XiaoMi-AI文件搜索系统
World File Search SystemReward

温暖:关于体重平均奖励模型的好处
通过加强学习(RLHF)将大型语言模型(LLM)与人类偏好保持一致,可以导致奖励黑客,在这种情况下,LLMS在奖励模型(RM)中利用失败(RM)以实现看似高的奖励,而无需实现基本的目标。我们在设计RMS时确定了两个主要挑战以减轻奖励黑客黑客:在RL过程中的分配变化以及人类偏好的不一致。作为解决方案,我们提出了平均奖励模型(温暖),首先对多个RM进行细调,然后在重量空间中平均它们。此策略遵循以下观察结果:在共享相同的预训练时,微调权重保持线性模式。通过平均权重,与传统的预测结合相比,温暖提高了效率,同时提高了分配变化和偏好不一致的鲁棒性的可靠性。使用最佳和RL方法,我们对摘要任务的实验表明,温暖可以提高LLM预测的总体质量和一致性;例如,用温暖调整的策略RL对单个RM进行微调的政策RL的胜利率为79.4%。

政策平滑的加强学习奖励认证
强化学习(RL)在安全至关重要的地区取得了非凡的成功,但可以通过广泛的攻击来削弱它。最近的研究引入了“平滑政策”,以增强其鲁棒性。然而,建立可证明的保证以证明其全部奖励的约束仍然是挑战。先前的方法主要依赖于使用Lipschitz的连续性或计算累积奖励的概率高于特定阈值的概率。但是,这些技术仅适用于对RL药物观察结果的继续扰动,并且仅限于受L 2 -Norm界定的扰动。为这些限制做好了限制,本文提出了一种称为Receps的一般黑盒认证方法,该方法能够直接证明在各种L p-Norm有限扰动下平滑政策的累积奖励。更重要的是,我们扩展了我们的方法,以证明对动作空间的扰动。我们的方法利用F-差异来确保原始分布与扰动分布之间的区别,然后通过解决凸优化问题来确定限制的认证。我们提供了全面的理论分析并在多种环境中进行实验。我们的结果表明,我们的方法不仅可以改善平均累积奖励的认证下限的紧密度,而且还表现出比最新方法更好的效率。
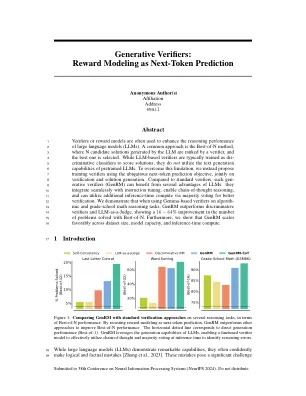
生成验证者:作为下一句话预测的奖励建模
图3:生成验证者的例证,即GenRM和GenRM-Cot。给出了一个问题和候选解决方案,genRM直接对llm进行了填补,以回答“答案正确(是/否)吗?”的问题。通过sft对对应于“是”或“否”的下一步响应。在推断期间,通过提取“是”令牌(4)的概率获得验证者分数。相比,GenRM-COT FINETUNES llm在产生最终的是/否代币之前产生验证链(COT)的基本原理。在测试时间时,我们采样了多个COT理由,并使用多数投票来计算“是”的平均概率,从而使GenRM-COT能够利用其他推理计算以更好地验证。

事件所揭示的婴儿的社会奖励预期 -
Ishikawa,Mitsuhiko和Itakura,S。(2022)与事件相关的潜力所揭示的婴儿的社会奖励预期。社会神经科学,ISSN 1747-0919。

先进的人工智能代理介入奖励的提供
我们称代理为先进,是因为它能够有效地选择其输出(我们称之为其动作),以便在广泛的环境中实现高预期效用。由于我们可能希望先进的人工智能代理在我们缺乏源代码的环境中运行,例如现实世界,因此我们认为代理在它们未知的环境中行动。如果代理的目标不仅仅是其动作的硬编码函数,那么它也必须取决于代理的感知。表明目标实现的感知本质上会告知代理,无论它使什么发生都是好的。因此,我们的研究涉及在未知环境中计划行动的代理,这需要它们了解哪些行动符合其目标。我们从一个理想化的情况开始,在这种情况下,我们似乎拥有创建具有良好目标的先进代理所需的所有工具。我们确定了代理面临的一个关键模糊性,我们认为这可能会促使代理干预我们打算提供目标信息感知的协议。然后我们概括

国防部文职人员薪酬奖励计划
6. 非 NISGS 非工业人员 – 奖项总数 7. 非 NISGS 非工业人员按等级 – 奖项总数 8. 非 NISGS 技能区人员 – 奖项总数 9. 非 NISGS 技能区人员按等级 – 奖项总数。” 2018 年 7 月 20 日,我请求您澄清 NISGS 的含义。您于 7 月 31 日通过电子邮件告知我,该缩写的意思是“北爱尔兰保安服务”。我将您的来信视为根据《2000 年信息自由法》(FOI 法)提出的信息请求。第 40(2) 条已适用于此处提供的信息,以保护《数据保护法》所管辖的个人信息并减少个人身份可能无意中泄露的情况。第 40 条是绝对豁免,

