XiaoMi-AI文件搜索系统
World File Search System区块
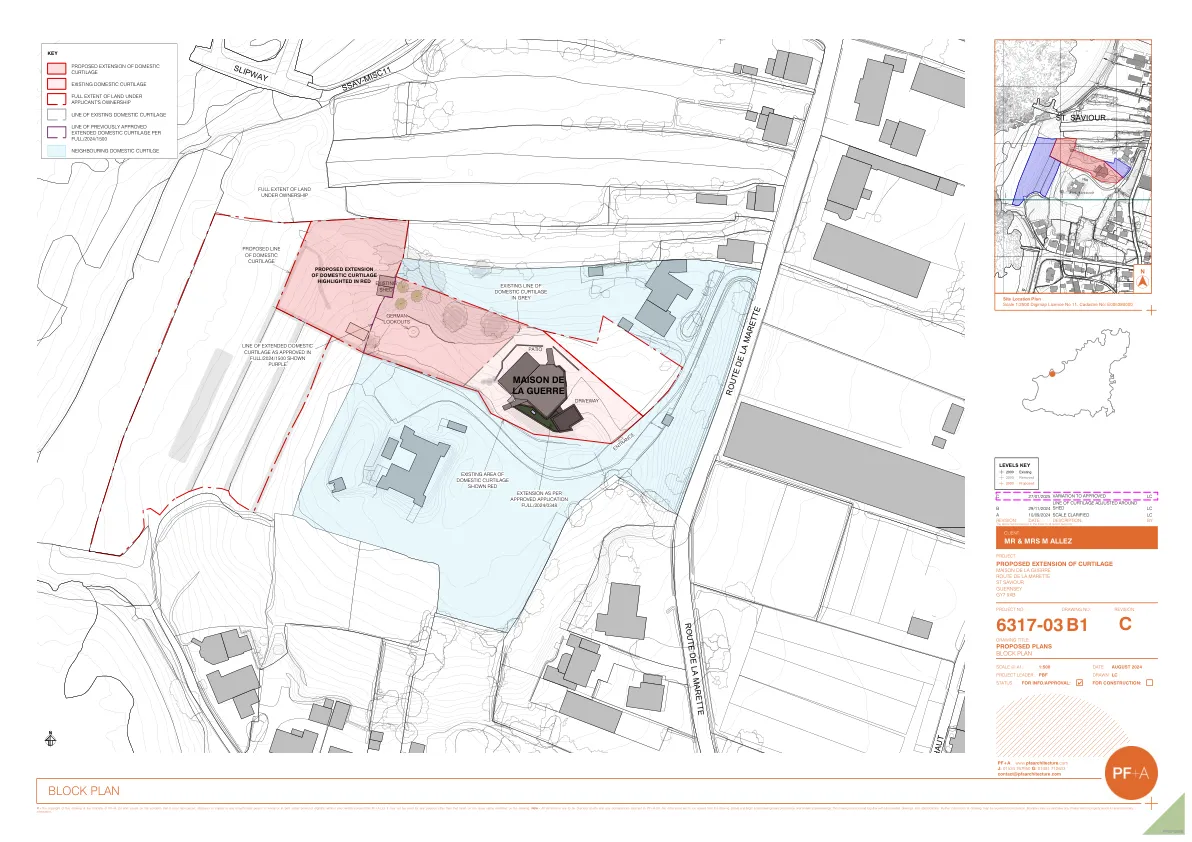
B1-区块规划 - GOV.GG - 根西岛
© - 本图纸的版权归 PF+A Ltd 所有,前提是未经 PF+A Ltd 事先书面同意,不得向任何未经授权的人员全部或部分复制、披露或复印(无论是印刷版还是数字版)。除图纸上标明的发行状态所列目的外,不得将其用于任何其他目的。注意 - 所有尺寸均应在现场检查,任何差异均应报告给 PF+A Ltd。不得根据本图纸缩放任何尺寸。细节图和较大比例的图纸优先于较小比例的图纸。本图纸必须与其他相关图纸和规格一起阅读。施工可能需要更多信息和详细说明。边界线仅供参考。有关确切边界信息,请参阅财产契约。

SGEM国际多学科科学会议第24卷,第4.1期 Cenics 2024 储能会议(ESC 2023) 用于成像应用的光学,光子学和数字技术VIII Peter Schelkens Tomasz Kozacki编辑9-11 4月9日至11日,Strasbourg,FR 通过太阳能加热反射涂层增强建筑性能:对热和电效率的影响 医疗保健和物联网(AIMLA 2024) 第19届网络战与安全国际会议(ICCWS 2024) 2024 IEEE国际高级机器人会议及其社会影响(ARSO 2024)(目录) 纳米光子X 2024 IEEE通信和网络机器学习国际会议(ICMLCN 2024)(目录) 2024 IEEE全球工程教育会议(... 2024的拉丁美洲光纤传感器研讨会(... 机器学习模型以帮助分类心血管疾病 2024 IEEE实时计算与机器人技术国际会议(RCAR 2024) 第五届计算机视觉和信息技术国际会议(CVIT 2024)JIXIN MA编辑16-18 2024年8月16日,中国北京 AOPC 2024:光学和光子学的AI 2024 IEEE国际区块链会议(... 纳米 - 呼吸电子和微/纳米 - 光子学X 2024关于密码学中故障检测和公差的研讨会(FDTC 2024)(目录) 2024信号处理 第21届关于控制,自动化和机器人技术信息学国际会议(ICINCO 2024)
11。实验模型是用方向支撑30的氢爆炸。ioana tuhut ligia,英格。Andrada Matei,博士。 eng。 Full-Mihai Pascuscu,博士。 eng。 Daniel-Gheorore博士。 eng。 Adrian Simon-Marinica 语法语法受支持的促进的铁催化剂,助理。 证明。玛丽亚博士马尔可瓦,阿索。 证明。 Antonina博士斯蒂芬,弗拉基米尔·P·莫尔查诺夫(Vladimir P. Molchanov)博士,同事。 证明。 N. Demidenko博士,Mikhail G. Sulman博士99 13。 火焰助手:理解对Mensans的燃烧,Assoc。 证明。 Castle Plant博士。 证明。大卫·莱昂(David Leon) 证明。伊莎贝尔(Isabel)博士评估,罗伯茨(Roberts),阿索(Asso)。 证明。 David Bolonio博士... 静液压动力传输系统此风力涡轮机,博士学位。英语 Dumirescu,博士英语 Chirita的Alexander-Polifron博士学习。 eng。 Stephen我有Sefu,博士学位。计划Adriana Mariana Bors,协助。 Maria Carla Carla Popescu 115。 证明。 Beyoning博士,协会。 证明。 Demidenko Galili博士,协会。 证明。 Beryozkina Svelana博士,博士学位。 证明。大卫·莱昂(David Leon)Andrada Matei,博士。eng。Full-Mihai Pascuscu,博士。eng。Daniel-Gheorore博士。 eng。 Adrian Simon-Marinica 语法语法受支持的促进的铁催化剂,助理。 证明。玛丽亚博士马尔可瓦,阿索。 证明。 Antonina博士斯蒂芬,弗拉基米尔·P·莫尔查诺夫(Vladimir P. Molchanov)博士,同事。 证明。 N. Demidenko博士,Mikhail G. Sulman博士99 13。 火焰助手:理解对Mensans的燃烧,Assoc。 证明。 Castle Plant博士。 证明。大卫·莱昂(David Leon) 证明。伊莎贝尔(Isabel)博士评估,罗伯茨(Roberts),阿索(Asso)。 证明。 David Bolonio博士... 静液压动力传输系统此风力涡轮机,博士学位。英语 Dumirescu,博士英语 Chirita的Alexander-Polifron博士学习。 eng。 Stephen我有Sefu,博士学位。