XiaoMi-AI文件搜索系统
World File Search SystemSVD

二元响应隶属度分析的可识别等级谱方法
隶属等级 (GoM) 模型是用于多变量分类数据的流行个体级混合模型。GoM 允许每个主体在多个极端潜在概况中拥有混合成员身份。因此,与限制每个主体属于单个概况的潜在类别模型相比,GoM 模型具有更丰富的建模能力。GoM 的灵活性是以更具挑战性的可识别性和估计问题为代价的。在这项工作中,我们提出了一种基于奇异值分解 (SVD) 的谱方法来进行具有多元二元响应的 GoM 分析。我们的方法取决于以下观察:在 GoM 模型下,数据矩阵的期望具有低秩分解。对于可识别性,我们为期望可识别性概念开发了充分和几乎必要的条件。对于估计,我们仅提取观测数据矩阵的几个前导奇异向量,并利用这些向量的单纯形几何来估计混合成员分数和其他参数。我们还在双渐近状态下建立了估计量的一致性,其中受试者数量和项目数量都增长到无穷大。我们的谱方法比贝叶斯或基于可能性的方法具有巨大的计算优势,并且可以扩展到大规模和高维数据。广泛的模拟研究表明我们的方法具有卓越的效率和准确性。我们还通过将我们的方法应用于人格测试数据集来说明我们的方法。

Microsoft Word-使用机器学习algorithm_aam.doc
抽象的能源和水短缺是城市发展过程中的两个主要问题,满足对能源和淡水的需求已成为全球可持续发展的关键。在这项研究中,我们通过在一般框架中结合了多区域输入输出(MRIO),结构路径分析(SPA)和奇异值分析(SPA)和奇异值分析(SPA)的技术,开发了基于结构的奇异值分解(SSVD)模型。SSVD方法用于探索和跟踪2012年至2015年珍珠河三角洲城市聚集(PUA)中能量水连接网络的系统属性和流动路径。我们的主要发现是:(i)诱导能源相关的水(电子水)和与水相关的能量(W-Energy)最大的最终需求是出口; (ii)深圳主要取决于其他城市的电子水和w-能源,而Huizhou是电子水和W-Energy的提供者; (iii)我们确定了10,000多个能量水集群,发现广州的电力和设备分别驱动了最大的能量水簇。我们的发现表明,监测城市集聚供应链中主要能量水消耗的关键路径和集群可以为能源和水政策提供新的见解。关键字:能量水连接,机器学习,多区域投入输出分析,珍珠河三角洲城市聚集,奇异价值分解

使用基于合奏的机器学习方法增强电影推荐
摘要 - 传统的推荐系统遭受概念漂移的困扰 - 一种假定用户偏好随着时间而言是静态的现象。为了解决此问题,需要使用推荐算法来考虑用户偏好的时间敏感变化并提供相关建议。这项研究工作提出了一个基于合奏的混合推荐系统,该系统结合了用户兴趣的时间变化。提出的系统结合了不同的算法,例如受欢迎程度,聚类,协作矩阵分解和奇异价值分解(SVD)。然后,使用人工神经网络(ANN)将从这些单个模型获得的电影建议合并并分类。用户对提出的建议的反馈,这有助于计算每批建议的相关因素。最后,向用户提供了相关的电影建议。在相关因素较低的情况下,建议将重新分类。提议的系统的目的是根据用户的时间敏感偏好为用户提供各种建议。提出的研究的新颖性是整合了普遍的建议策略以及用户反馈机制在提出的建议中的结合。所提出的系统是在标准电影数据集Movielens-25m上实现的,并使用RMSE和MAE等统计性能指标进行评估。这项工作说明了建议质量的提高以及对改变用户偏好的适应性。实验表明,将人工神经网络作为集合混合建议模型的分类器的整合在提供0.56和0.43作为RMSE和MAE值的相关建议方面表明了有希望的结果。

2024年卒中一级预防指南
摘要 ������������������������������������������������������������������������������������������eXXX 十大要点 ����������������������������������������������eXXX 序言 ��������������������������������������������������������������������������������������eXXX 1. 引言 ��������������������������������������������������������������������������eXXX 1.1 方法论和证据审查 ��������������eXXX 1.2. 