XiaoMi-AI文件搜索系统
World File Search System目标模型

使用 Gumbel-softmax 实现深度神经网络的端到端可学习 EEG 通道选择
摘要 — 目的。为深度神经网络开发一种高效的嵌入式脑电图 (EEG) 通道选择方法,使我们能够将通道选择与目标模型相匹配,同时避免与神经网络结合使用包装器方法所带来的巨大计算负担。方法。我们采用一个具体的选择器层来联合优化 EEG 通道选择和网络参数。该层使用 Gumbel-softmax 技巧来构建选择过程中涉及的离散参数的连续松弛,从而允许以传统反向传播的方式端到端地学习它们。由于经常观察到选择层在某个选择中包含两次相同的通道,我们提出了一个正则化函数来缓解这种行为。我们在两个不同的 EEG 任务上验证了这种方法:运动执行和听觉注意解码。对于每个任务,我们将 Gumbel-softmax 方法的性能与针对此特定任务量身定制的基线 EEG 通道选择方法进行比较:分别使用效用度量的互信息和贪婪前向选择。主要结果。我们的实验表明,所提出的框架具有普遍适用性,同时其性能至少与这些最先进的、针对特定任务的方法一样好(通常更好)。意义。所提出的方法提供了一种有效的、独立于任务和模型的方法来联合学习最佳 EEG 通道以及神经网络权重。

s ecurity n et:评估公共模型上的机器学习漏洞
虽然高级机器学习(ML)模型在许多现实世界应用中都构建了,但以前的工作表明这些模型具有安全性和隐私性漏洞。在该领域已经进行了各种经验研究。但是,大多数实验都是对安全研究人员本身训练的目标ML模型进行的。由于对具有复杂体系结构的高级模型的高度计算资源需求,研究人员通常选择使用相对简单的架构在典型的实验数据集中培训一些目标模型。我们争辩说,要全面了解ML模型的漏洞,应对具有各种目的训练的大型模型进行实验(不仅是评估ML攻击和防御的目的)。为此,我们建议使用具有Inter-Net(公共模型)权重的公开模型来评估ML模型上的攻击和防御。我们建立了一个数据库,即具有910个注释的图像分类模型的数据库。然后,我们分析了几种代表性的AT-TACS/防御能力的有效性,包括模型窃取攻击,会员推理攻击以及对这些公共模型的后门检测。我们的评估从经验上表明,与自训练的模型相比,这些攻击/防御措施的性能在公共模型上可能有很大差异。我们与研究社区1分享了SCURITY N ET,并倡导研究人员在公共模型上进行实验,以更好地证明其未来所提出的方法的有效性。

当地差异隐私不够
摘要 - 针对联邦学习(FL)的重建攻击旨在通过用户上传的梯度重建用户的样本。当地差异隐私(LDP)被视为针对各种攻击的有效防御,包括在佛罗里达州的样本重建,在佛罗里达州,梯度被剪切和扰动。现有的攻击在LDP中在FL中无效,因为被剪切和扰动梯度抑制了大多数样本信息以进行重建。此外,现有的攻击还将其他样本信息嵌入到梯度中,以改善攻击效果并导致梯度扩展,从而导致使用LDP在FL中进行更严重的梯度剪辑。在本文中,我们提出了针对基于LDP的FL的样本重建攻击,任何目标模型都可以重建受害者的敏感样本,以说明使用LDP的FL并非完美无瑕。考虑了LDP重建攻击和噪声中的梯度扩展,提出的攻击的核心是梯度压缩和重建的Sample deNoisis。对于梯度压缩,提出了基于样本特征的推理结构,以减少针对LDP的冗余梯度。对于重建的样品denoising,我们人为地引入零梯度,以观察噪声分布和尺度置信区间以过滤噪声。理论证明保证了拟议攻击的有效性。评估表明,拟议的攻击是唯一在基于LDP的FL中重新结构受害者培训样本的攻击,并且对目标模型的准确性几乎没有影响。我们得出的结论是,基于自然党的FL需要进一步改进,以防御样本重建攻击。

受人类情感感知机制启发的情感导向预训练探索
深度卷积神经网络(DCNN)的预训练在视觉情绪分析(VSA)领域起着至关重要的作用。大多数提出的方法都采用在大型物体分类数据集(即 ImageNet)上预训练的现成的主干网络。虽然与随机初始化模型状态相比,它在很大程度上提高了性能,但我们认为,仅在 ImageNet 上进行预训练的 DCNN 可能过于注重识别物体,而未能提供情绪方面的高级概念。为了解决这个长期被忽视的问题,我们提出了一种基于人类视觉情绪感知(VSP)机制的面向情绪的预训练方法。具体而言,我们将 VSP 的过程分为三个步骤,即刺激接受、整体组织和高级感知。通过模仿每个 VSP 步骤,我们通过设计的情绪感知任务分别对三个模型进行预训练,以挖掘情绪区分的表示。此外,结合我们精心设计的多模型融合策略,从每个感知步骤中学习到的先验知识可以有效地转移到单个目标模型中,从而获得显着的性能提升。最后,我们通过大量实验验证了我们提出的方法的优越性,涵盖了从单标签学习(SLL)、多标签学习(MLL)到标签分布学习(LDL)的主流 VSA 任务。实验结果表明,我们提出的方法在这些下游任务中取得了一致的改进。我们的代码发布在 https://github.com/tinglyfeng/sentiment_pretraining 。