计划Adriana Mariana Bors,协助。 Maria Carla Carla Popescu 115。 证明。 Beyoning博士,协会。 证明。 Demidenko Galili博士,协会。 证明。 Beryozkina Svelana博士,博士学位。 证明。大卫·莱昂(David Leon)Daniel-Gheorore博士。eng。Adrian Simon-Marinica语法语法受支持的促进的铁催化剂,助理。证明。玛丽亚博士马尔可瓦,阿索。证明。 Antonina博士斯蒂芬,弗拉基米尔·P·莫尔查诺夫(Vladimir P. Molchanov)博士,同事。证明。 N. Demidenko博士,Mikhail G. Sulman博士99 13。火焰助手:理解对Mensans的燃烧,Assoc。证明。 Castle Plant博士。证明。大卫·莱昂(David Leon)证明。伊莎贝尔(Isabel)博士评估,罗伯茨(Roberts),阿索(Asso)。证明。 David Bolonio博士...静液压动力传输系统此风力涡轮机,博士学位。英语Dumirescu,博士英语Chirita的Alexander-Polifron博士学习。eng。Stephen我有Sefu,博士学位。计划Adriana Mariana Bors,协助。 Maria Carla Carla Popescu 115。 证明。 Beyoning博士,协会。 证明。 Demidenko Galili博士,协会。 证明。 Beryozkina Svelana博士,博士学位。 证明。大卫·莱昂(David Leon)Stephen我有Sefu,博士学位。计划Adriana Mariana Bors,协助。Maria Carla Carla Popescu 115。证明。 Beyoning博士,协会。证明。 Demidenko Galili博士,协会。证明。 Beryozkina Svelana博士,博士学位。证明。大卫·莱昂(David Leon)芳香族聚合物作为PT颗粒稳定剂的性质对芳族和多氨基底物的液相氢化中的活性和选择性的影响。Prof. Dr. Linda Nikoshvili, Ms. Elena Bakhvalova .......................................... 123 16.调查太阳能发电厂的并行操作的过渡过程和紧急干扰下的网格。Bohirjon Sharifov,Murodbek Safaraliev博士,Anvari Ghulomzoda博士,博士。 Mukhammadjon Odinabekov ........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................... 烟花生命周期分析:环境影响和改善机会,协助。 David Bolonio博士,同事。 研究员Roberto Paredes教授Isabel Amez博士,协助。 Prof. Dr. Blanca Castells ............................................................................................... 139 18. 使用无人机监测太阳能农场 - 利用技术和福利,Eng Tymoteusz Turlej博士。 教授Krzysztof Kolodziejczyk,MSC Eng。 Jedrzej Minda ..................................................... 149 19. 优化了将微晶纤维素催化转化为糖醇的过程条件,Oleg Manaenkov博士,Olga Kislitsa博士,Antonina Stepacheva博士,Antonina Stepacheva博士,Linda Nikoshvili博士,Valentina Matveeva教授,Valentina Matveeva教授.............................................................................................................................................................................................................................................................................................................................Bohirjon Sharifov,Murodbek Safaraliev博士,Anvari Ghulomzoda博士,博士。