XiaoMi-AI文件搜索系统
World File Search System质量检查

9018医疗单
记录了内部记录的程序,以满足2019年4月版本的“怀孕筛查中的感染性疾病:实验室质量检查证据要求”在产前筛查中使用以下设备并使用以下设备进行血液筛查的要求,并使用以下设备进行血液筛查,并使用sops syphilis syphibibody Igg/ igg/ igm* cobas e601 eclia antiby anpibody* anp anp anp anp anp anp anp anp s anp anp anp anp anp anp anp anp anp anp anp anp s s iggy* Hepatitis B Anti HBc total* Hepatitis B Anti HBs* HCV antibody HTLV I / II antibody Blood Toxoplasma total antibody Biomerieux VIDAS 3 ELFA HIV antigen/ antibody total MLPV036 Hepatitis A IgG Hepatitis A IgM Hepatitis B sAg Hepatitis B Anti HBc total Ab HCV抗体肝炎B'E'E'A抗原肝炎B'E'E抗体肝炎E IgG肝炎

对临床和生物医学任务应用的指令进行了零射和几次研究
摘要大型语言模型(LLMS)的最新出现已在自然语言处理(NLP)领域取得了重大进步。尽管这些新模型在各种任务上都表现出卓越的性能,但在他们可以处理的任务的多样性和应用领域的多样性方面,它们的应用和潜力仍未得到充分展望。在这种情况下,我们在一组13个现实世界中的临床和生物医学NLP任务中评估了四个最先进的指导型LLM(Chatgpt,Flan-T5 UL2,TK-Instruct和Alpaca),英语中的NLP任务,包括指定的实用性识别(NER),问题(NER),求解(QA),涉及(QA),涉及(qa),resitation(qa),更多。我们的总体结果表明,这些评估的LLMS在大多数任务中以零和几乎没有弹药方案的方式进行了最先进的模型的性能,即使他们以前从未遇到过这些任务的示例,尤其是在质量检查任务中表现出色。但是,我们还观察到,分类和重新任务无法通过为医疗领域设计的专门训练的模型(例如PubMedbert)实现的性能。最后,我们注意到,在所有研究任务中,没有一个LLM胜过所有其他LLM,某些模型比其他模型更适合某些任务。

用LLMS革新医疗保健
最近的作品探索了用于医疗保健中各种任务的大型语言模型(LLM),结果令人印象深刻。例如,使用Llama(大语言模型META AI)模型对医学文献进行微调,在生物医学质量检查数据集上获得了有希望的结果。LLM在公共卫生和临床任务中的其他应用涉及对几项预测任务进行电子健康记录的培训,而预培训的版本已用于心理健康分析,使用社交媒体进行情感检测。其中一些已将临床准则实施到LLM中以进行决策支持,而Chatgpt和BiomedLM已用于个性化肿瘤学。除了决策和文档外,LLM的应用包括通过问答系统,医疗聊天机器人和虚拟健康助理与患者的互动。他们甚至被应用于分析可穿戴设备的时间序列健康数据,以进行活动识别和健康监测等任务。尽管具有潜力,但LLMS还提出了有关医疗保健领域可靠性和透明度的非常重要的挑战。这些模型可能会在没有彻底验证的情况下产生不正确的医疗信息,这可能导致严重的误诊和治疗错误,通常会产生深度,推理和来源透明度的反应。

生成表达式的开放数据基于知识的解码
摘要。在本文中,我们提出了壁虎,这是荷兰统计数据(Centraal bureau de statistiek)数据的知识图答录(KGQA)系统。QA在产生相关答案以及防止幻觉方面构成了巨大的挑战。这是语言模型中发现的一种现象,并在尝试使用这些模型的事实质量检查时会产生问题。为了克服这些局限性,荷兰统计数据使用的ODATA4数据用于创建知识图,其中答案生成解码的构架是扎根的,从而确保了忠实的答案。处理问题时,Gecko执行实体和模式检索,是否会在需要的情况下进行架构受限的表达式解码,并将生成的表达式执行作为ODATA4查询以检索信息。实现了一种新的方法,以使用编码器模型执行受约束的基于知识的表达解码。评估了稀疏和密集的实体检索方法。虽然编码器模型未达到生产就绪的性能,但实验显示了使用稀疏实体回收者基于规则基线的有希望的结果。此外,定性用户测试的结果为正。因此,我们为部署提出建议,帮助指导荷兰统计数据的用户更快地找到答案。

