XiaoMi-AI文件搜索系统
World File Search System动画

用于生成动画-M -Body
mbody是一个开源的应用研究项目,旨在加快生成角色动画技术的进步和采用。由加拿大国家科学和加拿大研究委员会(NSERC)的联邦资助,由来自四个专上应用研究中心的一组研究人员团队领导,我们的目标是以以下特定方式为行业和学术界提供价值:

制作3D动画教学材料
正确的财富管理教育是政府、学校、社会和家庭必须解决的现实问题。美国、日本等国家高度重视财富管理教育,并将其作为重要的教育内容付诸实践[1]。Bryant、Stone和Wier[2]认为个人财富管理知识影响其财富管理态度。Xiao、Tang和Shim[3]指出,如果大学生愿意控制自己对个人财富管理的认知,那么他们会对自己的财富管理状况更加满意,负债也更少,财富管理与身体健康、心理健康和人们的生活呈正相关。财富管理素养提高了财富管理决策[4]。财富管理知识水平与人们的收入和退休准备呈正相关[5]。学生在学校培养的财富管理知识和习惯将成为他们成年生活的一部分,缺乏财富管理知识的学生往往对财富管理有更多负面的认知,并在财务决策中犯错误[6]。


使用深度学习的实时图像动画
该项目深入研究基于深度学习的图像动画,采用有条件的生成模型,例如生成对抗网络(GAN)和变异自动编码器(VAE)。在包含图像序列对的数据集上训练,这些模型将单个输入图像转换为连贯和新颖的动画,从而模拟自然运动和转换。使用TensorFlow在Jupyter Notebook环境中引入了交互式图像动画系统,以实现深度学习能力。利用OPENCV,FFMPEG,IMAGEIO,PIL和SCIKIT-IMAGE用于图像和视频处理,该系统将IPYTHON小部件结合在一起,用于增强用户交互。该技术在实时视频流中也起着至关重要的作用,提供动态的视觉内容而无需手动逐帧动画。该项目利用了深度学习的力量,以消除手动努力,为在不同领域的有效和现实的内容创建开辟了新的可能性。
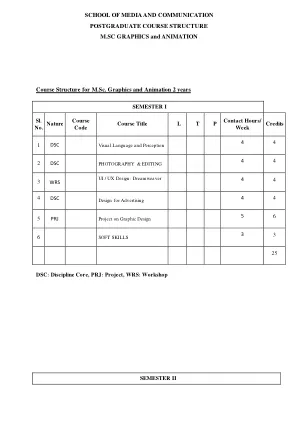
M.Sc的课程结构图形和动画2年
感性和感知理论 - 视觉交流的感性和感知理论。大脑看到的内容:颜色,形式,深度和运动。视觉消息和观众的含义制作过程 - 感知,视觉思维/可视化。练习的实践:图像,力量和政治。观察和实用;构想 - 定义和概念;创造力 - 定义和概念特征和创造力过程;创造力工具;创造力的方法;创新 - 定义和概念;横向思维定义和概念;横向思维和垂直思维;创造力和视觉交流;将思想开发到其他媒介的过程。

基于计算机的自动生成动画特殊效果
摘要。在“ Internet Plus”时代的曙光中,科学和技术的进步已解锁了动画特殊效果设计的巨大潜力。作为创造力与技术之间融合的主要典范,动画行业正在稳步发展朝着更聪明和自动化的未来发展。本文介绍了一种开创性的算法,该算法合并了CAD(计算机辅助设计),增强学习(RL)和计算机视觉(CV)算法,以彻底改变自动生成动画特殊效果。最初,使用CAD模型来构建动画场景和角色模型。随后,RL用于学习和模仿性格动作和行为。最后,将CV算法利用以识别和跟踪场景元素,无缝生成相应的特殊效果。这种自动化和智能的工作流程显着提高了动画特殊效果的效率和质量。实验结果表明,整合CAD,RL和CV技术的我们提出的算法可以产生非常现实的动画特殊效果。这项创新提供了新的观点和技术,可以推动动画行业的发展。

关于现实虚拟人类动画的调查
摘要生成现实的动画虚拟人类是一个问题,在不同类型的虚拟环境中使用了许多应用程序进行了广泛的研究。然而,这种现实动画的创建过程具有挑战性,尤其是因为有影响因素的数量和种类,然后应识别和评估。在本文中,我们试图通过提供评估其现实主义的研究调查,以更清楚地了解文献中研究的多种因素如何影响动画虚拟人类的现实水平。这包括对已操纵以增加虚拟人类现实主义以及已开发的评估方法的特征的综述。作为与人类感知一致的方式评估动画虚拟人类的挑战仍然是积极的研究问题,这项调查进一步确定了重要的开放问题和未来研究的方向。


简要摘要 - 动画生产可持续性案例研究
简要摘要 - 动画生产可持续性案例研究CMPA -BC在加拿大Telefilm的支持下,委托Earth Angel对动画生产的环境影响进行案例研究,这是加拿大同类产品中的第一个。在全球行业中,使用更多的动画,VR,AI,虚拟生产等以及以前可用的数据很少,该研究报告将是遏制该行业的碳足迹的基础。学习将支持对我们集体零途径减少排放的行动。各方聚集在一起,确定一家卑诗省的一家加拿大动画制作公司,慷慨地愿意开设其工作室,流程和书籍,以促进估计的碳排放足迹,并建议下一步。在2023年,废物和能源数据被编译并与商品价格和排放因素相结合,以开发参与工作室的就职碳足迹概况。数据是通过现场访问和在研究期间与执行团队密切合作收集的。估计的碳足迹大约在2022年发出的403吨,这是研究年度进行审查。(403公吨等同于每年的269套房屋的用电或燃烧近17,000个丙烷气缸的家庭烧烤。)确定影响的主要领域包括远程工作活动,航空旅行和数据中心。
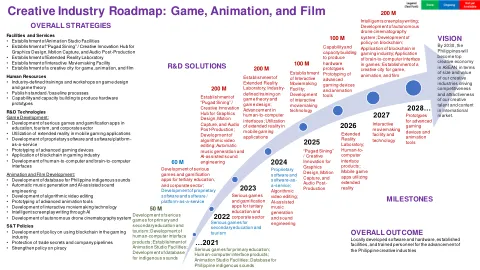
创意产业路线图:游戏、动画和电影
研发技术游戏开发:• 在教育、旅游和企业领域开发严肃游戏和游戏化应用程序• 在移动游戏应用程序中利用扩展现实• 开发专有软件和软件/平台即服务• 先进游戏设备的原型设计• 区块链在游戏行业中的应用• 人机和脑机界面的开发