Mukhammadjon Odinabekov ...........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................烟花生命周期分析:环境影响和改善机会,协助。David Bolonio博士,同事。 研究员Roberto Paredes教授Isabel Amez博士,协助。 Prof. Dr. Blanca Castells ............................................................................................... 139 18. 使用无人机监测太阳能农场 - 利用技术和福利,Eng Tymoteusz Turlej博士。 教授Krzysztof Kolodziejczyk,MSC Eng。 Jedrzej Minda ..................................................... 149 19. 优化了将微晶纤维素催化转化为糖醇的过程条件,Oleg Manaenkov博士,Olga Kislitsa博士,Antonina Stepacheva博士,Antonina Stepacheva博士,Linda Nikoshvili博士,Valentina Matveeva教授,Valentina Matveeva教授.............................................................................................................................................................................................................................................................................................................................David Bolonio博士,同事。研究员Roberto Paredes教授Isabel Amez博士,协助。 Prof. Dr. Blanca Castells ............................................................................................... 139 18. 使用无人机监测太阳能农场 - 利用技术和福利,Eng Tymoteusz Turlej博士。 教授Krzysztof Kolodziejczyk,MSC Eng。 Jedrzej Minda ..................................................... 149 19. 优化了将微晶纤维素催化转化为糖醇的过程条件,Oleg Manaenkov博士,Olga Kislitsa博士,Antonina Stepacheva博士,Antonina Stepacheva博士,Linda Nikoshvili博士,Valentina Matveeva教授,Valentina Matveeva教授.............................................................................................................................................................................................................................................................................................................................研究员Roberto Paredes教授Isabel Amez博士,协助。Prof. Dr. Blanca Castells ............................................................................................... 139 18.使用无人机监测太阳能农场 - 利用技术和福利,Eng Tymoteusz Turlej博士。教授Krzysztof Kolodziejczyk,MSC Eng。 