XiaoMi-AI文件搜索系统
World File Search System过程描述

生成式人工智能作者指南
a. 作者应仅使用生成性 AI 技术来提高作品的可读性和语言,而不应用它来取代研究人员的任务,例如产生科学见解、分析和解释数据或得出科学结论。 b. 使用语言生成工具时,作者有责任审查和编辑生成的文本 c. 请注意,AI 工具从许多外部数据源中提取数据。作者有责任确保这些来源的准确性并给予适当的归属(即引用原始来源)。 d. 如果在写作中使用了 AI 工具,则需要披露和/或给予归属 4. 方法论:除了生成语言之外,作为正式研究设计或方法一部分的任何 AI 工具都需要在方法论部分中进行完整记录,并包括过程描述和模型或工具的名称、使用的版本和扩展号以及制造商。 5. 提交通知:在求职信、给编辑的说明或提交表格中注明使用了 AI 工具以及使用程度。 6. 关于无意中泄露受保护的健康信息(PHI)和知识产权(IP)的警告:用户输入生成 AI 工具的任何原始文本和/或其他数据都可能被平台所有者使用。
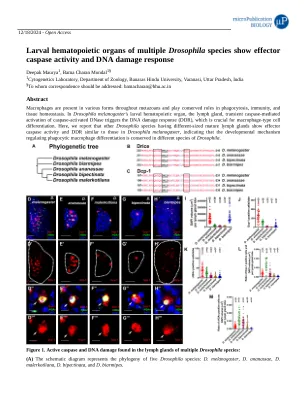
多种果蝇幼虫造血器官表现出效应胱天蛋白酶活性和DNA损伤反应
1882 年,埃利·梅契尼科夫 (Élie Metchnikoff) 在海星幼虫中发现了巨噬细胞,这种细胞通过吞噬外来物质来破坏外来物质。他将这一过程描述为吞噬作用 (Underhill 等人,2016)。后续研究表明,巨噬细胞在整个后生动物中都得到了保留,在调节发育、组织修复、体内平衡和先天免疫方面表现出额外的功能 (Lazarov 等人,2023;Park 等人,2022)。在三胚层动物中,吞噬细胞由于开放的循环系统而穿过体腔并清除细胞碎片或病原体 (Maheshwari,2022;Banerjee 等人,2019)。在哺乳动物中,常驻组织巨噬细胞在早期胚胎阶段从卵黄囊和红细胞-髓系前体细胞发育而来,并在整个生命过程中具有自我更新能力。单核细胞衍生的巨噬细胞也与快速补充的组织有关,例如肠道(Lazarov 等人,2023;Lee & Ginhoux,2022;Park 等人,2022)。在从单细胞生物进化到高度复杂的脊椎动物的过程中,巨噬细胞的作用和吞噬过程在很大程度上保持了下来(Yutin 等人,2009)。然而,吞噬巨噬细胞分化的潜在机制仍不清楚。

量子优势的博弈
我们提出了一种形式化方法,将向怀疑论者证明量子优越性的过程描述为由裁判监督的两个代理之间的互动游戏。该模型涵盖了目前存在的大多数量子优势验证技术。在这种形式化方法中,Bob 从量子设备上的分布中采样,该分布应该展示量子优势。然后,另一个玩家,即持怀疑态度的 Alice,被允许提出模拟分布,这些模拟分布应该可以重现 Bob 设备的统计数据。然后,Bob 需要提供见证函数来证明 Alice 提出的模拟分布无法正确近似他的设备。在这个框架内,我们建立了三个结果。首先,对于随机量子电路,Bob 能够有效地区分他的分布和 Alice 的分布意味着可以有效地近似模拟该分布。其次,找到一个多项式时间函数来区分随机电路的输出和均匀分布也可以在多项式时间内欺骗重度输出生成问题。这表明,在随机量子电路的设置中,即使是最基本的验证任务也可能无法避免指数资源。最后,通过采用强数据处理不等式,我们的框架使我们能够分析噪声对经典可模拟性和更一般的近期量子优势提案的验证的影响。

自旋压缩的 Gottesman-Kitaev-Preskill 代码用于......
GKP 码在连续变量 (CV) 量子系统的位移相空间梳中编码量子比特,可用于校正各种高权重光子误差。在这里,我们提出了单模 CV GKP 码的原子集合类似物,通过使用量子中心极限定理将 CV 系统的相空间结构拉回到量子自旋系统的紧凑相空间。我们使用分集组合方法计算通道保真度,研究了这些代码在由随机松弛和各向同性弹道失相过程描述的误差通道下的最佳恢复性能。我们发现自旋 GKP 码优于其他自旋系统代码,例如 cat 码或二项式码。我们的基于双轴反扭曲相互作用和 SU(2) 相干态叠加的自旋 GKP 码是有限能量 CV GKP 码的直接自旋类似物,而我们基于单轴扭曲的代码尚未有经过充分研究的 CV 类似物。提出了一种自旋 GKP 码的状态准备方案,该方案使用幺正方法的线性组合,适用于 CV 和自旋 GKP 设置。最后,我们讨论了用于自旋 GKP 编码量子比特的量子计算的容错近似门集,该门集是通过使用量子中心极限定理从 CV GKP 设置转换门而获得的。