内部邪恶:通过休眠硬件Trojans的机器学习后门
摘要 - 后门对机器学习构成了严重威胁,因为它们会损害安全系统的完整性,例如自动驾驶汽车。虽然已经提出了不同的防御来解决这一威胁,但他们都依靠这样的假设:硬件加速器执行学习模型是信任的。本文挑战了这一假设,并研究了完全存在于这样的加速器中的后门攻击。在硬件之外,学习模型和软件都没有被操纵,以使当前的防御能力失败。作为硬件加速器上的内存有限,我们使用的最小后门仅通过几个模型参数偏离原始模型。为了安装后门,我们开发了一个硬件特洛伊木马,该木马会处于休眠状态,直到在现场部署后对其进行编程。可以使用最小的后门来配置特洛伊木马,并仅在处理目标模型时执行参数替换。我们通过将硬件特洛伊木马植入商用机器学习加速器中,并用最小的后门来证明攻击的可行性,以使其对交通符号识别系统进行编程。后门仅影响30个模型参数(0.069%),后门触发器覆盖了输入图像的6.25%,但是一旦输入包含后门触发器,它就可以可靠地操纵识别。我们的攻击仅将加速器的电路大小扩大了0.24%,并且不会增加运行时,几乎不可能进行检测。鉴于分布式硬件制造过程,我们的工作指出了机器学习中的新威胁,该威胁目前避免了安全机制。索引术语 - 硬件木马,机器学习后门。

机器人技术和自主系统
最近,机器学习(ML)已成为支持自我适应的流行方法。ML已被用来处理自我适应的几个问题,例如保持最新的运行时模型不确定性和可扩展的决策。然而,利用ML带来了固有的挑战。在本文中,我们关注基于学习的自适应系统的特别重要挑战:在适应空间中漂移。使用适应空间,我们参考了自适应系统可以根据适应选项的估计质量属性进行选择以适应的适应选项集。适应空间的漂移源自不确定性,影响适应性访问的质量特性。这样的漂移可能意味着系统的质量可能会恶化,最终,没有适应选项可以满足初始适应目标集,或者可能出现适应选项,从而可以增强适应性目标。在ML中,这种转变对应于一种新型的班级外观,在目标数据中的一种概念漂移,常见的ML技术会遇到问题。为了解决这个问题,我们提出了一种新型的自我适应方法,可以增强具有终身ML层的基于学习的自适应系统。我们将这种方法称为终身自我适应。终生的ML层跟踪系统及其环境,将这些知识与当前的学习任务相关联,根据差异确定新任务,并相应地介绍了自适应系统的学习模型。人类利益相关者可能会参与支持学习过程并调整学习和目标模型。我们提出了终身自我适应的一般体系结构,并将其应用于影响自我适应决策的适应空间的漂移情况。我们使用Deltaiot示例来验证一系列场景的方法。

