XiaoMi-AI文件搜索系统
World File Search SystemValence

光燃料测量设置-IITBNF
光致发光(PL)光谱是材料的强制性表征方法(例如III-V半导体)是一种无接触式的,无损害的,但同时非常有效且有用的实验,以研究材料的电子结构。如果光粒子(光子)的能量大于带隙能量,则可以吸收它,从而从价谱带从价值带到传导带,从而在禁止的能量间隙上升高。在这一点上,电子最终跌落回到价带失去能量作为从材料发出的发光光子。光子激发的过程随后是光子发射称为光致发光。


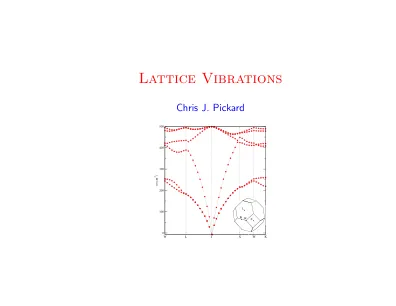
Ruddlesden–Popper 镍酸盐中的应变介导相位交叉
La 3 Ni 2 O 7 、La 4 Ni 3 O 10 、La NiO 3 中 Ni 的价态由原来的 Ni 2.5+ 、Ni 2.67+ 、

利用共享神经模式解码自然视频的动态情感反应
本研究探索了使用短暂情感事件(观看情感图片)中的共享神经模式来解码自然体验(观看电影预告片)中的扩展动态情感序列的可行性。28 名参与者观看了国际情感图片系统 (IAPS) 中的图片,并在单独的环节中观看了各种电影预告片。我们首先通过 GLM 分析定位双侧枕叶皮层 (LOC) 对情感图片类别有反应的体素,然后根据他们在观看电影预告片时的反应对 LOC 体素进行受试者间超对齐。超对齐后,我们在情感图片上训练受试者间机器学习分类器,并使用这些分类器解码样本外参与者在图片观看和电影预告片观看期间的情感状态。在参与者中,神经分类器识别图片的效价和唤醒类别,并跟踪观看视频期间自我报告的效价和唤醒。总体而言,神经分类器生成效价和唤醒时间序列,跟踪从单独样本获得的电影预告片的动态评级。我们的发现进一步支持了使用预先训练的神经表征来解码自然体验期间的动态情感反应的可能性。

自动化Wannierizations
本文档包含3个练习,以帮助您熟悉两种自动化的Wannieriza-timention方法:可纠缠频段的可耐标性 - 触发性降低的Wannier函数(PDWF),以及用于隔离频段的歧管 - 解散的Wannier功能(MRWF)。具体来说,在练习1中,我们将获得用于石墨烯的PDWF,以说明如何使用可突显性分离来提取传导带中的局部轨道。在练习2中,除了硅的标准S和P轨道外,我们还将使用其他D轨道来吸收高能传导带。在练习3中,我们将使用MRWFS分离硅的价和传导带,以显示如何使用歧管混合来自动构建绝缘体的价/传导带的键合/反键入轨道。

半导体能带概念
摘要 电气工程导论涵盖了各种基本概念,其中之一就是半导体能带的概念。理解这个概念非常重要,因为半导体是许多电子设备的基本材料,包括晶体管、二极管和集成电路。能带理论为固体材料的电学性质和电导率提供了重要的见解。通过理解这个概念,可以解释为什么有些材料是导体、绝缘体或半导体。能带理论在开发和理解许多不同的电子元件方面非常重要,包括太阳能电池、LED、二极管和晶体管。理解半导体材料的电学和光学性质需要理解能带。能带有两个主要组成部分:价带和导带。价带是可以从固体到完整状态的电子填充的能带,而导带是价带上方的能带,可以由具有更高能量的电子填充。能带的概念是理解半导体性质的重要概念之一。能带是材料中电子可获得的能量范围。半导体在电子领域有许多应用。例如,半导体用于制造计算机、电子设备、热电偶等。关键词:电气工程、能带、半导体简介

化学键和分子结构
物质由一种或多种元素组成。在正常条件下,自然界中除了稀有气体外,没有其他元素以独立原子的形式存在。然而,一组原子被发现以具有特征性质的一种物质形式存在。这样的原子组被称为分子。显然,一定有某种力将这些组成原子保持在分子中。将不同化学物质中的各种成分(原子、离子等)保持在一起的吸引力称为化学键。由于化合物的形成是各种元素的原子以不同方式结合的结果,因此它引发了许多问题。为什么原子会结合?为什么只有某些组合是可能的?为什么有些原子会结合而其他某些原子不会结合?为什么分子具有确定的形状?为了回答这些问题,人们不时提出了不同的理论和概念。这些理论和概念包括 Kössel-Lewis 方法、价壳电子对排斥 (VSEPR) 理论、价键 (VB) 理论和分子轨道 (MO) 理论。各种价态理论的演变和对化学键性质的解释与对原子结构、元素电子排布和周期表的理解的发展密切相关。每个系统都趋向于更稳定,而键合是自然界降低系统能量以达到稳定的方式。

2D量子磁性的结构调整
早期,提出了QSL的几何沮丧的三角形晶格,并通过与苯环5中的谐振电子键相似的旋转的共鸣价键进行了概念化。随后将这种共鸣的价值键图应用于Cuprate高温超导体,作为强电子配对6的来源。尽管众所周知,QSL状态由于磁性挫败感而出现,但很难在现实的模型中稳定它们,更不用说实际的材料了。在2006年,通过引入一个可解决的模型,称为Kitaev模型,在Honeycomb晶格7上具有QSL基态,从而做出了开创性贡献。在此模型中,最近的邻氏旋转由不同的(x,y或z)组件耦合,具体取决于连接它们的键的方向(三种键型x,y和z的键在图中标记了不同的颜色1 a):

用于检测用户眼部困惑的神经结构...
深度学习的使用通常仅限于对交互进行建模和使其适应用户情感的研究,部分原因是难以收集和标记大量相关数据。大量数据可用于情绪分析 [39],即从文本中检测积极与消极情感(效价),因为标记效价相对容易,至少与生成更细粒度的情绪状态标签相比是如此。也有研究使用深度学习来检测视频中表演情绪的情感(例如 [10]),其中情感标签是先验已知的。相比之下,在交互任务中收集特定的非脚本用户情感状态的数据集非常费力,因此与深度学习最成功的领域相比,此类数据集通常较小(例如 [19])。