XiaoMi-AI文件搜索系统
World File Search Systemreadout

波形数字化和处理大型实验的前端微电子
•ASOC:对数字转换器的类似物芯片•HDSOC:HDSOC:SIPM专用读数芯片,具有偏见和控制•Aardvarc:快速计时和较低的时间安排和较低死时间的速率读数芯片•AOD•AOD•AOD•AOD:低密度数字化器,具有高动态范围(HDR)选项(HDR)•Strawz:Strawing自动波形数据,
A.MarkFort,A.Baranov,T.Conneely,A.Duran,J.Lapington,J ... 对弱相互作用的两个组件费米气体的非扰动校正 在Compass和Amber 的软制子光片反应中测试手性扰动理论
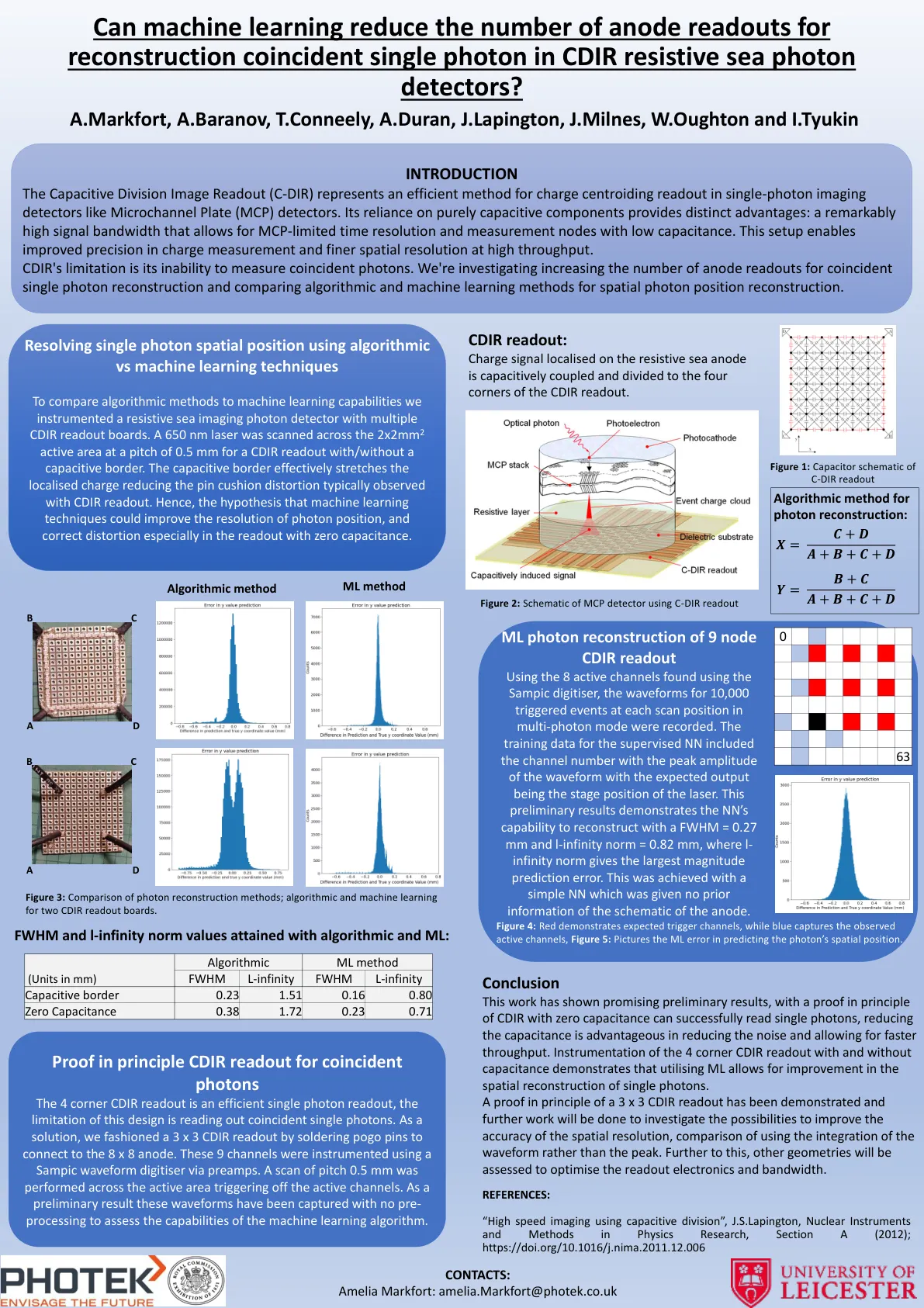
结论这项工作显示出令人鼓舞的初步结果,其原理具有零电容的CDIR可以成功读取单个光子,减少电容对于降低噪声并允许更快的吞吐量是有利的。带有和不含电容的4角CDIR读数的仪器表明,使用ML可以改善单个光子的空间重建。原则上已经证明了3 x 3 CDIR读数的证明,并将进行进一步的工作,以研究提高空间分辨率的准确性的可能性,使用波形的整合而不是峰。此外,还将评估其他几何形状,以优化读取电子和带宽。