指南编写小组的组织 ��������������������������������������������������������������eXXX 1.3.文件审查与批准 ����������������eXXX 1.4.指南范围 ��������������������������������������eXXX 1.5 建议类别和证据级别 ��������������������������������������������������������������eXXX 1.6 缩写 ������������������������������������������������������������eXXX 2. 一般概念 ������������������������������������������������������������eXXX 2.1 卒中一级预防证据评估 ��������������������������������������������������������������������eXXX 2.2 关注卒中风险较高的人群 ����������������������������������������������������������������eXXX 2.3 社会健康的决定因素 ����������������������eXXX 3. 患者评估 ������������������������������������������������������eXXX 4. 管理健康行为和健康因素以进行中风的一级预防:生活的必需品 8 ��������������������������������������������������������eXXX 4.1 饮食质量 ��������������������������������������������������������������eXXX 4.2 体力活动 ����������������������������������������������������������eXXX 4.3 体重和肥胖 ����������������������������������������������������eXXX 4.4 睡眠 ����������������������������������������������������������������������eXXX 4.5 血糖 ������������������������������������������������������������eXXX 4.6 血压 ����������������������������������������������������������eXXX 4.7 血脂 ��������������������������������������������������������������������������eXXX 4.8 吸烟 ����������������������������������������������������������������eXXX 5. 动脉粥样硬化和非动脉粥样硬化危险因素 ����������������������������������������������������������������������eXXX 5.1 无症状颈动脉狭窄 ������������������������������������������������������������������eXXX 5.2 无症状脑 SVD,包括无症状脑梗塞 ��������������������eXXX 5.3 偏头痛 ����������������������������������������������������������������eXXX 6. 