XiaoMi-AI文件搜索系统
World File Search SystemAccurate

使用里德堡原子进行精确的量子模拟
本论文研究了使用里德堡原子的量子模拟。量子模拟的理念是使用一个可控性良好的量子系统来模拟另一个量子系统。量子模拟旨在前瞻性地解决经典计算机无法有效处理的具有挑战性的模拟问题,例如探索高度纠缠的多体基态和动力学。我们专注于所谓的模拟量子模拟,这种模拟量子模拟直接实现要模拟的系统,并避免通用门方法的开销。可实现系统的类别取决于底层平台的特性。一般来说,量子模拟平台必须可靠且可控性良好。此外,与退相干时间相比,相互作用必须很快。满足这些要求的平台例如超导量子比特和捕获离子。另一种方法是在光镊中使用中性原子。可以通过将原子激发到里德堡态(即具有高主量子数的电子态)并利用里德堡原子之间的强偶极相互作用来使原子相互作用。过去十年的快速发展使得使用这种方法模拟任意二维和三维晶格上的各种自旋哈密顿量成为可能,即使在超出精确数值处理的范围内也是如此。本论文涵盖的研究为量子模拟的实验实现提供了理论支持,为这一进展做出了贡献。本论文的重点有两个方面。首先,我们讨论了里德堡相互作用势的计算及其对实验参数的依赖性。其次,我们利用我们对里德堡相互作用的见解,展示了如何将精确的里德堡原子量子模拟应用于研究各种量子自旋模型。具体来说,我们展示了如何研究不同的拓扑相。后者是与巴黎的 Antoine Browaeys 实验小组密切合作进行的。在一个附带项目中,我们与格拉斯哥的 Andrew Daley 小组和 Gregory Bentsen 合作提出了一项用里德堡原子实现快速扰乱自旋模型的提案。下面,我们概述了本论文的章节。

准确解码想象和听到的旋律
音乐感知需要人脑处理各种声学和音乐相关特性。最近的研究使用编码模型来梳理和研究影响音乐感知的各种皮质因素。为此,这些方法研究了总结几分钟数据内神经活动的时间响应函数。在这里,我们测试了使用脑电图 (EEG) 评估单个音乐单元(小节)神经处理的可能性。我们设计了一种基于 EEG 段间最大相关性度量 (maxCorr) 的解码方法,并根据一项实验使用它来解码 EEG 中的旋律。在该实验中,专业音乐家多次聆听和想象四个巴赫旋律。我们在此证明,从聆听和想象期间记录的 EEG 信号中,可以准确解码单个受试者和单个音乐单元的旋律。此外,我们发现 maxCorr 方法的解码准确度高于基于后向时间响应函数 (bTRF env) 的包络重建方法。这些结果表明,低频神经信号编码的信息超出了音符时间,尤其是低于 1 Hz 的低频皮质信号,这些信号被证明可以编码与音高相关的信息。除了这些结果的理论意义外,我们还讨论了这种解码方法在新型脑机接口解决方案中的潜在应用。

GFET用于快速准确的传感解决方案
GFET-PV01是用于开发具有环氧封装层的传感应用的,从而可以在传感器修饰和测试过程中保持一致的液体处理和对齐。此外,将三个通道定位为启用每个石墨烯通道的可靠手动或自动化功能,以进行多重和/或内部参考。该设备与随时可用的数据采集系统兼容。

一种精确且快速校准的语音神经假体
作者的经济利益:Stavisky、Henderson 和 Willett 是斯坦福大学所拥有的知识产权的发明人,这些知识产权已授权给 Blackrock Neurotech 和 Neuralink Corp。Wairagkar、Stavisky 和 Brandman 拥有与加州大学校董会拥有的语音 BCI 相关的专利申请。Stavisky 是 wispr.ai 的顾问,并获得了股权。Brandman 是 Paradromics Inc. 的外科顾问。Henderson 是 Neuralink Corp 的顾问,在 Enspire DBS 的医学顾问委员会任职,也是 Maplight Therapeutics 的股东。MGH 转化研究中心与 Neuralink、Synchron、Axoft、Precision Neuro 和 Reach Neuro 签订了临床研究支持协议,LRH 为其提供咨询意见。麻省总医院 (MGB) 正在召集可植入脑机接口协作社区 (iBCI-CC);向 MGB 提供的慈善捐赠协议,包括迄今为止从 Paradromics、Synchron、Precision Neuro、Neuralink 和 Blackrock Neurotech 获得的捐赠,都支持 iBCI-CC,LRH 为其提供了帮助。Glasser 是 Sora Neuroscience、Manifest Technologies 和 Turing Medical 的顾问。

