XiaoMi-AI文件搜索系统
World File Search Systemgpu

面向未来 CPU、GPU、FPGA 应用的 48V 至 0.7V/2,000A 电源转换的现状和未来研究方向 PDF
摘要 本教程将讨论数据中心/服务器以及 AI 和机器学习系统中使用的 48V 至 0.7V (2,000A) 电源转换器所面临的挑战和解决方案。将讨论和比较两种电源架构。第一种架构是两级架构,其中 48V 转换为 12V(或另一个中间电平),然后将 12V 转换为 0.7V。第二种架构是“单级”,其中 48V“直接”转换为 0.7V。使用“直接”转换架构,无法访问(可见)中间电压总线。在简要介绍广泛应用于数据中心、服务器等的 OAM(OCP 加速器模块)的背景信息和功率要求之后,本教程将提供对降低功率损耗和提高功率密度的技术的新认识。本教程将首先回顾两级架构的最新技术并评估其优点和局限性。然后,本教程将回顾“单级”架构的最新技术并评估其优缺点。基于上述分析和回顾,本教程将提出并讨论 48V 至 0.7V(低至 0.3V)、2,000A(或更高)的应用研究方向,以实现极高的效率、极小的尺寸和电流共享、可扩展、快速动态响应等。
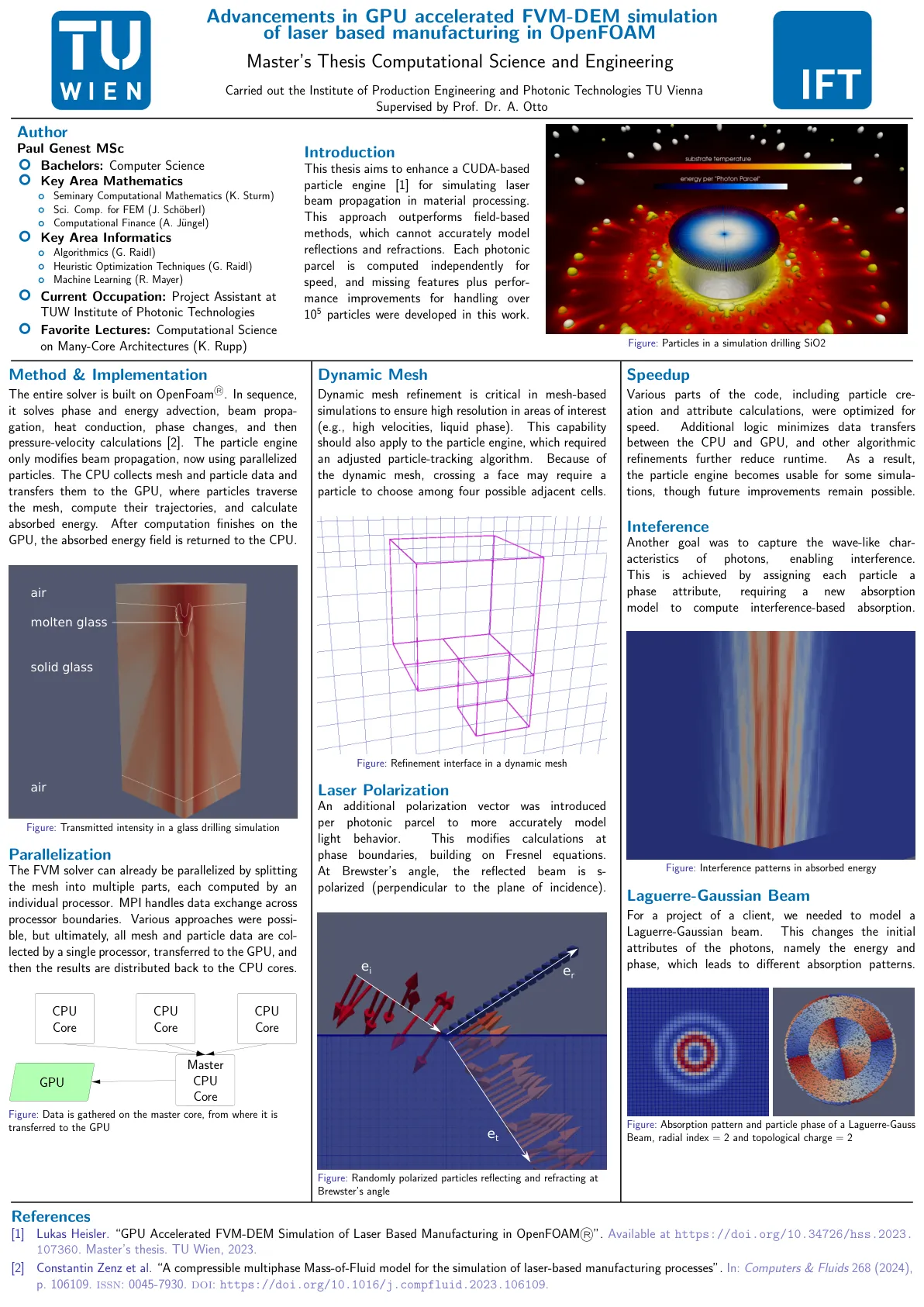
在OpenFoam Master的论文计算科学与工程中,GPU加速基于激光制造的FVM-DEM模拟的进步
方法和实现整个求解器均建立在OpenFoam®上。在序列上,它解决了相位和能量对流,梁的预测,热传导,相变,然后是压力速度计算[2]。粒子发动机仅修饰光束传播,现在使用并行化的粒子。CPU收集网格和粒子数据并将其传输到GPU,颗粒横穿网格,计算其轨迹并计算吸收能量。在GPU上计算完成后,吸收的能量场将返回到CPU。