JSAT 失去控制 - 商业航空安全团队
I. 执行摘要 3 ii. 结果与分析 11 A. 背景信息 11 B. 子团队的目的和组成 11 C. 分析数据集 12 D. 分析过程描述 13 E. 研究干预 16 III. 研究建议 18 A. 人为因素 19 B. 驾驶技能 19 C. 故障分析 20 D. 操作质量标准 20 IV. 与 PSM + ICR 报告比较 24 V. 建议 31 A. 设计问题干预 33 B. 培训干预 35 C. 实践、政策和程序干预 38 D. 数据干预 39 E. 监管角色干预 39 F. 建议摘要 40 VI.附录 43 附录 A. 失去控制 JSAT 章程 44 附录 B:团队成员名单 47 附录 C:数据集概要 52 附录 D:按总体有效性排序的干预措施 57 附录 E:研究与开发干预措施 88 附录 F:未评级干预措施 91 附录 G:按编号排序的干预措施 (IS#) 93 附录 H:按策略分组的干预措施 129 1. 设计干预策略 129 2. 培训干预策略 136 3. 实践、政策和程序干预策略 144 4. 数据干预策略 154 5. 监管角色干预策略 156 附录 I:主要问题陈述/干预矩阵 157 附录 J:问题陈述频率矩阵 219 附录 K:结冰239

基于RFACONV和TRIPLET的注意自主驾驶图像检测的优化
Yolov8由于其高速目标检测,精确的识别和定位以及多个平台的多功能兼容性,在自主驾驶领域中起着至关重要的作用。通过实时处理视频流或图像,yolov8迅速准确地确定了诸如车辆和行人在公路上的障碍,为自主驾驶系统提供了必要的视觉数据。此外,Yolov8支持各种任务,包括实例细分,图像分类和态度估计,从而为自主驾驶提供了全面的视觉感知,最终提高了驾驶安全性和效率。认识到对象检测在自主驾驶场景中的重要性以及现有方法所面临的挑战,本文提出了一种整体方法来增强Yolov8模型。该研究引入了两个关键修改:C2F_RFACONV模块和三重态注意机制。首先,在方法论部分中详细阐述了所提出的修改。C2F_RFACONV模块替换了原始模块以提高特征提取效率,而三重态注意机制则增强了功能焦点。随后,实验过程描述了培训和评估过程,涵盖了培训原始的Yolov8,整合了修改的模块以及使用指标和PR曲线评估性能改进。结果证明了修饰的功效,改进的Yolov8模型表现出显着的性能提高,包括增加的MAP值和PR曲线的改善。最后,“分析”部分阐明了结果并将其归因于引入的模块。C2F_RFACONV提高了特征提取效率,而三重态注意力提高了功能焦点,以增强目标检测。C2F_RFACONV提高了特征提取效率,而三重态注意力提高了功能焦点,以增强目标检测。

SRM 114q 认证:第二部分(粒度分布)
摘要 水泥细度标准参考材料 (SRM) SRM 114 是水泥行业常规用于鉴定水泥的校准材料的重要组成部分。水泥是一种粉末,在水化之前,其重要的物理特性是其表面积和粒度分布 (PSD)。自 1934 年以来,NIST 一直提供水泥细度 SRM 114,只要行业需要,它就会继续这样做。不同批次的 SRM 114 由 SRM 编号的唯一字母后缀指定,例如 114a、114b、...、114q。每一批材料都附有一份证书,该证书提供使用 ASTM C204 (Blaine)、C115 (Wagner) 和 C430 (45 μ m 筛余物) 获得的值。对于 SRM 114p,2003 年制定了一份附录,提供了 PSD 曲线。SRM 114p 的供应于 1994 年发布,并于 2004 年耗尽。因此,需要开发一批新的 SRM 114。该过程包括选择水泥、将水泥包装在小瓶中以及确定相关 ASTM 测试的值。在“SRM 114q 认证:第一部分”(SP26-161)中,讨论了 ASTM C204(Blaine)、C115(Wagner)和 C430(45 μ m 筛余物)测试值的开发。本报告介绍了 SRM 114q 的 PSD。本报告中的 PSD 测量基于光散射技术,或通常所说的激光衍射 (LD)。可以使用其他方法来开发水泥的 PSD,但经过两次循环赛和一次调查后,从其他方法获得的数据不足以对平均 PSD 进行统计有效计算。本报告的目的是补充第 I 部分中描述的认证 SRM 114q 的过程描述。用于开发 PSD 参考曲线的所有测量值均随统计分析一起提供。