Jedrzej Minda ..................................................... 149 19. 优化了将微晶纤维素催化转化为糖醇的过程条件,Oleg Manaenkov博士,Olga Kislitsa博士,Antonina Stepacheva博士,Antonina Stepacheva博士,Linda Nikoshvili博士,Valentina Matveeva教授,Valentina Matveeva教授.............................................................................................................................................................................................................................................................................................................................教授Krzysztof Kolodziejczyk,MSC Eng。Jedrzej Minda ..................................................... 149 19.优化了将微晶纤维素催化转化为糖醇的过程条件,Oleg Manaenkov博士,Olga Kislitsa博士,Antonina Stepacheva博士,Antonina Stepacheva博士,Linda Nikoshvili博士,Valentina Matveeva教授,Valentina Matveeva教授.............................................................................................................................................................................................................................................................................................................................

区块链:银行和财务中的加密货币预测
摘要:本研究旨在介绍区块链技术和数字货币的概念,因为区块链技术是数字货币运行的技术结构,使用描述性方法和分析方法来解决提出的问题。The study concluded that blockchain technology paves the way for the emergence of the second generation of the Internet, which will turn into a network of trust that allows the exchange of information with higher privacy and allows commercial and financial exchanges without the need for intermediary institutions that guarantee this, and It was able to solve many challenges including payment processing, manual settlement of several thousand financial transactions, payment and account management and online market trading Keywords : Blockchain,加密货币,加密,银行,金融。

外太空的区块链
区块链技术催生了强有力的叙事,以促进外层空间治理的新方式。区块链在外层空间的应用范围不胜枚举——从小行星采矿的财产登记,到供应链管理系统,或用于太空经济的星际加密货币——埃隆·马斯克声称“SpaceX 将在月球上放置真正的狗狗币。” 1 然而,到目前为止,这些项目都没有超越简单的宣言或白皮书,主要是因为在它们自己的技术框架之外有效执行基于区块链的规则存在固有的局限性。在本文中,我们认为区块链技术与外层空间相关,因为它促进了新颖的叙事 2,推进了以新治理模式为特征的可能未来。这些叙事中最强大和最突出的是加密自由主义,它主要依靠国家缺失、财产神圣不可侵犯以及通过分散市场进行私人秩序的首要地位。但是,区块链领域的相关参与者也提出了其他致力于其他治理模式的叙述。3 通过关注区块链技术的替代叙述,我们说明了区块链技术在外层空间的可能应用如何超越当前的自由主义梦想,以支持更加基于公地的外层空间治理方法。