特定人群 ����������������������������������������������������������eXXX 6.1 镰状细胞病 ������������������������������������������������������eXXX 6.2 遗传性中风综合征 ��������������������������������������eXXX 6.3 凝血和炎症性疾病 ��������������������������������������������������������eXXX 6.3.1 动脉粥样硬化中的炎症 ��������eXXX 6.3.2 自身免疫性疾病 ������������������������eXXX 6.3.3 恶性肿瘤 ��������������������������������������������������eXXX 6.3.4 感染 ��������������������������������������������������������eXXX 6.4 物质使用和物质障碍 ����������������������������������������������������������������eXXX 6.5 性别和性别特异性因素 ����������������eXXX 6.5.1 怀孕 ������������������������������������������������������eXXX 6.5.2 子宫内膜异位症 ������������������������������������������������eXXX 6.5.3 激素避孕 ��������������������������eXXX 6.5.4 更年期 ����������������������������������������������������eXXX

矩阵在人工智能中的作用和应用
日出大学,拉贾斯坦邦阿尔瓦尔 摘要:矩阵是人工智能 (AI) 的基础,是各种应用程序中数据表示、操作和转换的关键工具。从机器学习算法到神经网络架构,矩阵理论支持基本计算过程,使 AI 系统能够管理海量数据集、检测复杂模式并执行复杂转换。本文探讨了矩阵在 AI 中不可或缺的作用,重点介绍了线性和逻辑回归中的基本矩阵运算,以及它们在卷积神经网络 (CNN) 和循环神经网络 (RNN) 等更高级模型中的应用。探讨了矩阵分解和特征值计算等关键数学运算在数据缩减和特征提取中的重要性,从而提高了计算机视觉、自然语言处理 (NLP) 和机器人等领域的计算效率。本文还解决了与大规模矩阵运算相关的计算挑战,例如高维数据处理、可扩展性和数值稳定性。为了克服这些限制,我们讨论了分布式矩阵计算框架、GPU 和 TPU 硬件加速以及稀疏矩阵技术的进步,展示了这些创新如何提高 AI 模型的效率和可扩展性。此外,量子计算和矩阵专用硬件解决方案的最新进展为未来的研究提供了有希望的方向,有可能通过实现矩阵计算的指数级加速来彻底改变 AI。总体而言,矩阵仍然是 AI 计算能力的核心,它提供了一个多功能且高效的框架,既支持当前的应用,也支持人工智能的新兴功能。关键词:矩阵理论、线性代数、机器学习、人工智能、奇异值分解 (SVD)。

使用机器学习算法检测语音障碍
医疗保健行业目前正在看到移动设备的使用大幅上升。这些设备不仅提供了多媒体信息(例如临床记录和医疗记录)的沟通和共享的方法,而且还为人们提供了新的可能性,可以随时随地检测,监控和管理其健康。数字健康技术有可能通过提高患者护理的效率,有效和具有成本效益来改善患者护理。利用数字设备和技术可以对许多健康状况产生积极影响。这项研究的重点是吞咽困难,这是声音的变化,在生活中某个时候影响了大约三分之一的人。语音障碍越来越普遍,尽管经常被忽视。移动医疗系统可以为检测语音疾病提供快速有效的帮助。要使这些系统可靠和准确,重要的是要开发可以对智能健康和病理声音进行分类的算法。为了完成这项任务,我们利用了几个数据集的组合,例如Saarbruecken语音数据集(SVD),Massachusetts Eye and Ear extermary Database(MEEI)(MEEI)(MEEI),以及一些各种声音(健康和病理学)的私人数据集,此外,我们还应用了多个机器学习Algorith,包括多个机器的范围,并确定了多个机器的范围,并确定了vector and Supports,并确定了vector vector,并确定了vector,并确定了森林,并确定了森林,并在内它们以检测语音障碍。实验分析是根据灵敏度,准确性,接收器操作特征,特异性,F-评分和召回率进行的。结果表明,根据使用适当的特征选择方法选择的功能,支持向量机算法被证明是检测语音疾病最准确的。