LED照明采购策略报告OpenView Caginet ...
根据上述情况,证据支持切换到LED照明可以减少我们的温室气体排放的情况。因此,该计划在努力防止气候和生态紧急情况方面非常积极。财务影响该报告旨在任命OpenView Security Solutions,将LED照明计划的下一阶段提供给53个理事会区块。住房收入帐户(HRA)4年资本计划包含房东的电气安装费用为91.76亿英镑的电气安全计划中的预算,合同价值为88.亿英镑,将在本预算内的未分配资金中资助。在2023年3月31日开放了一份信用安全报告,该报告的风险得分为70,高于该理事会的最低50,年度合同限额为690万英镑,这对于本报告的采购而言足够了。此外,该服务将确保在向承包商付款之前完成,检查和质量检查所有工程,这进一步减轻了对理事会的潜在风险。准备的含义是:Llywelyn Jonas,首席会计师 - 住房资本,31/08/2023的含义验证者:丹尼·罗奇福德(HRA和经济主管(HRA和经济)),31/8/23,法律意义

基于人工智能的制造业智能质量检测
摘要:在当今时代,监控制造环境的健康状况已变得至关重要,以防止意外维修、停机,并能够检测出可能造成巨大损失的缺陷产品。数据驱动技术和物联网 (IoT) 传感器技术的进步使系统的实时跟踪成为现实。还可以通过使用质量控制 (QC) 措施在整个制造生命周期内持续评估产品的健康状况。质量检查是评估产品并判定为可接受或拒绝的关键过程之一。目视检查或最终检查过程涉及操作员对产品进行感官检查以确定其状态。但是,有几个因素会影响目视检查过程,导致行业的整体检查准确率约为 80%。先进制造系统的目标是实现 100% 检测,而人工目视检测既耗时又费钱。基于计算机视觉 (CV) 的算法有助于实现目视检测过程的部分自动化,但仍存在未解决的挑战。本文介绍了一种基于人工智能 (AI) 的基于深度学习 (DL) 的目视检测方法。该方法包括用于检测的自定义卷积神经网络 (CNN) 和可在车间部署的计算机应用程序,以使检测过程更加用户友好。所提模型对铸造产品图像数据的检测准确率为 99.86%。

比较质子泵抑制剂和组胺-2受体拮抗剂在消化性溃疡疾病患者中的安全性和功效
给出了上述情况,我们进行了系统的审查,比较了PPIS和H2RA在各种溃疡位置(胃,十二指肠和幽门前)的安全性和功效,以及使用相同的药物延长治疗或在治疗耐药性溃疡中从其他类别中转变为药物的效果。我们采用了主要的研究文献数据库和搜索引擎,例如PubMed,Medical Locerational Analysis和在线检索系统(MEDLINE),Science Direct和Google Scholar来查找相关文章。彻底筛选,使用各种工具进行质量检查,并应用适合我们资格标准的过滤器,我们确定了八篇文章,其中五篇是随机临床试验(RCT),两篇评论文章和一项荟萃分析。本研究比较了PPI和H2RA的不同副作用。大多数研究得出的结论是,奥美拉唑在愈合溃疡和减轻疼痛方面表现出色,并且在切换到PPI时可以更好地治疗对H2RAS的患者。这项研究还讨论了慢性使用的不利影响,例如腹泻,便秘,头痛和胃肠道感染。长期PPI治疗的患者必须服用钙补充剂,以防止老年人骨折的风险。关于长期结局,根据我们审查的论文,PPI仍然是消化性溃疡疾病的主要治疗方法。