使用超低噪声 SQUID 放大器实现量子点的灵敏射频读取
半导体中的电子自旋是最先进的量子比特实现方式之一,也是利用工业工艺制造的可扩展量子计算机的潜在基础 [1–3]。一台有用的计算机必须纠正计算过程中不可避免地出现的错误,这需要很高的单次量子比特读出保真度 [4]。用于错误检测的全表面码要求在计算机的每个时钟周期内读出大约一半的物理量子比特 [5]。直到最近,自旋量子比特装置中的单次读出只能通过自旋到电荷的转换来实现,由附近的单电子晶体管 (SET) 或量子点接触 (QPC) 电荷传感器检测 [6–9]。然而,如果使用色散读出,硬件会更简单、更小,这利用了双量子点中单重态和三重态自旋态之间的电极化率差异 [10–13]。可以通过与量子点电极之一粘合的射频 (RF) 谐振器监测由此产生的两个量子比特状态之间的电容差异。量子点中的电荷跃迁也会发生类似的色散偏移,这样反射信号有助于调整到所需的电子占据 [14–16]。色散读出的优势在于它不需要单独的电荷传感器,但即使在自旋衰减时间较长的系统中,电容灵敏度通常也不足以进行单次量子比特读出 [17–23]。最近,已经在基于双量子点的系统中展示了色散单次读出 [24–28],但为了提高读出保真度,仍然需要更高的灵敏度。

用于水库计算的多个读数的集成学习
储存器计算 (RC) [1, 2] 是一种循环神经网络,近年来因其训练成本低、可通过专用电路 [3, 4] 和物理 RC [5, 6] 在硬件上实现而备受关注。RC 由储存器部分和读出部分组成,储存器部分接收时间序列输入并将其非线性转换为高维空间以表示输入的时空模式,读出部分从储存器部分拾取一些模式来分析输入并生成输出。RC 的主要优势是除读出部分之外的权重连接都是固定的。因此,与深度神经网络相比,其训练所需的数据量更少,计算成本更低。因此,RC 适用于计算资源有限且无需云计算即可执行训练的边缘 AI 系统。 RC 的读出大多由线性模型(单层感知器)实现,因此,读出的适应训练数据的能力有限。为了增强 RC 的训练能力,我们提出了一个具有多个读出的 RC 模型,该模型将一个读出的训练分散,以便每个读出可以专注于特定类型的训练数据。该方法可以看作是一种集成学习,用于增强 RC 泛化性能。简单地增加读出的数量对于边缘 AI 系统来说是低效的,因为它会消耗系统中有限的内存资源。本研究引入了一种自组织函数,它能够使用
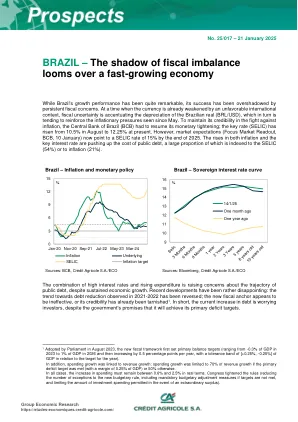
巴西 — — 财政失衡的阴影笼罩着快速发展的……
尽管巴西的增长表现相当出色,但持续的财政担忧却掩盖了其成功。在国际环境不利的情况下,巴西货币已经贬值,财政不确定性加剧了巴西雷亚尔 (BRL/USD) 的贬值,这反过来又加剧了自 5 月以来的通胀压力。为了在抗击通胀方面保持信誉,巴西央行 (BCB) 不得不恢复货币紧缩政策;基准利率 (SELIC) 已从 8 月份的 10.5% 上升至目前的 12.25%。然而,市场预期 (Focus Market Readout,BCB,1 月 10 日) 现在表明,到 2025 年底,SELIC 利率将达到 15%。通胀和基准利率的上升推高了公共债务的成本,其中很大一部分与 SELIC (54%) 或通胀 (21%) 挂钩。

