机构名称:
¥ 1.0
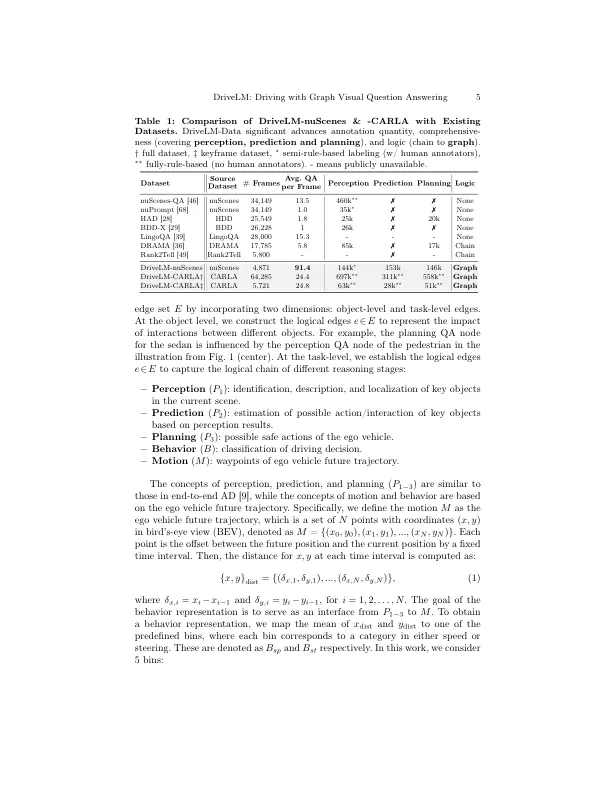
增强概括并实现与人类用户的互动性。最近的方法可以使VLM通过单轮视觉问题答案(VQA)适应VLM,但人类驾驶员在多个步骤中的决策原因。从关键对象的本地化开始,人类在采取行动之前估计相互作用。关键洞察力是,通过我们提出的任务,图形VQA,我们在其中建模了图形结构的理由,通过感知,预测和计划问题 - 答案对,我们获得了一个合适的代理任务来模仿人类的推理。我们实例化基于Nuscenes和Carla建立的数据集(DRIVELM-DATA),并提出了一种基于VLM的基线方法(Drivelm-Agent),用于共同执行图形VQA和端到端驾驶。实验表明,Graph VQA提供了一个简单的原则性框架,用于推理驾驶场景,而Drivelm-Data为这项任务提供了具有挑战性的基准。与最新的驾驶特定架构相比,我们的Drivelm-Agent基线端到端自动驾驶竞争性驾驶。值得注意的是,当在看不见的传感器配置上评估其零射击时,其好处是明显的。我们的问题上的消融研究表明,绩效增长来自图表结构中对质量检查对质量检查的丰富注释。所有数据,模型和官方评估服务器均可在https://github.com/opendrivelab/drivelm上找到。
drivelm:用图形驾驶视觉问题回答
主要关键词




相关文件推荐





