学习与可区分的精确模板匹配...
抽象模板匹配是计算机视觉中的一项基本任务,已经研究了数十年。它在制造业中起着至关重要的作用,可以估算不同部分的姿势,从而促进了下游任务,例如机器人抓握。当模板和源图像具有不同的方式,混乱背景或弱纹理时,现有方法失败。他们也很少考虑通过同谱进行几何变换,即使对于平面工业部位,它们通常也存在。为了应对挑战,我们提出了一种基于可不同的粗到功能对应关系的准确模板匹配方法。我们使用边缘感知模块来克服蒙版模板和灰度图像之间的域间隙,从而允许匹配。使用基于变形金刚提供的新结构感知信息的粗略对应关系来估算初始翘曲。使用参考图和对齐图像获得了用于获得最终几何变换的子像素级对应关系,将此初始对齐传递给了重新构造网络。广泛的评估表明,我们的方法比最先进的方法和基准要好得多,即使在看不见的真实数据上,也提供了良好的概括能力和视觉上可行的结果。

准确信息处理的非平衡成本
准确的信息处理在技术和自然界中都是至关重要的。为了实现它,任何信息处理系统都需要初始资源供应远离热平衡。在这里,我们建立了可以通过给定数量的非平衡资源来实现准确性的基本限制。该限制适用于任意信息处理任务和任意信息处理系统受量子力学定律的影响。它很容易计算,并且用熵数量表示,我们将其命名为反向熵,与所考虑的信息处理任务的时间逆转相关。对于所有确定性的经典计算及其所有量子延伸都可以达到极限。作为一种应用程序,我们建立了非quilibrium和准确性之间的最佳权衡,用于存储,传输,克隆和擦除信息的基本任务。我们的结果设定了接近最终效率限制的新设备设计的目标,并提供了一个框架,以证明量子设备的热力学优势比其经典配料。

精确建模对语音的反应
可以通过拟合将测量的脑信号(例如脑电图(EEG))与引起它们的刺激的3相关的刺激反应模型2探测感知过程。这些模型还发现了4个控制助听器等设备的控制。通过相关,分类或信息率指标测量的曲目质量指示了模型的值6和设备的实用性。基于规范7相关分析(CCA)的模型达到了超过8个常用线性向前和后向模型的质量拟合。在这里,我们表明9可以使用多种技术进一步提高他们的性能,包括10个自适应波束形成,CCA权重优化以及捕获数据中时间变化和上下文依赖性关系的复发性神经11网络12。我们使用Match-VS不匹配13分类范式证明了这些结果,其中分类器必须确定两个刺激14个ULUS样品中的哪个产生给定的EEG响应,哪些是随机选择的15个刺激样本。此任务捕获了更多其他研究中探讨的更符合16个PLEX听觉注意解码(AAD)任务的基本特征。17新技术的分类错误显着降低,信息传输率提高了18个,这表明这些模型更好地拟合了数据,而这些模型的感知过程反映了数据。这对于改善20个大脑计算机界面(BCI)应用很有用。21
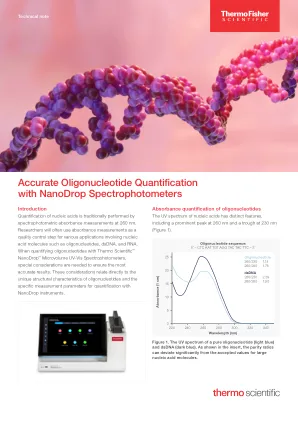
用纳米三核分光光度计
仅用于研究使用。不适用于诊断程序。有关当前认证,请访问thermofisher.com/certifications©2025 Thermo Fisher Scientific Inc.保留所有权利。除非另有说明,否则所有商标都是Thermo Fisher Scientific及其子公司的财产。mcs-tn1315-en 2/25