AASD:通过在多模式大型语言模型中对准投机解码来加速推理
多模式大型语言模型(MLLM)在视觉教学调整中取得了显着的成功,但由于大型语言模型(LLM)骨干的自动回归解码,它们的推论既耗时又耗时。传统的加速推理方法,包括模型压缩和从语言模型加速的迁移,通常会损害输出质量或有效整合多模式特征的face Challenges。为了解决这些问题,我们提出了AASD,这是一个新型的框架,用于加速使用精制的KV缓存并在MLLM中对准投机解码。我们的方法利用目标模型的缓存键值(KV)对提取生成草稿令牌的重要信息,从而有效地投机解码。为了减少与长多模式令牌序列相关的计算负担,我们会引入KV投影仪,以压缩KV缓存,同时保持代表性保真度。此外,我们设计了一种目标放射线注意机制,以优化草稿和目标模型之间的对齐方式,从而以最小的计算开销来实现真实推理情景的好处。主流MLLM的广泛实验表明,我们的方法在不牺牲准确性的情况下达到了2倍推理的速度。这项研究不仅为加速MLLM推断提供了有效且轻巧的解决方案,而且还引入了一种新颖的对齐策略,用于在多模式背景下进行投机解码,从而为未来的有效MLLM研究奠定了强大的基础。代码可在https://anonymon.4open.science/r/asd-f571上使用。
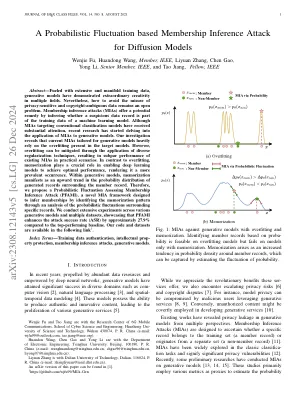
基于概率波动的会员推理攻击
摘要 - 富含广泛和流动的培训数据,生成模型在多个领域表现出了非凡的创造力。尽管如此,如何避免滥用对隐私敏感和版权的数据仍然是一个开放的问题。会员推理攻击(MIAS)通过推断可疑数据记录是机器学习模型的培训数据的一部分,从而提供了潜在的补救措施。尽管针对常规分类模型的MIA已引起了很大的关注,但最近的研究已开始研究MIA在生成模型中的应用。我们的研究表明,针对生成模型量身定制的当前MIA严重依赖于目标模型中存在的过度拟合。但是,可以通过应用各种正则化技术来缓解过度拟合,从而导致现有MIA在实际情况下的表现不佳。与过度拟合相比,记忆在使深度学习模型实现最佳性能中起着至关重要的作用,从而使其变得更加普遍。在生成模型中,记忆表现为围绕成员记录的记录的概率分布的上升趋势。因此,我们提出了一种评估成员推理攻击(PFAMI)的概率波动,这是一种新型的MIA框架,旨在通过分析围绕特定记录的概率波动来识别记忆模式来推断成员资格。我们的代码和数据集可在以下链接1中找到。我们对各种生成模型和多个数据集进行了广泛的实验,这表明PFAMI与表现最好的基线相比,PFAMI将攻击成功率(ASR)提高了约27.9%。

在行业5.0框架下推进农业食品供应链管理:边缘-AI方法
食物浪费与气候变化之间不断增长的联系导致欧洲委员会(EC)引入了行业5.0框架,旨在通过促进可持续,以人为中心和弹性的系统来实现可持续发展目标(SDG)。沿着这些路线,人工智能(AI)被认为是这种变化的蓝图,对农业食品行业具有巨大潜力。为了加速向行业5.0的转变,提出了一个边缘AI系统。该系统通过直观识别超市货架上的架子上可用性(OSA)索引及时捕获数据,监视哪些产品的高度或低需求对有效分布。为此,设计了一个双目标模型:1)确定检测到的农业食品架的类型,2)确定OSA是否已充分库存。编译了一个原始数据集,其中包含多达16,000个图像样本的这些目标。对于第一个,深度学习(DL)是通过合理的计算时间的自定义卷积神经网络(CNN)使用的,在识别八种产品方面达到了高达99.78%的测试准确性。使用残差网络(RESNET)的转移学习(TL)的测试准确性高达98.76%,以实现OSA检测。为了模糊不同的农业食品供应链(AFSC)促进器之间的线路,将开发网络平台以直观地表示这一实时信息。该平台将用作模拟“如果”方案的交互式决策工具。从整体的角度来看,这种方法有助于建立公平的粮食安全结构,同时保持环境责任满足行业5.0支柱。

优化数据获取以增强机器学习绩效
在本文中,我们研究了如何从大数据库中获取标记的数据点,以丰富增强监督机器学习(ML)性能的培训集。最新的解决方案是基于聚类的训练集选择(CTS)算法,该算法最初将数据点簇在数据库中,然后从集群中选择新的数据点。CTS的效率通过其频繁的目标ML模型进行了限制,并且该效率受到选择标准的限制,该标准代表了每个集群中数据点的状态,并施加了在每个迭代中仅选择一个群集的恢复。为了克服这些局限性,我们提出了一种新算法,称为CTS,具有自适应评分(IAS)的增量估计。ias采用了线路学习,通过使用新数据来实现增量模型更新,并消除了对目标模型进行充分重新培训的需求,从而提高了效率。为了提高IAS的有效性,我们引入了自适应得分估计,该评分估计是识别簇的新型选择标准,并通过平衡数据获取过程中的利用和探索之间的权衡取舍。为了进一步提高IAS的有效性,我们引入了一种新的自适应迷你批次选择方法,在每种迭代中,从多个群集中选择数据点,而不是单个群集,因此消除了仅使用一个群集而导致的潜在偏差。通过将此方法集成到IAS算法中,我们提出了一种新型算法,该算法称为IAS,具有自适应迷你批次选择(IAS-AMS)。实验结果突出了IAS-AM的卓越有效性,IAS也表现优于其他算法。在效率方面,IAS占据主导地位,而IAS-AMS的效率与现有CTS算法的效率相当。