Trenchant Technologies Capital Corp. 签署收购 Limitless Quantum 的意向书,推进抗量子区块链技术
公司与 Limitless Quantum 股东已同意,Trenchant 将在完成尽职调查并达成最终协议的前提下,收购 Limitless Quantum 已发行股份的 100%,以换取 Trenchant 发行 10,000,000 股股份(“收购”)。每股股份包括一股普通股(每股为“股份”)和一份普通股认购权证(每股为“认购权证”)。每份认购权证将赋予持有人以 0.06 加元(或加拿大证券交易所政策规定的其他价格)认购一股额外的 Trenchant 股份的权利,有效期自发行之日起三年。如果发行,股份和认购权证可能会根据适用法律或加拿大证券交易所政策的规定受到某些转让限制。 Limitless Quantum 的股东还同意自愿集中出售股份,其中 1/3 在交割日释放,1/3 在交割日后三个月释放,1/3 在交割日后六个月释放。

探索房地产区块链的采用
尽管许多组织已经采用区块链技术(BCT)来实现效率和自动化,并且用户对 BCT 的采用对公司来说也变得至关重要,但很少有研究关注影响房地产行业采用 BCT 的因素。本研究旨在通过扩展的技术接受模型(TAM)和任务技术契合度(TTF)的视角来评估影响房地产行业采用 BCT 的因素。本研究采用定量调查方法。数据来自中国 311 个实体行业买家和卖家。使用偏最小二乘结构方程模型(PLS-SEM)进行数据分析。研究结果表明,态度、感知有用性(PU)和数据隐私和安全性(DPS)在提出的理论模型中影响最大。此外,研究结果还证实了感知易用性(PEOU)对态度的显著影响,以及 TTF 对采用 BCT 的 PU 和 PEOU 的影响。此外,还证实了感知兼容性(PC)对 TTF 和 PEOU 关系的调节作用。这项研究对房地产买卖双方具有实用意义,即采用 BCT 可以提高效率、降低中介机构产生的交易成本并增强安全系统。此外,该研究表明,通过 BCT 实现的自动化将促进定制协议并改善所有权转让流程。

印度中小微型企业可持续采用区块链......
摘要。本文在利用区块链技术进行供应链管理 (SCM) 创新的背景下,研究了区块链技术在印度中小微企业 (MSME) 中的应用。除了金融之外,供应链管理是基于区块链技术的颠覆性创新将要部署的主要领域之一。区块链技术的独特主张在于信任、透明、可追溯性、不变性和去中心化等属性。中小微企业是印度经济的支柱。本文基于社会技术因素,对印度中小微企业采用区块链技术的情况进行了分析,特别是在供应链管理背景下。可持续性是一个重要变量,预计它会调节社会技术因素与大规模采用之间的关系。通过对印度中小微企业中熟悉区块链技术和可持续供应链管理的专业人士进行调查,测试了这些关系。本研究将更深入地了解社会技术系统理论在印度中小微企业采用区块链技术的应用。

加密货币和区块链不断发展的战争和对印度国防转型的需求1737229584.pdf
生物多样性热点:PAN有助于保护生物多样性热点,这些热点是具有异常高的地方性物种的地区,并且受到人类活动的威胁。栖息地保护:PAN确保保护濒临灭绝物种的关键栖息地,从而使其繁衍并保持健康的人群。生态系统服务:保护区有助于维持生态系统服务,例如清洁空气和水,土壤生育能力以及气候调节,从而使野生动植物和人类受益。遗传多样性:通过保护保护区域内的多样化栖息地,PAN有助于保留遗传多样性,这对于面对环境变化的物种的适应和弹性至关重要。研究和教育:保护区是科学研究的活业实验室,并为环境教育和公众的意识提供了机会。
俄勒冈州土地部 地震风险评估和缓解计划常见问题解答 议程 俄勒冈幼儿园免疫摘要,学年2023-2024 多样性,公平和包容性(DEI)计划 住房需求和生产 西俄勒冈地区 - 实施计划草案 酒精定价和成瘾服务工作队 2024-2028 OLCC战略计划 风疹调查指南 俄勒冈州能源策略 - 关键模型发现 进化的能源研究 森林格罗夫区 ODHS战略计划摘要 社区服务区块赠款(CSBG)国家计划 oar 411-360-0010 7.008患者虐待指控报告 精神疾病和慢性的氯胺酮治疗... 2025作物有机系统计划 删除填充指南 警报监视器培训和进修课程 州农业委员会会议议程 Clatsop County的海平面上升适应 俄勒冈能源策略
波特兰港清理(包装211)。通过继续行政支出,包括专业服务和法律支出,支持波特兰港超级基金网站的直接调查和清理工作。其他120万美元的其他资金。保护国家利益(包装212)。继续捍卫波特兰港超级基金现场清理国家利益所需的持续法律和环境专业知识。成为永久性的自然资源专家职位。其他540万美元的其他资金。
