
机构名称:
¥ 1.0
当前基于NLP的CHATGPT深度学习模型已经开发并验证了这些模型,这些模型在与一般主题有关的多项选择问题上,并在某种程度上是标准的科学基准数据集,例如PubMed Question-swingering(PubMedQA),Arxiv和Stanford Question-wording Question-Assive-Assive-Asswork-Assworge-Answorking Dataset(Squead)。但是,QA任务尤其是全文文章阅读是一项非常具有挑战性的任务,并且在当前Chatgpts的科学环境中是一项艰巨的任务。我们的管道着重于生物化学,生物信息学,生物医学的生成预训练的变压器(GPT)模型,包括临床文献,例如生物标志物,药物,剂量等。与迄今为止在现场的给定关键字或上下文特定文献有关(“人类肠道微生物组作为案例研究”)。
基于NLP的问题回答肠道微生物组的GPT
主要关键词




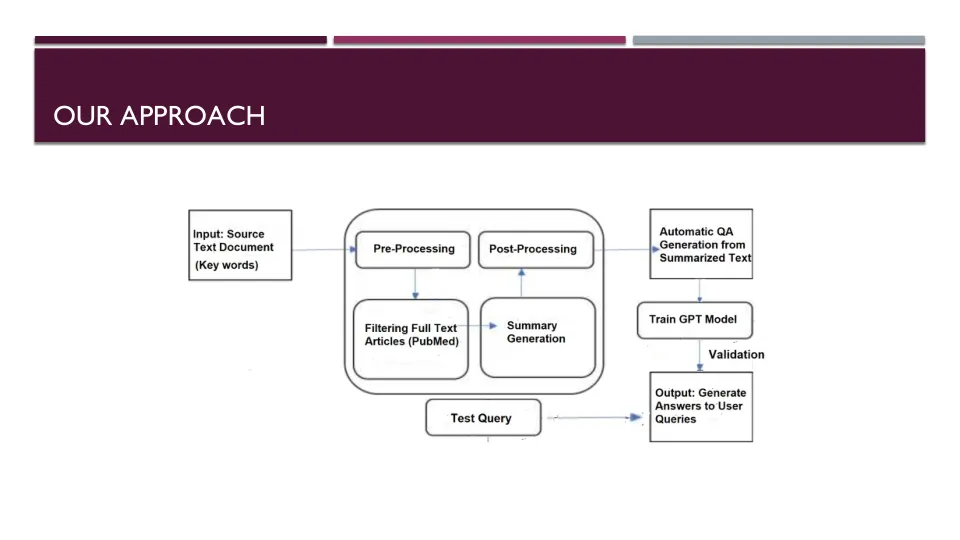
相关文件推荐





