服务器级 Tesla GPU 上的远程可视化 - NVIDIA
为了克服通过网络传输 X 的低性能问题,必须启用远程节点上的渲染。图 4 显示了具有远程可视化应用程序的配置。该应用程序通过 Xlib 与计算节点上的 X 服务器通信。OpenGL 上下文、窗口和用户交互均由计算节点上的 X 服务器完成。当从本地 GPU 捕获渲染的帧并将其传输到在用户工作站上运行的应用程序客户端时,计算节点上的应用程序完全处于控制之中。鉴于可视化应用程序完全控制客户端和服务器端,因此可以实现压缩协议等,从而实现高性能的图像传输解决方案。这是“远程可视化”部分中描述的情况。

用于GPU加速基因组分析的基准套件
摘要 - 基因组分析是对基因的研究,其中包括对基因组特征的识别,测量或比较。基因组学研究对我们的社会至关重要,因为它可以用于检测疾病,创建疫苗和开发药物和治疗方法。作为具有大量并行处理能力的一种通用加速器,GPU最近用于基因组学分析。开发基于GPU的硬件和软件框架用于基因组分析正在成为一个有希望的研究领域。为了支持这种类型的研究,需要基准,以具有代表性,并发和多种应用程序的应用程序。在这项工作中,我们创建了一个名为Genomics-GPU的基准套件,其中包含10种广泛使用的基因组分析应用。它涵盖了DNA和RNA的基因组比较,匹配和聚类。我们还调整了这些应用程序来利用CUDA动态并行性(CDP),这是一个支持动态GPU编程的最新高级功能,以进一步提高性能。我们的基准套件可以作为算法优化的基础,也可以促进GPU架构开发进行基因组学分析。索引术语 - 基因组学,生物信息学,基准测试,GPU,加速计算,基因组分析,计算机体系结构。I。研究基因组序列分析是指组织ISM的DNA序列的研究。该程序具有许多重要的应用,例如大流行爆发追踪,早期癌症检测[79],药物发育[43]和遗传疾病鉴定[87]。要通过通过四个字母(A,C,T和G)(也称为碱基或核苷酸)的字符串的形式将DNA分子通过分析生物体的基因组构成分析。确定碱基序列的过程称为基因组测序[30]。比较和发现生物学序列之间差异的过程称为序列比对[67]。过去十年中,基因组数据库的指数增长,需要在计算工具的帮助下进行大量数据。结果,已经开发了几种用于基因组分析的工具,例如BLAST [57]和GATK [58]。为了提高性能,某些基因组测序框架(例如Parasail [31]和KSW2 [53])采用了具有SIMD能力的CPU。他们利用SIMD指令提供的并行性来执行矩阵计算,通过在多个操作数中运行同一矢量命令。FPGASW [39]使用FPGA中的大量执行单元创建线性收缩期

gpu4s:嵌入式GPU在太空最新项目更新
摘要 - 遵循其他关键安全行业(如汽车和航空电子产品)的趋势,太空领域正在见证车载计算绩效需求的增加。性能需求的提高来自航天器的控制和有效载荷部分,并呼吁高级电子系统能够在苛刻的空间环境的限制下提供高计算能力。在非技术方面,由于战略原因,必须在二手计算技术上获得欧洲独立性。在这个项目中,我们研究了嵌入式GPU在太空中的适用性,这些GPU在基于竞争激烈的欧洲技术的消费市场中的增殖表明,其每瓦的绩效比例显着提高。为此,我们对现有空间应用程序域进行分析,以确定哪些软件域可以从其使用中受益。此外,我们调查了嵌入式的GPU域,以评估嵌入式GPU是否可以提供所需的计算能力并确定需要解决其在空间中需要解决的挑战。在本文中,我们描述了该项目中遵循的步骤,以及从我们的分析中获得的结果摘要。

