疫苗,他们可以获得 100 美元的礼品卡(酒精、烟草、枪支 (ATF) 限制)。我们鼓励您将此奖励作为流感疫苗接种工作的一部分告知您的 Molina Apple Health 患者。对于此流感激励活动,不需要证明表。要获得礼品卡,会员必须通过以下两种方式之一提供所需信息:电子邮件:MHW_QI_Interventions@MolinaHealthcare.com 必填信息 • 全名,• ProviderOne ID 号码,• 出生日期,

可以疫苗激励奖励计划增加COVID- ...
例如,应仔细仔细检查激励人们接受侵入性程序或服用具有常见和严重副作用的药物的程序。sars-cov2疫苗既有效又安全,因此,激励其吸收比激励人们参加科学研究实验相对较小。公平 - 所有被告知他们有资格获得激励的人都有同等的机会接受它 - 也很重要。这并不意味着激励计划不能针对某些人群,而是应该清楚谁符合资格而谁不是。最后,在促进真正的公共卫生福利时,最好使用激励计划,在这种福利中,普通人的利益小于对整个人口的收益,就像SARS-COV2疫苗接种一样。

在人体中发现新的脂肪细胞亚型可以推进个性化的肥胖治疗大脑在做出决策时如何平衡风险和回报
近年来,机器学习的研究人员开发了一种决策理论,可以更好地捕捉与选择相关的各种潜在奖励。他们将该理论纳入了一种新的机器学习算法中,该算法优于Atari视频游戏中的替代算法,以及每个决定都具有多个可能结果的其他任务。

对新抗生素开发的市场进入奖励进行奖励
抗菌耐药性(AMR)是对全球健康和财富的日益严重的威胁。尽管需要新的抗生素来解决AMR,但由于这些项目的经济回报率低,因此对新抗生素的行业投资受到限制。英国在2022年实施了1300万美元的拉动激励措施,以提供额外的资金来激励私营部门参与者投资新的抗生素,利益相关者建议其他经合组织政府加入这些努力。我们使用基于内部收益率(IRR)措施的经济回报模型,并纳入了开发阶段进步和成本的最新数据,需要对新抗生素进行投资以解决AMR的动力。要达到11%的最低收益率,我们的结果表明,政府资助的市场入境奖励是按26亿美元的订单(支付了十年)的,需要激励开发一种新的抗菌剂。如果在十年的时间内需要六种新的抗生素,则总表明的基金将为156亿美元。与无所事事的直接和间接成本相比,我们估计的拉动激励措施的估计成本似乎是可以管理的,并且与最近在美国巴斯德法案中提出的AMR拉动激励措施(最高30亿美元)一致。我们的估计是为政府和其他利益相关者提供基础的基础,以避免或减轻AMR危机的发展开发新的抗生素。

自动奖励从混杂的离线数据
抽象的奖励成型已被证明是加速增强学习过程(RL)代理的有效技术。虽然在经验应用方面取得了成功,但良好的塑形功能的设计原则上的理解较少,因此通常依赖于领域的专业知识和手动设计。为了超越这个限制,我们提出了一种新型的自动化方法,用于设计离线数据的奖励功能,可能被未观察到的混杂偏见污染。我们建议使用从离线数据集计算出的因果状态值上限作为对最佳状态价值的保守乐观估计,然后用作基于潜在的基于潜在的重新塑造(PBR)的状态电位。根据UCB原则,将我们的塑造功能应用于无模型学习者时,我们表明,它比学习者而没有塑造的学习者享有更好的差距遗憾。据我们所知,这是通过在线探索中限制PBR的第一个依赖差距的遗憾。模拟支持理论发现。

同时奖励对大脑厌恶信息加工的影响
单独处理食欲和厌恶信息的神经网络已经得到很好的描述。然而,大脑如何整合与同时出现的食欲和厌恶信息相关的竞争信号尚不清楚。特别是,尚不清楚同时出现的奖励如何调节整个大脑对厌恶事件的处理。在这里,我们在 fMRI 研究中利用四臂老虎机任务来测量在同时收到和不同时收到金钱奖励的情况下厌恶电击的表现。使用感兴趣区域 (ROI) 方法,我们首先确定了厌恶电击体验激活的区域,然后使用独立数据测量这种与电击相关的激活如何受到同时出现的奖励的调节。根据先前的文献和我们自己的初步数据,分析集中在背外侧前额叶皮层、前脑岛和后脑岛、前扣带皮层以及丘脑和体感皮层。我们假设这些 ROI 中对惩罚的神经反应会因同时存在的奖励而减弱。然而,我们没有发现任何 ROI 中同时存在的奖励会减弱对惩罚的神经反应的证据,也没有在探索性分析中发现同时存在的惩罚会减弱对奖励的神经反应的证据。总之,我们的发现与以下观点一致:负责处理奖励和惩罚信号的神经网络在很大程度上是彼此独立的,并且整体价值或效用的表示是通过在信息处理的后期阶段整合单独的奖励和惩罚信号而得出的。