XiaoMi-AI文件搜索系统
World File Search System多词

从脑磁信号进行连续语言语义重建
从神经信号中解码语言具有重要的理论和实践意义。先前的研究表明从侵入式神经信号中解码文本或语音的可行性。然而,当使用非侵入式神经信号时,由于其质量低下,面临着巨大的挑战。在本研究中,我们提出了一种数据驱动的方法,用于从受试者听连续语音时记录的脑磁图 (MEG) 信号中解码语言语义。首先,使用对比学习训练多受试者解码模型,从 MEG 数据中重建连续词嵌入。随后,采用波束搜索算法根据重建的词嵌入生成文本序列。给定波束中的候选句子,使用语言模型来预测后续单词。后续单词的词嵌入与重建的词嵌入相关联。然后使用这些相关性作为下一个单词的概率度量。结果表明,所提出的连续词向量模型可以有效利用特定主题和共享主题的信息。此外,解码后的文本与目标文本具有显著的相似性,平均 BERTScore 为 0.816,与之前的 fMRI 研究结果相当。

JIOS Vol44 No2.indd
测量文本的语义相似度在自然语言处理领域的各种任务中起着至关重要的作用。在本文中,我们描述了一组我们进行的实验,以评估和比较用于测量短文本语义相似度的不同方法的性能。我们对四种基于词向量的模型进行了比较:Word2Vec 的两个变体(一个基于在特定数据集上训练的 Word2Vec,另一个使用词义的嵌入对其进行扩展)、FastText 和 TF-IDF。由于这些模型提供了词向量,我们尝试了各种基于词向量计算短文本语义相似度的方法。更准确地说,对于这些模型中的每一个,我们测试了五种将词向量聚合到文本嵌入中的方法。我们通过对两种常用的相似度测量进行变体引入了三种方法。一种方法是基于质心的余弦相似度的扩展,另外两种方法是 Okapi BM25 函数的变体。我们在两个公开可用的数据集 SICK 和 Lee 上根据 Pearson 和 Spearman 相关性对所有方法进行了评估。结果表明,在大多数情况下,扩展方法的表现优于原始方法。关键词:语义相似度、短文本相似度、词嵌入、Word2Vec、FastText、TF-IDF
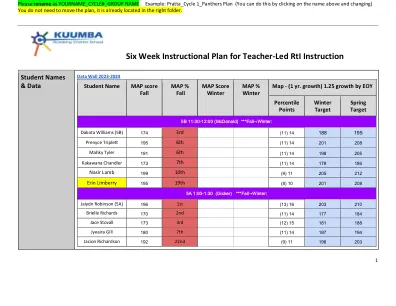
教师主导的 RtI 教学的六周教学计划
简介:文本以各种结构书写。这让读者更容易理解他们正在阅读的内容。今天,我将为您示范如何确定您正在阅读的文本结构类型。发布一张图表,其中包含六种最常见的文本结构:因果关系、问题和解决方案、问题和答案、比较和对比、描述和时间顺序,以及每种文本结构的一些提示词。这些是六种最常见的文本结构和提示词,它们将帮助您确定您正在阅读的文本结构类型。当我今天阅读文本时,我将大声思考文本可能具有哪种类型的结构。学生练习:给一个小组六段短文和六张索引卡。每张索引卡都应包含与文本结构相匹配的提示词列表。让学生一起阅读每段文本,并使用提示词卡作为指南确定其结构。然后让学生自己完成文本结构图形组织器。


语言概念的视觉类比及其含义
摘要 许多视觉生成人工智能 (AI) 模型使用文本“提示”作为输入来指导生成图像的开发。将文本转换为图像利用了语用学和语义学,这会对输出产生影响。为了促进更精确的提示,我们提出了文本相似性的三维向量空间,它使用文本表示、听觉表示和含义相似性作为轴。接下来,我们表明两个单词之间含义相似并不一定会导致相应的 AI 生成的这些单词图像之间视觉相似。我们利用八个图像生成器为抽象和具体的同义词、反义词和上义词-下义词对生成图像,并将它们的图像-图像 CLIPScore 与它们对应的文本-文本 CLIPScore 进行比较,从而定量地证明了这一点。在所有模型和关系类型中,文本与文本和图像与图像相似度的平均相似度同义词从 92.8% 下降到 70.1%,反义词从 89% 下降到 58.9%,上义词-下义词对的平均相似度从 85.6% 下降到 68.1%。