高率Picsecond光电探测器(HRPPD)程序
最大化耦合到外部读数板我最大程度地减少阳极厚度,同时保持机械稳定性通过探索材料,模式和电阻率来优化内部电阻阳极设计和测试像素化读数板的限制2。使用Gen-II LAPPD的10 cm×10 cm版本进一步优化探测器设计,

超导量子比特的控制与测量系统
控制量子位的状态涉及操纵其量子态以执行所需的操作。这种操纵通常涉及应用量子门序列 [3],它们类似于经典逻辑门,但作用于量子态 [4]。这些门可以确定性地改变量子位的状态,从而产生叠加和纠缠,以及计算所需的其他量子操作。测量量子位的状态涉及确定其在特定时刻的量子态。量子位耦合到位于其物理位置附近的微波谐振器。正是通过这些谐振器,可以确定或“读出”量子位的状态。确定量子位状态的一种常用技术是色散读出法 [5]。该方法利用了这样一个事实:量子位的状态对读出谐振器的某些宏观参数(例如其谐振频率)有直接影响。

用于即时单次状态分类的神经网络
为了部署基于神经网络的状态分类,我们使用了开源 PyTorch 库。21 该库面向计算机视觉和自然语言处理,包括实现深度神经网络的能力,并包含用于在图形处理单元 (GPU) 上进行数据处理的内置功能。GPU 集成使我们的管道足够快,可以执行即时数据分类,而无需将原始测量信号传输到硬盘驱动器。除其他优点外,它还允许实时监控读出分配保真度。由于神经网络的初始训练需要几分钟的时间,因此随后的网络权重重新训练需要几秒钟,并允许读出分配保真度返回到最佳值。更重要的是,本研究中使用的卷积神经网络可以设计和训练成能够适应某些实验参数漂移的方式。具体而言,我们提出了一种策略来消除由微波发电设备引起的局部相对相位漂移对读出分配保真度的影响。在我们的实验中,我们使用了电路量子电动力学平台的原始部分:耦合到读出腔的传输器。

模块化电路QED量子计算的构建块
3.1连接的量子模块。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。24 3.2可扩展设备的配置。。。。。。。。。。。。。。。。。。。。。。。。。。。。。27 3.3 Transmon Qubit。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。31 3.4 Transmon的色散读数轨迹。。。。。。。。。。。。。。。。。。。。。。。35 3.5读取直方图。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。35 3.6基本的谐振器测量概括。。。。。。。。。。。。。。。。。。。。。。。36 3.7在不同的谐振器配置中响应。。。。。。。。。。。。。。。。。。。。。。39 3.8谐振器功率依赖性。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。41 3.9反馈冷却过程。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。43 3.10腔状态的数字峰值分辨率。。。。。。。。。。。。。。。。。。。。。。。。46 3.11存储腔的直接光谱。。。。。。。。。。。。。。。。。。。。。。。。。。47
![arXiv:2002.09522v1 [quant-ph] 2020 年 2 月 21 日](/simg/8\8ea9963302c7d10ac75dabc43aa2f524bdf5bda3.webp)
arXiv:2002.09522v1 [quant-ph] 2020 年 2 月 21 日
读出结果为长度为 J 的二进制字符串,即 R = [0 , 0 , 1 , 0 , · · · ],其中 0 表示无