与年龄有关的“皮质” 1/f 动力学变化与心脏活动有关
图 1:使用 M/EEG 和 ECG 研究的非周期性活动的文献分析。A) 时域和频域中不同类型非周期性活动的说明。BC) 我们使用 LISC 21(一个用于收集和分析科学文献的软件包)分析了 PubMed 上索引的 489 篇摘要。B) 该分析表明,非周期性活动的变化与神经和心脏活动测量中的相似特征、状态和疾病有关。C) 我们进一步注意到,在摘要中提到心脏和皮质非周期性活动的研究(N=4)有微小的重叠。然而,这些研究都没有考虑心脏非周期性活动对皮质非周期性活动测量的混杂影响。D) 我们还发现,2020 年代与神经非周期性活动研究相关的研究急剧增加,凸显了神经科学界对该主题的当前兴趣。 EF) 我们进一步下载并分析了免费提供的 M/EEG 研究全文,这些研究调查非周期性活动,以了解心脏活动的处理程度和处理方式。该分析显示,只有 17.1% 的 EEG 研究消除了心脏活动,只有 16.5% 的研究测量了 ECG(对于 MEG,45.9% 消除了心脏活动;31.1% 提到测量了 ECG)。我们进一步希望确定哪些伪影抑制方法最常用于消除心脏活动,例如独立成分分析 (ICA 22 )、奇异值分解 (SVD 23 )、信号空间分离 (SSS 24 )、信号空间投影 (SSP 25 ) 和去噪源分离 (DSS 26 )。我们发现 EEG 和 MEG 记录中最常用的方法是独立成分分析 (ICA)。GH) 任意选择以前的研究(N = 60)表明,大量不同的频率范围用于研究非周期性活动。虽然大量研究调查了~0.1-50 Hz 之间的范围

关键词:糖尿病,慢性心力衰竭,糖 - 较低的疗法,引用的Empagliflosin:Bondarenko I.Z.,Buno div div div div
MIC,重型CHF的特征是25%[5]。通常,在范式-HF研究中,碳水化合物代谢的患者数量超过38%。根据对10项前瞻性研究的荟萃分析,178,929例糖尿病患者的参与,左胃(LV)的泵送功能降低而增加了严重心力衰竭的风险,与糖化性血红蛋白的高水平相关(HBA 1C)(HBA 1C),但与其他危险相关的趋势是,Hypoglycemias的发生趋势是Hypoglycemias的趋势,这是HYPOGLECEMIAS的趋势,即Hypoglycemias的趋势是HABLECIAS的趋势。 1C <6%,风险比(OR)1.60; 95%的信任间隔1.38–1.86; p <0.0001 [7]。在糖尿病患者以及普通人群,他汀类药物,β-肾上腺肾上腺替代者,肾素 - 英宁嗪 - 甲苯甲苯甲胺 - 甲氮胺 - 醛固型系统阻滞剂的国际随机临床研究(RCT)(RCT)中,证明了它们在CD预防中的有效性。抗癌药[8,9]。他们表明依那普利降低了心力衰竭患者的死亡风险,通过强制性成分在治疗此类患者时抑制了血管紧张素升高的钢酶[10]。近年来,在心脏病学治疗血管紧张素受体抑制剂和不遵守的心脏病治疗中,新的CHF治疗的新策略已出现,植入了Defacition Defacition The Defacition The Defacition the Defacition Straverter(CRT D)。此类患者的生命预测取决于国家和LV的收缩功能的降低:在大多数情况下,LV的射血分数降低(FV)患者在大多数情况下患有与动脉粥样硬化有关的严重疾病[5]。伴有糖尿病的CHP称为“不祥八号”(图1)。已经证明,无论存在或不存在糖尿病,心肌血运重建会降低心脏死亡率[5]。同时,患有CD的患者不仅可能具有疼痛的起源。糖尿病严重心力衰竭的发展受自主神经病的心血管形式,心肌细胞的特定病变,葡萄糖毒素毒性和氧化应激,形成的间质FI BROSE [11]。由于微血管病的形成,冠状动脉储备大大减少。由于出现了脂质学新方法的出现,针对糖尿病和心血管疾病(SVD)的患者的他汀类药物的原理,这是对重新塑造的手术技术的快速发展,使我们希望我们希望改善这种患者的预测。但是,糖尿病患者的数量和非化学病因的心力衰竭正在迅速增加。目前,对此类补液的传统援助已达到一定的治疗天花板。
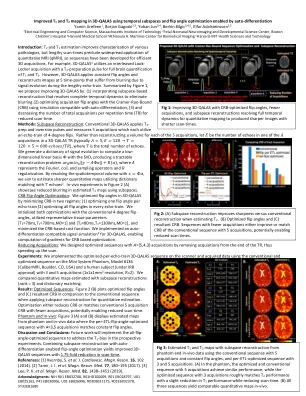
使用时间改进的 3D-QALAS 中的 T1 和 T2 映射...