识别 GPU 微架构漏洞的有效方法
摘要 — 图形处理单元 (GPU) 越来越多地被应用于可靠性至关重要的多个领域,例如自动驾驶汽车和自主系统。不幸的是,GPU 设备已被证明具有很高的错误率,而实时安全关键应用程序所施加的限制使得传统的(且昂贵的)基于复制的强化解决方案不足。这项工作提出了一种有效的方法来识别 GPU 模块中的架构易受攻击的位置,即如果损坏则最影响正确指令执行的位置。我们首先通过基于寄存器传输级 (RTL) 故障注入实验的创新方法来识别 GPU 模型的架构漏洞。然后,我们通过对已确定为关键的触发器应用选择性强化来减轻故障影响。我们评估了三种强化策略:三重模块冗余 (TMR)、针对 SET 的三重模块冗余 (∆ TMR) 和双联锁存储单元(骰子触发器)。在考虑功能单元、流水线寄存器和 Warp 调度器控制器的公开 GPU 模型 (FlexGripPlus) 上收集的结果表明,我们的方法可以容忍流水线寄存器中 85% 到 99% 的故障、功能单元中 50% 到 100% 的故障以及 Warp 调度器中高达 10% 的故障,同时降低硬件开销(与传统 TMR 相比,在 58% 到 94% 的范围内)。最后,我们调整了该方法以针对永久性故障执行补充评估,并确定了容易在 GPU 上传播故障影响的关键位置。我们发现,对瞬态故障至关重要的触发器中相当一部分(65% 到 98%)对永久性故障也至关重要。

快速和富有洞察力的人工智能的秘诀——GPU 加速计算
在本文件中,“德勤”是指德勤咨询有限责任公司,德勤有限责任公司的子公司。请访问 www.deloitte.com/us/about 了解我们法律结构的详细描述。根据公共会计的规则和规定,某些服务可能无法提供给鉴证客户。本出版物仅包含一般信息,德勤不会通过本出版物提供会计、商业、财务、投资、法律、税务或其他专业建议或服务。本出版物不能替代此类专业建议或服务,也不应将其用作可能影响您业务的任何决策或行动的依据。在做出任何可能影响您业务的决定或采取任何可能影响您业务的行动之前,您应咨询合格的专业顾问。德勤对任何因依赖本出版物而遭受的损失概不负责。

使用 OCI 上的 NVIDIA GPU 加速 AI 训练和推理
版权所有 © 2023,Oracle 和/或其附属公司。本文档仅供参考,其内容如有更改,恕不另行通知。本文档不保证无错误,也不受任何其他保证或条件的约束,无论是口头表达还是法律暗示,包括适销性或特定用途适用性的暗示保证和条件。我们明确声明对本文档不承担任何责任,本文档不直接或间接形成任何合同义务。未经我们事先书面许可,不得以任何形式或任何电子或机械手段出于任何目的复制或传播本文档。

启用了蒙版优化的GPU级别集
摘要 - 由于高级集成电路的特征大小不断收缩,因此分辨率增强技术(RET)被利用来改善光刻过程中的可打印性。光学接近校正(OPC)是旨在补偿面罩以生成更精确的晶圆图像的最广泛使用的RET之一。在本文中,我们提出了一种基于级别的OPC方法,具有高面膜优化质量和快速收敛。为了抑制光刻过程中条件爆发的干扰,我们会提供一个新的过程窗口感知的成本函数。然后,采用了一种新颖的基于动量的进化技术,该技术取得了重大改进。我们还提出了一种自适应共轭梯度方法,该方法有望具有更高的优化稳定性和更少的消耗时间。此外,图形过程(GPU)被利用用于加速所提出的算法。我们将输出掩码从机器学习基于掩码优化流中作为输入和工作作为重新定位掩码的后过程。ICCAD 2013基准测试的实验结果表明,我们的算法在解决方案质量和运行时开销中均优于以前的所有OPC算法。

启用了蒙版优化的GPU级别集
摘要 - 由于高级集成电路的特征大小不断收缩,因此分辨率增强技术(RET)被利用来改善光刻过程中的可打印性。光学接近校正(OPC)是旨在补偿面罩以生成更精确的晶圆图像的最广泛使用的RET之一。在本文中,我们提出了一种基于级别的OPC方法,具有高面膜优化质量和快速收敛。为了抑制光刻过程中条件爆发的干扰,我们会提供一个新的过程窗口感知的成本函数。然后,采用了一种新颖的基于动量的进化技术,该技术取得了重大改进。我们还提出了一种自适应共轭梯度方法,该方法有望具有更高的优化稳定性和更少的消耗时间。此外,图形过程(GPU)被利用用于加速所提出的算法。我们将输出掩码从机器学习基于掩码优化流中作为输入和工作作为重新定位掩码的后过程。ICCAD 2013基准测试的实验结果表明,我们的算法在解决方案质量和运行时开销中均优于以前的所有OPC算法。