机构名称:
¥ 1.0
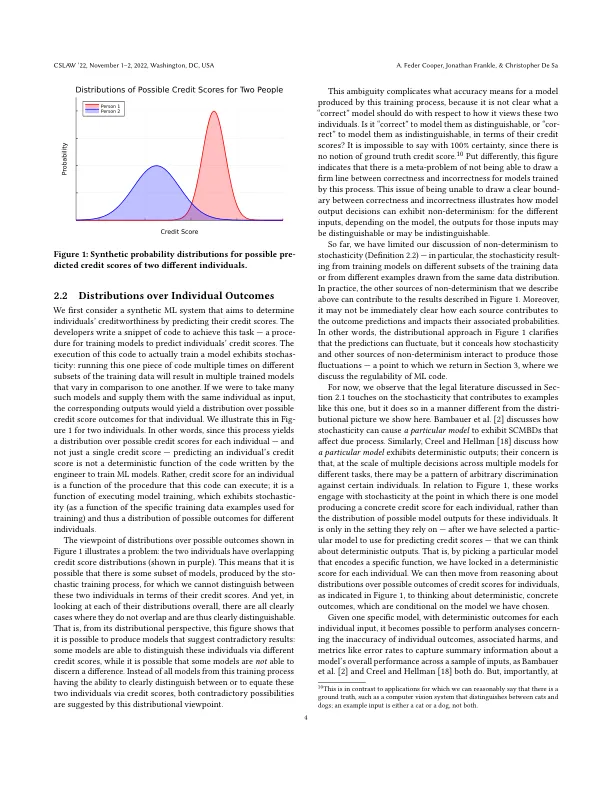
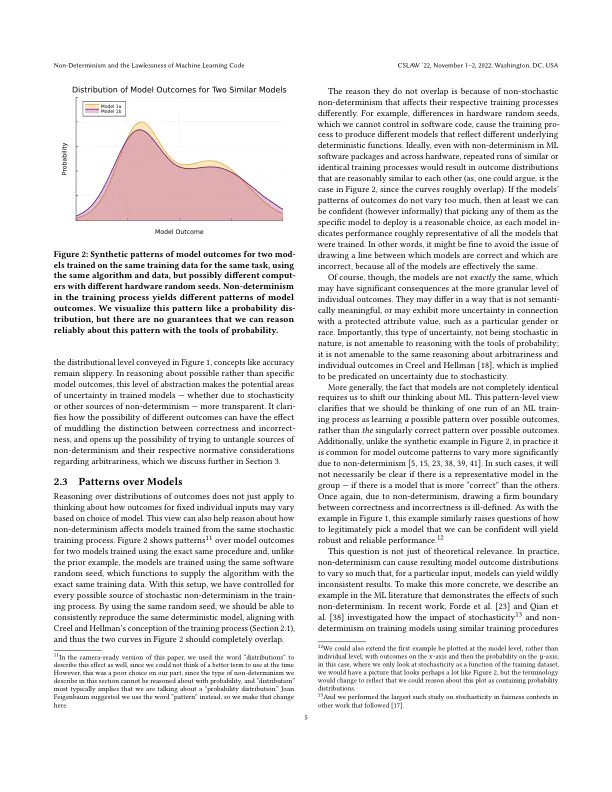
有关机器学习(ML)的法律文献倾向于关注危害,因此倾向于推理个人模型结果和摘要错误率。这种重点掩盖了ML的重要方面,这些方面源于其依赖随机性(即随机性和非确定性)。尽管最近的一些工作已经开始推论随机性与法律背景下的任意性之间的关系,但非确定主义的作用更加广泛。在本文中,我们阐明了这两个概念之间的重叠和差异,并表明非确定性的影响及其对法律的影响,从关于ML输出作为分布的推理的角度来看,将其作为对可能结果的分布而变得更加明显。通过强调ML的可能结果来解释随机性。重要的是,这种推理并不是当前法律推理的排他性;它补充了有关特定自动化决策的个人,具体结果的分析(实际上可以加强)分析。通过阐明非确定性的重要作用,我们证明了ML代码属于网络劳劳的“代码为法律”的框架,因为该框架假定代码是确定性的。我们简要讨论了ML可以采取什么措施来限制非确定性造成危害的影响,并指出法律必须在何处弥补其当前个人结果重点与我们建议的分配方法之间的差距。
非确定性和机器学习代码的违法行为
主要关键词



相关文件推荐