简介:T 2 和 T 1 估计可改善各种病理的特征描述,但较长的扫描时间阻碍了定量 MRI (qMRI) 的广泛应用,因此已经开发了序列以实现高效的 3D 采集。例如,3D-QALAS 1 利用交错的 Look-Locker 采集和 T 2 准备脉冲来对 T 1 和 T 2 进行全脑量化。但是,3D-QALAS 应用恒定翻转角并在 5 个时间点重建图像,这些时间点由于冗长的回波序列期间的信号演变而出现模糊。总结图 1,我们建议通过以下方式改进 3D-QALAS:(1) 结合基于子空间的重建来解决完整的时间动态以消除模糊 (2) 使用与自动微分兼容的模拟通过 Cramer-Rao 界限 (CRB) 优化采集翻转角,(3) 并减少每重复时间 (TR) 的总采集次数以缩短扫描时间。方法:子空间重建:传统 3D-QALAS 应用 T 2 准备和反转脉冲并测量 5 次采集,每次采集都利用 4 度翻转的回声序列。不是为 5 次采集中的每次采集重建一个体积,而是让 𝐸 成为 3D-QALAS TR 中 𝐴 采集之一中的回声数量(通常 𝐴= 5,𝐸= 120 →𝑇= 120 × 5 = 600 𝑒𝑐ℎ𝑜𝑒𝑠/𝑇𝑅 ),其中 𝑇 是回声总数。我们生成一个信号演化字典,用 SVD 计算低维线性基 Φ,从而产生一个易于处理的重建问题 𝑎𝑟𝑔𝑚𝑖𝑛 𝛼 ‖𝑦−𝐴Φ𝛼‖ + 𝑅(𝛼) ,其中 𝐴 表示傅里叶、线圈和采样算子以及 𝑅 正则化。通过使用 𝑥= Φ𝛼 解析时空体积,我们旨在利用与 𝑇 回声 2 的字典匹配来估计更清晰的定量图。图 2 (A) 中的体内实验表明,使用子空间可以减少估计的 T 2 图中的模糊。 CRB 翻转角优化:我们通过最小化两种方式的 CRB 来优化 3D-QALAS 中的翻转角:(1) 优化每个回波序列的一个翻转角 (2) 优化每个回波序列中的所有翻转角。我们使用传统的 4 度翻转角初始化了这两种优化,利用了代表性组织参数 [T 2 =70ms、T 1 =700ms、M0=1] 和 [T 2 =80ms、T 1 =1300ms、M0=1],并最小化了基于 CRB 的成本函数。我们为 3D-QALAS 实现了自动微分兼容信号模拟 3,从而能够计算基于 CRB 的优化的梯度。减少采集:我们通过从 TR 末尾移除采集,设计了具有 A ={5,4,3} 采集的优化序列,从而加快了扫描速度。实验:我们在扫描仪上实施了针对每个回波序列进行优化的 3D-QALAS 序列,并使用 Mini System Phantom、型号 #136(CaliberMRI,美国科罗拉多州博尔德)和人类受试者(经 IRB 批准)上的常规和优化序列采集数据,进行了 3 次和 5 次采集(1x1x1mm3 分辨率,R=2)。我们比较了使用子空间重建(秩 = 3)和字典匹配估计的定量图。结果:优化序列:图 2(B)绘制了优化的翻转角和(C)与应用子空间重建进行定量估计时的传统序列相比的所得 CRB。优化可以减少 CRB 或者以更少的采集次数匹配传统的 5 次采集 CRB,从而有可能缩短扫描时间。模型和体内:图 3(A)和(B)显示了从模型和体内数据估计的图,其中每个 ETL 翻转角优化的序列(A=3,5 次采集)与恒定翻转角匹配。讨论和结论:未来的工作将实施全翻转角优化序列来解决未来实验中的 T 1 偏差。将子空间重建与自动微分启用的翻转角优化相结合,可获得改进的 3D-QALAS 序列,并将扫描时间缩短 1.75 倍。参考文献:[1] Kvernby, S. et al. J. Cardiovasc. Magn. Reson. 16 , 102 (2014)。[2] Tamir, JI 等人 Magn. Reson. Med. 77 , 180–195 (2017)。[3] Lee, PK 等人 Magn. Reson. Med. 82 , 1438–1451 (2019)。致谢:NIH R01 EB032708、R01HD100009、R01 EB028797、U01 EB025162、P41 EB030006、U01 EB026996、R03EB031175、R01EB032378、5T32EB1680