XiaoMi-AI文件搜索系统
World File Search SystemRewards

加固学习简介(RL)
•初始化环境:状态:{s 0,s 1,s 2},动作:{a 0,a 1},奖励:r(s 0,a 0)= -1,r(s 0,a 1)= +2,r(s 1,a 1,a 0)= +3,r(s 1,r(s 1,a 1,a 1,a 1)= +1,a 1,a 1,a 1,r(s s 2,r(s s 2,s raction)= 0,
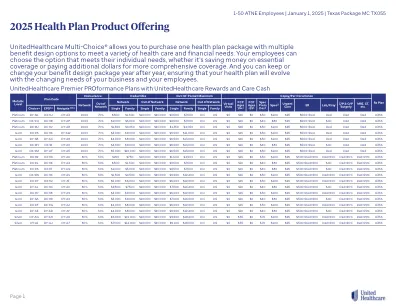
2025 年健康计划产品
UnitedHealthcare Rewards 是一项自愿计划。本计划下提供的信息仅供一般参考,并非旨在也不应被视为医疗建议。在开始任何锻炼计划之前,您应该咨询适当的医疗保健专业人员,以确定什么可能适合您。获得活动追踪器、某些积分和/或奖励和/或购买带有收入的活动追踪器可能会产生税务影响。您应该咨询适当的税务专业人员,以确定您是否根据本计划承担任何纳税义务(如适用)。如果发现任何欺诈行为(例如,虚假陈述身体活动),您可能会被暂停和/或终止参与该计划。如果您无法达到与健康因素相关的标准以获得本计划下的奖励,您可能有资格通过其他方式获得奖励。您可以拨打我们的免费电话 1-855-256-8669 或您的健康计划 ID 卡上的号码,我们将与您(以及,如果有必要,您的医生)合作,为您找到另一种方式来获得相同的奖励。由于适用法律规定的奖励限制,奖励可能会受到限制。视情况而定,需符合 HSA 资格。夏威夷、堪萨斯、佛蒙特和波多黎各不提供此计划。组件可能会发生变化。

培训大语模型通过反向课程加强学习
在本文中,我们提出了R 3:通过R Everse课程学习(RL)进行学习,这是一种新颖的方法,仅采用结果监督来实现对大语言模型的过程监督的好处。将RL应用于复杂推理的核心挑战是确定一系列动作,从而导致积极的奖励并为优化提供适当的监督。成果监督为最终结果提供了稀疏的奖励,并确定了错误位置,而过程监督提供了逐步奖励,但需要大量的手动注释。r 3通过从正确的演示中学习来克服这些局限性。具体来说,r 3从演示的结束到开头逐渐滑动推理的开始状态,从而促进了所有阶段更轻松的模型。因此,r 3建立了一个逐步的课程,允许结果监督提供级级信号,并精确地确定了词。使用Llama2-7b,我们的方法超过了八个推理任务的RL基线4。平均1点。NoteBaly,在GSM8K上基于程序的推理中,它超过了基线4。在三个骨干模型中的2分,没有任何额外数据,Codellama-7b + R 3可以对较大的型号或封闭源模型执行组合。1

Microsoft Word - 731031_pdfconv_858252_0EA7D724-8622-11EA-A12F-8AD3097C7AC2.docx
第 3 章 方法论 ................................................................................................................ 9 3.1 简介 .............................................................................................................................. 9 3.2 对象检测和深度预测 ................................................................................................ 10 3.3 强化学习架构 ............................................................................................................ 12 3.3.1 行动与奖励 ............................................................................................................. 12 3.3.3 基于收敛的探索 ............................................................................................. 13


环境氧气水平调节同种异体干细胞移植后肠道营养不良和GVHD严重程度
延迟折现描述了延迟奖励的迅速失去价值作为延迟的函数,并用作冲动决策的一种衡量标准。可燃香烟吸烟者中的尼古丁剥夺可以增加延迟折扣。我们的目的是探索在电子尼古丁输送系统(ENED)用户之间尼古丁剥夺后折现的变化。仅使用目的的三十名年轻人(18-24岁)参加了两个实验室课程:一个像往常一样蒸发,另一个是在烟碱剥夺16小时后(生化评估)。在每个会议上,参与者都完成了渴望措施,并在小型,即时奖励和大型,延迟的人之间提供了三个假设的延迟折扣任务(Money-Money-Money; e-liquid-e-e-liquid; e-liquid-Money)。

LLM通过过程奖励指导树搜索
LLM自我训练中的最新方法主要依赖于LLM生成重音,并以正确的输出答案作为培训数据过滤那些。这种方法通常会产生低质量的微调训练集(例如,计划不正确或中间推理)。在本文中,我们开发了一种加强的自我训练方法,称为REST-MCTS ∗,基于将过程奖励指导与树搜索MCTS ∗集成在一起,用于收集高质量的推理痕迹以及每步价值以培训政策和奖励模型。REST-MCT ∗避免了通常用于通过基于树搜索的强化学习来训练过程奖励的每个步骤手动注释:给定的最终正确答案,REST-MCTS ∗能够通过估算此步骤的概率来推断正确的过程奖励,可以帮助您带来正确的答案。这些推断的奖励提供了双重目的:它们是进一步完善过程奖励模型的价值目标,并促进选择高质量的痕迹进行政策模型自我训练。我们首先表明,与先前的LLM推理基线相比,REST-MCTS ∗中的树搜索策略(如在相同的搜索预算中)具有更高的精度。然后,我们证明,通过使用该搜索策略作为培训数据所搜索的痕迹,我们可以不断增强多种迭代的三种语言模型,并超过其他自我训练算法(例如REST EM和自我奖励LM)。我们在https://github.com/thudm/rest-mcts上发布所有代码。

讲座12:快速加固学习
4 UCB使用arg max a ˆ q t(a) + b,其中b是奖励项。考虑b = 5。这将使对经验奖励的算法乐观,但仍可能导致这样的算法,从而使Suer linear遗憾。
![arxiv:2404.11027V1 [CS.AI] 2024年4月17日](/simg/0\06939e0fc684e004fd4b9403eb6b6eccf4469b3f.webp)
arxiv:2404.11027V1 [CS.AI] 2024年4月17日
摘要 - 强化学习已成为自动驾驶的重要方法。使用奖励功能来加强学习来建立学习的技能目标,并指导代理商实现最佳政策。由于自主驾驶是一个复杂的领域,其目标部分具有不同程度的优先级,因此制定合适的奖励功能代表了一个基本挑战。本文旨在通过评估文献中的不同提出的公式,并将个人目标分为安全,舒适,进度和交通规则规则合规性类别,以突出这种功能设计中的差距。此外,还讨论了审查奖励功能的局限性,例如目标汇总和对驾驶环境的无动于衷。此外,奖励类别通常是不足的,缺乏标准化。本文通过提出未来的研究来结束,该研究有可能解决奖励中观察到的短暂作用,包括一个奖励验证框架和背景意识并能够解决冲突的结构性奖励。