机构名称:
¥ 1.0
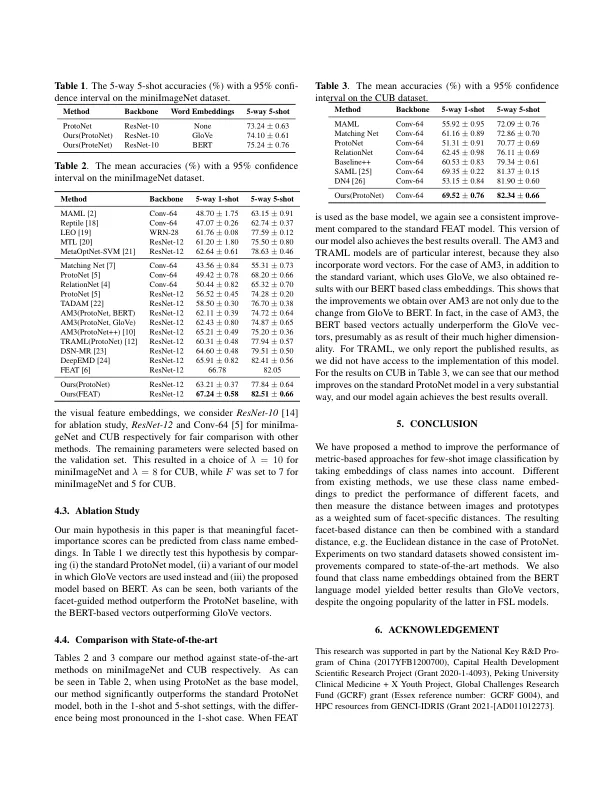
几次学习(FSL)的目的是学习如何从少数培训检查中认可图像类别。一个核心挑战是,可用的培训检查通常不足以确定哪些视觉效果是所考虑类别中最具特征的。为了应对这一挑战,我们将这些视觉特征组织成方面,从直观地将相同的特征分组(例如,与形状,颜色或纹理相关的功能)。这是从以下假设中的动机:(i)每个方面的重要性因类别而异,并且(ii)可以从类别名称的预训练的嵌入中预测Facet的重要性。尤其是我们提出了一种自适应的相似性度量,依靠对给定类别的预测的重要性权重。该措施可以与各种现有的基于度量的甲基甲化组合使用。在迷你胶原和CUB上进行的实验表明,我们的方法改善了基于公制的FSL的最新方法。
比较在电荷方案和温度的几个参数下,快速充电对三个锂离子细胞周期寿命的影响
主要关键词




相关文件推荐