格里森评分综合 AI 模型开发
已经开发出基于人工智能的自动格里森分级解决方案,以协助病理学家进行快速定量评估,但跨各种扫描仪的推广以及使用来自最终用户的新注释数据不断更新人工智能模型仍然是该领域的一个关键瓶颈。我们提出了一种全面的人工智能辅助格里森分级数字病理学工作流程,结合了图像质量检查软件 A!magQC、基于云的注释平台 A!HistoNotes 和病理学家-人工智能交互 (PAI) 策略。为了演示和验证该流程,我们将其用于从 5 台扫描仪获得的前列腺样本进行格里森分级。在对 Akoya Biosciences 扫描仪扫描的 132 例前列腺切除标本进行训练后,对 55 例前列腺切除标本和 156 例活检标本进行验证,结果显示前列腺切除标本的 Gleason 分级灵敏度为 85%,特异性为 96%,F1 得分为 78%,活检标本的肿瘤检测灵敏度为 96%。对于其他 4 台扫描仪扫描的图像,采用我们的泛化解决方案后,Gleason 模式检测的平均 F1 得分从 67% 提高到 75%。在与来自新加坡和中国的 5 名病理学家进行的临床试验中,我们的流程将 Gleason 评分速度提高了 43%。此外,它通过半自动注释将注释时间缩短了 60%,从而通过增量学习提高了模型性能。
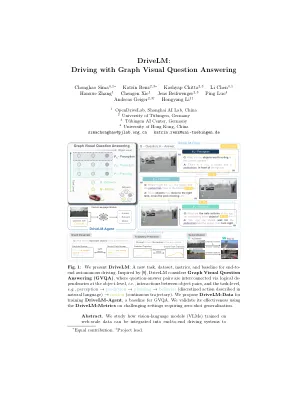
drivelm:用图形驾驶视觉问题回答
增强概括并实现与人类用户的互动性。最近的方法可以使VLM通过单轮视觉问题答案(VQA)适应VLM,但人类驾驶员在多个步骤中的决策原因。从关键对象的本地化开始,人类在采取行动之前估计相互作用。关键洞察力是,通过我们提出的任务,图形VQA,我们在其中建模了图形结构的理由,通过感知,预测和计划问题 - 答案对,我们获得了一个合适的代理任务来模仿人类的推理。我们实例化基于Nuscenes和Carla建立的数据集(DRIVELM-DATA),并提出了一种基于VLM的基线方法(Drivelm-Agent),用于共同执行图形VQA和端到端驾驶。实验表明,Graph VQA提供了一个简单的原则性框架,用于推理驾驶场景,而Drivelm-Data为这项任务提供了具有挑战性的基准。与最新的驾驶特定架构相比,我们的Drivelm-Agent基线端到端自动驾驶竞争性驾驶。值得注意的是,当在看不见的传感器配置上评估其零射击时,其好处是明显的。我们的问题上的消融研究表明,绩效增长来自图表结构中对质量检查对质量检查的丰富注释。所有数据,模型和官方评估服务器均可在https://github.com/opendrivelab/drivelm上找到。

drivelm:用图形驾驶视觉问题回答
增强概括并实现与人类用户的互动性。最近的方法可以使VLM通过单轮视觉问题答案(VQA)适应VLM,但人类驾驶员在多个步骤中的决策原因。从关键对象的本地化开始,人类在采取行动之前估计相互作用。关键洞察力是,通过我们提出的任务,图形VQA,我们在其中建模了图形结构的理由,通过感知,预测和计划问题 - 答案对,我们获得了一个合适的代理任务来模仿人类的推理。我们实例化基于Nuscenes和Carla建立的数据集(DRIVELM-DATA),并提出了一种基于VLM的基线方法(Drivelm-Agent),用于共同执行图形VQA和端到端驾驶。实验表明,Graph VQA提供了一个简单的原则性框架,用于推理驾驶场景,而Drivelm-Data为这项任务提供了具有挑战性的基准。与最新的驾驶特定架构相比,我们的Drivelm-Agent基线端到端自动驾驶竞争性驾驶。值得注意的是,当在看不见的传感器配置上评估其零射击时,其好处是明显的。我们的问题上的消融研究表明,绩效增长来自图表结构中对质量检查对质量检查的丰富注释。所有数据,模型和官方评估服务器均可在https://github.com/opendrivelab/drivelm上找到。