增援令牌 |卡斯蒂利亚语
1 名义团体。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 3 2 外邦人。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 4 3 尖音词、平音词和近音词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 5 4 所有格。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 6 5 谚语。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 7 6 尖锐的言辞。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 8 7 指示词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 9 8 前缀。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 10 9 简单的话。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 11 10 数字。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 12 11 不确定的。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 13 12 后缀。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 14 13 副词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 15 14 动词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 16 15 字典中的名词和形容词。 。 。 。 。 。 。 17 16 以 v 结尾的形容词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 18 17 动词的数和人称。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 19 18 前缀in-、des-。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 20 19 以 -ger 和 -gir 结尾的动词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 21 20 动词时态。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 22 21 前缀 sub- 和 inter- 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 23 22 动词中的 y。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 24 23 第一个动词变位。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 25 24 后缀-ista 和-dor。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 26 25 动词中的 b。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 27 26 第二种变位。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 28 27 后缀-oso。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 29 28 动词中的 v。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 30 29 第三变位。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。字典中的 31 30 个动词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 32 31 以 -bir 结尾的动词。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 33 32 复合时态。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 34 33 语义场。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。三十五

Q4 2024演示草案(1)
此处的某些陈述和信息,包括所有不是历史事实的陈述,都包含前瞻性陈述和适用证券法的前瞻性信息。通常但并非总是,前瞻性陈述或信息可以通过使用诸如“目标”,“计划”,“期望”,“期望”或“期望”,“预期”,“预期”,“预算”,“预算”,“估计”,“估计”,“预测”,“预测”,“预期”,“预期”,“预期”或“预期”或“或“某些词”或“某个言论”或“某种词”或“预期”或“或“或“差异”), “可能”,“可能”,“可能”,“可能”或“将”或“将”,发生或实现。


慢波睡眠期间的长期记忆形成
摘要 我们在慢波睡眠期间没有反应,但会继续监测外部事件以求生存。当危险迫在眉睫时,我们的大脑会唤醒我们。如果事件没有威胁性,我们的大脑可能会将它们存储起来,以便以后考虑,从而改善决策。为了检验这一假设,我们检查了由同时播放的伪词和翻译词组成的新词汇是否会在睡眠期间编码/存储,以及哪些神经电事件有助于编码/存储。一种大脑状态依赖性刺激算法选择性地将词对定位到慢波峰值或波谷。检索测试分别在 12 小时和 36 小时后进行。这些测试需要对之前睡眠中播放的伪词的语义类别做出决定。如果定位到波谷,睡眠中播放的词汇会在 36 小时后影响清醒时的决策。这些单词的语言处理提高了神经复杂性。在随后的峰值期间,单词的语义联想编码得到了增加的 θ 功率的支持。快速主轴功率在第二个峰值期间增加,可能有助于巩固。因此,慢波睡眠期间所学的新词汇会被储存起来,并影响几天后的决策。

人工智能教育文本分类 - 个人机器人组
我们希望确保学生彻底理解文本分类的所有步骤。为此,我们强调了 (1) 词向量、(2) K-最近邻 (KNN) 算法和 (3) 分类偏差的概念。然后,学生在 (4) 编程活动和最终项目中展示了他们的理解。1.词向量:向学生介绍了如何用词向量以数字形式表示单词的概念。我们通过示例创建了包含单词“公主”的词向量,并确定其向量中与“皇室”、“男性气质”、“女性气质”和“年龄”相对应的数字应该高还是低。2.KNN 算法:为了更好地理解 KNN 算法,学生使用在二维图上绘制的单词的视觉效果 [ 4 ]。他们了解了 K 参数的选择如何影响算法的输出。3.分类偏差:为了说明分类偏差,学生使用词语类比网站来绘制诸如“护士”、“医生”等工作,