XiaoMi-AI文件搜索系统
World File Search Systemsyntax

利用人工智能优化内容
# config/packages/sulu_ai.yaml sulu_ai: 提供者: openai: api_key:'%env(OPENAI_API_KEY)%' deepl: api_key:'%env(DEEPL_API_KEY)%' 专家: writing_assistant: enabled:true 说明:| 您是写作助手。您可以帮助用户撰写更好的文本。您可以纠正语法、拼写和标点错误,建议更好的措辞,并提供更多信息。如果输入包含 HTML,请确保优化文本中的 HTML 语法有效。 模型:gpt4o 选项: presetized_prompts: - 名称: 改进提示:纠正拼写错误,确保语法正确,并应用有效的写作技巧。 - 名称: 扩展提示:通过加入描述性语言和添加更多信息来增强此内容。

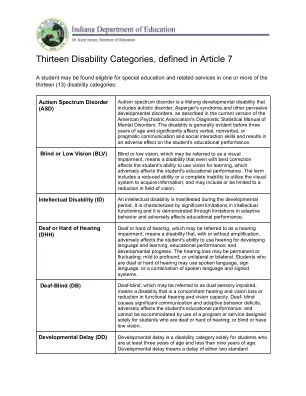
第7条十三条残疾类别MG
语言或语音障碍的特征是以下障碍之一,会对学生的教育表现产生不利影响:语言障碍是由有机或非有机原因引起的,是在自然界非成熟的,是由有机或非有机原因引起的。语言障碍会在以下一个或多个组成部分中影响学生的主要语言系统:单词检索,语音学,形态,语法,语义,语用学。语音障碍可能包括流利性,表达和语音障碍在多个语言本质上是非成熟的一项语言任务中的语音障碍,包括损害,包括损害,这些障碍是口腔外周机制缺乏结构和功能的结果。

普通微分方程 - IE
尽管在另一个课程中涵盖了用于集成微分方程的数值方案的全部覆盖范围,但专门的课程是启发性的,以介绍数值集成商的使用并学习Python中的语法以运行这些算法。特别是在本讲座中,我们将练习如何使用Python库Scipy.integrate对非线性ODES系统进行编码。tihs课程主要集中在基本面和分析技术上,但是关注数值方法将很有用,因为在实践中,这是我们最终在所有实际情况中最终使用的。我们将使用jupyter笔记本进行本课程,而重点并不是了解数值集成方法如何工作,而是能够使用它们。

2024 Student Samples and Commentaries: AP Research
This performance task was intended to assess students' ability to conduct scholarly and responsible research and develop an evidence-based argument that clearly communicates a conclusion or new understanding stemming from a clearly articulated research question or project goal. More specifically, this performance task was intended to assess students' ability to: • Generate a focused research question that is situated within or connected to a larger scholarly context or community; • Explore relationships between and among multiple works representing multiple perspectives within the scholarly literature related to the topic of inquiry; • Articulate what approach, method, or process they have chosen to use to address their research question, why they have chosen that approach to answering their question, and how they employed it; • Develop and present their own argument, conclusion, or new understanding while acknowledging its limitations and discussing its implications to a larger community of practice; • Support their conclusion through the compilation, use, and synthesis of relevant and significant evidence generated by their research; • Use organizational and design elements to effectively convey the paper's message; • Consistently and accurately cite, attribute, and integrate the knowledge and work of others, while distinguishing between the student's voice and that of others; • Generate a paper in which word choice and syntax enhance communication by adhering to established conventions of grammar, usage, and mechanics.

lavaan:潜在变量分析
efa 函数本质上是 lavaan 函数的包装器。它生成模型语法(针对给定数量的因子),然后调用 lavaan() 将这些因子视为应旋转的单个块。该函数仅支持单个组。分类数据照常处理,首先计算适当的(例如四分法或多分法)相关矩阵,然后将其用作 EFA 的输入。还(有限地)支持两级数据。然后在内部和之间提取相同数量的因子。promax 旋转方法(取自 stats 包)仅为方便起见提供。因为 promax 是一个两步算法(首先是方差最大,然后是斜向旋转以获得简单结构),所以它不使用 gpa 或成对旋转算法,因此不提供标准误差。

基于gan的转录组学数据增强
动机:由于高通量和昂贵的测序方法,转录组学数据变得越来越易于访问。但是,数据稀缺性阻止了利用深度学习模型对表型预测的完整预测能力。人工增强训练集,即数据增强,建议作为正规化策略。数据增强对应于训练集的标签不变转换(例如,在文本数据上进行图像和语法解析的几何变换)。不幸的是,这种转换在跨文字组范围内未知。因此,已经提出了深层生成模型,例如生成对抗网络(GAN)来生成其他样本。在本文中,我们分析了基于GAN的数据增强策略,就性能指标和CAR表型的分类分析。

UTKAL 文化大学 - 布巴内斯瓦尔
本课程提供语音学和音系学、形态学、句法和语义学方面的广泛培训。这将有助于读者获得知识以理解语言的科学研究。此外,还教授语言与社会、语言与文化、语言与大脑等主题,这些主题对于了解语言的发展、关联、结构和在社会中的使用方式是必不可少的。对于对交流感兴趣的个人,语言学课程还强调了翻译和文本分析等有用的方面。本课程还为学生提供学习特定语言或对不同语言进行比较研究、语言习得、认知等的机会。学生还可以决定是否专注于语言理论或语言描述。

人工智能 科目代码:CS8691 ...
一阶谓词逻辑的语法和语义模型的域是 DOMAIN(域)——它包含的对象或域元素的集合。域必须是非空的——每个可能世界都必须包含至少一个对象。图 8.2 显示了一个包含五个对象的模型:狮心王理查德,1189 年至 1199 年的英格兰国王;他的弟弟,邪恶的约翰国王,1199 年至 1215 年的统治者;理查德和约翰的左腿;以及一顶王冠。模型中的对象可能以各种方式相关。在图中,理查德和约翰是兄弟。从形式上讲,关系 TUPLE 就是相关对象的元组的集合。(元组是按固定顺序排列的对象集合,用尖括号括住对象。)因此,此模型中的兄弟关系是集合

一般值得一读!
从前的算法 - 马丁·埃维格(Martin Erwig),2017年。Erwig说明了计算中的一系列概念,其中包括日常生活和熟悉故事的示例。Hansel和Gretel执行了一种算法,可以从森林中回家。电影《土拨鼠日》说明了无法解决性的问题;解决犯罪时,福尔摩斯在解决犯罪时会操纵数据结构;通过类型和抽象来理解哈利·波特世界中的魔力。印第安纳·琼斯(Indiana Jones)展示了搜索的复杂性。在此过程中,Erwig还讨论了组织数据的表示和不同的方式。 “棘手的”问题;语言,语法和歧义;控制结构,循环和停止问题;不同形式的递归;以及在算法中查找错误的规则。这本引人入胜的书可以访问计算,并显示出与日常生活的相关性。