Avey:一种用于自我诊断的精确 AI 算法
医疗自我诊断算法(或症状检查器)正日益成为数字健康和我们日常生活中不可或缺的一部分。在本文中,我们介绍了基于人工智能 (AI) 的症状检查器 Avey。同时,我们提出了一种全面的实验方法,利用标准临床插图方法来评估症状检查器。基于此方法,我们编制并同行评审了迄今为止该领域最大的基准插图套件。之后,我们定义了七个准确度指标,并利用这个插图套件从不同角度评估 Avey 和其他五种流行症状检查器的性能。此外,我们将 Avey 的准确度与三名平均经验为 16.6 年的经验丰富的初级保健医生进行了比较。结果显示,Avey 的表现明显优于五种症状检查器,并且比医生的表现更佳。

Avey:一种用于自我诊断的精确人工智能算法
目标 介绍我们基于人工智能的症状检查器,严格测量其准确性,并将其与现有的流行症状检查器和经验丰富的初级保健医生进行比较。 设计案例研究。 设置 400 个黄金标准初级保健案例。 干预/比较器我们使用了 7 个标准准确性指标来评估 6 个症状检查器的性能。为此,我们开发并同行评审了 400 个案例,每个案例都得到了 7 名独立且经验丰富的全科医生中至少 5 名的认可。据我们所知,这产生了迄今为止该领域最大的基准案例套件。 为了建立参考框架并相应地解释症状检查器的结果,我们进一步将表现最佳的症状检查器与 3 名平均经验为 16.6 年的初级保健医生直接进行比较。主要结果测量我们从 7 个标准角度彻底研究了症状检查者和医生的诊断准确率,包括:(a) 𝑀 1、𝑀 3 和 𝑀 5 分别作为症状检查者或医生在前 3 种疾病中或前 5 种鉴别诊断疾病中返回小插图主要诊断的能力的测量指标;(b) 召回率作为症状检查者或医生鉴别诊断中返回的相关疾病百分比的测量指标;(c) 精确度作为症状检查者或医生鉴别诊断中相关疾病百分比的测量指标;(d) F1 测量作为召回率和精确度之间的权衡测量指标;(e) 归一化折现累积增益或 NDCG 作为症状检查者或医生鉴别诊断排名质量的测量指标诊断。结果 我们的基于 AI 的症状检查器 Avey 的表现明显优于 5 种流行的症状检查器,即 Ada、WebMD、K Health、Buoy 和 Babylon,使用 𝑀 1 时平均高出 24.5%、175.5%、142.8%、159.6%、2968.1%;使用 𝑀 3 时平均高出 22.4%、114.5%、123.8%、118.2%、3392%;使用 𝑀 5 时平均高出 18.1%、79.2%、116.8%、125%、3114.2%;使用召回率时平均高出 25.2%、65.6%、109.4%、154%、3545%;使用 F1 测量时分别为 8.7%、88.9%、66.4%、88.9%、2084%;使用 NDCG 时分别为 21.2%、93.4%、113.3%、136.4%、3091.6%。在精度方面,Ada 平均比 Avey 高出 0.9%,而 Avey 分别比 WebMD、K Health、Buoy 和 Babylon 高出 103.2%、40.9%、49.6% 和 1148.5%。与症状检查员相反,医生在使用精确度和 F1 测量时比 Avey 平均高出 37.1% 和 1.2%,而 Avey 在使用 𝑀 1、𝑀 3、𝑀 5、召回率和 NDCG 时分别比他们平均高出 10.2%、20.4%、23.4%、56.4% 和 25.1%。为了提高我们研究的可重复性并支持未来的相关研究,我们公开并免费提供了所有黄金标准小插图。此外,我们在网上发布了症状检查员和医生的所有结果(即 45 组