人类放弃奖励,为人工智能注入公平性
近年来,人工智能 (AI) 已成为我们日常生活中不可或缺的一部分,帮助我们做出决策。在这种交互过程中,AI 算法通常使用人类行为作为训练输入。因此,重要的是要了解人们在训练 AI 时是否会改变他们的行为,以及当训练对他们没有好处时他们是否会继续这样做。在这项工作中,我们在最后通牒游戏的背景下进行行为实验来回答这些问题。在我们的版本中,参与者被要求决定是否接受或拒绝其他人类参与者或 AI 提出的金钱分割提议。一些参与者被告知他们的选择将用于训练 AI,而其他参与者没有收到此信息。在第一个实验中,我们发现参与者愿意牺牲个人收入来训练 AI 变得公平,因为他们变得不太倾向于接受不公平的提议。第二个实验重复并扩展了这一发现,结果显示参与者有动力训练人工智能,即使他们将来永远不会遇到它。这些发现表明人类愿意付出成本来改变人工智能算法。此外,它们表明,人工智能训练过程中的人类行为不一定与基线偏好一致。这一观察结果对人工智能发展提出了挑战,表明人工智能算法在推荐选择时考虑其对行为的影响非常重要。

内在奖励在青少年词汇学习中的作用
Anglin, JM, Miller, GA, & Wakefield, PC (1993)。词汇发展:形态分析。儿童发展研究学会专著,58 (10),i–186。JSTOR。https://doi.org/10.2307/ 1166112 Angwin, AJ、Wilson, WJ、Ripollés, P.、Rodriguez-Fornells, A.、Arnott, WL、Barry, RJ、Cheng, BBY、Garden, K. 和 Copland, DA (2019)。白噪声有助于从上下文中学习新词。大脑与语言,199,104699。https://doi.org/10.1016/j.bandl.2019.104699 Bains, A.、Spaulding, C.、Ricketts, J. 和 Krishnan, S. (2023)。使用等待意愿设计来评估读者如何评价文本。Npj 学习科学,8 (1),17。https://doi.org/10.1038/s41539-023-00160-3 Baker, FC、Willoughby, AR、de Massimiliano, Z.、Franzen, PL、Prouty, D.、Javitz, H.、Hasler, B.、Clark, DB 和 Colrain, IM (2016)。全国青少年酒精与神经发育联盟样本中青少年睡眠结构和脑电图的年龄相关差异。睡眠,39 (7),1429–1439。https://doi.org/10.5665/sleep。5978 Berridge, KC, & Kringelbach, ML (2008)。愉悦的情感神经科学:人类和动物的奖励。精神药理学,199 (3),457–480。https://doi.org/10.1007/s00213-008-1099-6 Bjork, RA, Dunlosky, J., & Kornell, N. (2013)。自我调节学习:信念、技巧和幻想。心理学年鉴,64 (1),417–444。 https://doi.org/10.1146/annurev-psych-113011-143823 Blain, B., & Sharot, T. (2021)。内在奖励:潜在的认知和神经机制。当前行为科学观点,39,113–118。https:// doi.org/10.1016/j.cobeha.2021.03.008 Blakemore, S.-J., & Robbins, TW (2012)。青少年大脑中的决策。自然神经科学,15 (9),1184–1191。https://doi.org/10.1038/nn.3177 Bloom, P. (2002)。儿童如何学习单词的含义。麻省理工学院出版社。

稀疏奖励的合作多代理增强学习
∙第一作者:Minkyoung Kim,通讯作者:Minkyoung Kim *Minkyoung Kim(kmk0224@hanwha.com),Infra Technology R&D Systems,Hanwha Systems∙收到:2023。11。23,修订:2023。12。28,接受:2023。12。28。

奖励策略和实践作为留住员工的工具
摘要 本文探讨了克罗地亚与欧盟国家在奖励策略和实践方面的差异。奖励是吸引、留住和激励员工的关键工具之一。克罗地亚和欧洲公司已经开始争夺最优秀的人力资源,2016 年的数据显示,克罗地亚目前的净移民率为负(克罗地亚统计局,2019 年)。由于这种趋势对克罗地亚公司来说是令人沮丧的,我们认为有必要研究克罗地亚的奖励策略和实践状况。我们的实证研究以 61 家中型和大型克罗地亚公司为样本。研究结果表明,克罗地亚员工的年收入与欧盟公司的平均年收入之间存在很大差距。然而,克罗地亚与其他国家在激励薪酬实践、福利和非货币激励方面的差异并不大。 关键词 奖励策略、奖励管理、克罗地亚、欧盟国家