有关光力量子传送的建议
量子传送的过程描述了未知输入状态到远程量子系统的传递。Bennett等人首先概述。[1],它已经演变成一个活跃的研究领域,现在被认为是许多量子方案的重要工具,例如量子中继器[2],基于测量的量子计算[3]和耐受性量子计算[4]。实验是第一个使用光子[5]实现的,后来又使用了各种系统,例如捕获的离子[6,7],原子集合[8],以及高频声音[9]和其他几个[10]。Over the past few years, optomechanical devices have emerged as an interesting tool to explore quantum phenomena, both from a fundamental perspective, showing the limits of quantum mechanical rules on massive objects [ 11 ], as well as from an applied view, promising to act as efficient transducers connecting radio-frequency regime qubits to low-loss opti- cal channels [ 12 , 13 ].已经提出了使用光力学系统的连续变量传送[14,15],但这种方案的实验实现仍然无法实现。在这里,我们提出了一项协议,该方案将实现基于脉冲制度中的分离变量的固定机械量子存储器上未知的光学输入状态的量子传送。该方案基于双轨编码,其中光子输入量子置值的极化状态被传送到两个机械模式上。当前最新的光学机械设备[16]应该能够实现所提出的协议。光学机械相互作用用作爱因斯坦 - 波多尔斯基 - 罗森河(EPR) - 型纠缠之间的源头,并在此范围内进行了验证,然后成功完成了输入量的成功铃声测量。可以按需读取磁场状态回到光学

人类计算机互动的深度学习
研究。数据集应代表各种用户和不同的上下文,以捕获各种变化。之后,我们需要准备数据并训练模型。训练将重复一百甚至一千次,以找到最合适的模型结构和超参数,这些模型结构和超级参数会导致使用试用和误差或网格搜索的测试集中最低模型误差。由于成千上万的迭代可能导致对测试集的过度拟合,因此必须使用先前看不见的数据评估模型的推广性,以评估所选模型和超参数是否已过拟合到验证集或推广到看不见的数据。深度学习社区在开发模型时通常会使用训练验证测试分解。在训练集和验证集用于迭代模型开发时,测试集用于一次性验证模型。但是,传统的机器学习评估指标(例如,准确性,精度,召回和错误率,以描述模型对看不见的数据的推广程度)并不描述系统的可用性。UCD过程的主要重点是实现高可用性。而不是软件指标,例如推理错误对可用性,模型稳定性和研究系统的有用性等因素。这可能涉及基本问题,例如对给定用例感知的可用性以及影响力的影响程度以及随着时间的推移估计的噪音多么嘈杂。在互动中应用深度学习技术由于系统使用了多种用户,在不同的情况下,验证还需要评估该模型是否可以推广到数据收集研究中使用的任务。虽然先前的工作认为准确性超过80%以至于足够[6],但充分性取决于用例,只能通过用户反馈来评估,例如,该动作的后果是否可恢复以及后果对用户的影响有多大。总而言之,一个深度学习的典型过程描述了开发和评估黑盒模型的迭代性质。但是,深度学习开发过程并未考虑模型的可用性以及最终系统的可用性。

六西格玛设计 - Gregory H. Watson
六西格玛设计 - 必然的诞生 六西格玛设计 (DFSS) 确实是一门不断发展的学科。DFSS 源于一项运营业务需求 - 需要将产品质量提升到 4.5 西格玛障碍之外,而这一障碍通常是由于产品的基础设计无法支持更高质量的性能而产生的。为了实现更高的质量水平,人们认识到,彻底重新思考设计 - 从而导致重新设计 - 是必不可少的。六西格玛的早期实践者清楚地认识到,统计问题解决过程(该过程通常称为 DMAIC - 一个缩写词,总结了定义、测量、分析、改进和控制的五个步骤)需要进行调整以服务于该产品开发的应用。此外,很明显,这种方法并不适合“一刀切”的过程描述。需要进行定制以适应商业环境、企业文化、法规遵从性要求、行业特定规范,并且 DFSS 需要集成到新产品开发或产品创建过程中,以用于非常不同的应用(例如,硬件、软件和服务的设计)。或许是迫切的业务需求和不明确的操作定义让六西格玛成为企业领导者的首要考虑因素,同时又让他们感到沮丧,因为顾问和学者支持社区中的思想领袖无法提供更好的指导。本书的目的 本书的目标是广泛的 - 它旨在为商业领袖建立 DFSS 的全面概述。本书寻求在平民主义书籍(最终只会起到鼓舞人心的作用)和详细教科书(针对实施者和工具用户,但会让读者沉迷于其细节)之间取得平衡。它还试图填补以前关于这个主题的书籍 1 中存在的空白,有目的地关注其目标客户,即需要了解 DFSS 主题的商业领袖,并提供连贯、全面的手稿来阐明 DFSS 概念,从而为有兴趣探索这些改进领域的组织指明方向。这本书的根源在于