XiaoMi-AI文件搜索系统
World File Search SystemAdapt
用于处理逻辑相干交易类型的智能合约设计模式
摘要:最近的研究表明,智能合约的源代码通常是克隆的。区块链网络中相关类型的交易类型的处理导致实施许多类似的智能合约。因此,验证交易的规则被多次复制。本文介绍了Adapt V2.0智能合约设计模式。设计模式对每种事务类型采用独特的配置,并且在配置之间共享验证规则对象。在两个级别上消除了逻辑条件的冗余性。首先,可以将类似的智能合约组合到一个。其次,智能合约中的配置在运行时验证规则对象。结果,对于每个验证规则,只有一个对象是实例化的。它允许通过智能合约有效使用操作内存。本文使用面向对象和功能的编程机制介绍了该模式的实现。应用该模式可确保智能合约的自适应性在任何数量的交易类型上。在智能合约和不同数量的检查交易中,对各种验证规则进行了绩效测试。获得的10,000,000件交易的评估时间小于0.25 s。



通过运算符池平铺扩展自适应量子模拟算法
自适应变分量子模拟算法使用来自量子计算机的信息来动态创建给定问题汉密尔顿函数的最佳试验波函数。这些算法中的一个关键因素是预定义的运算符池,从中构建试验波函数。随着问题规模的增加,找到合适的池对于算法的效率至关重要。在这里,我们提出了一种称为运算符池平铺的技术,该技术有助于为任意大的问题实例构建问题定制的池。通过首先使用大型但计算效率低下的运算符池对较小问题实例执行自适应导数组装问题定制拟定变分量子特征求解器 (ADAPT-VQE) 计算,我们提取最相关的运算符并使用它们为更大的实例设计更高效的池。我们在这里对一维和二维的强相关量子自旋模型演示了该方法,发现 ADAPT 会自动为这些系统找到一个高效的拟定。鉴于许多问题(例如凝聚态物理学中出现的问题)具有自然重复的晶格结构,我们预计池平铺方法将成为一种适用于此类系统的广泛适用技术。

精神病患者意识障碍与大脑结构连接改变有关
1 巴黎大学医院集团精神病学和神经科学,大学医院部门大学医院中心巴黎 15,75014 巴黎,法国,2 巴黎萨克雷大学,CEA,Neurospin,F-91191,吉夫河畔伊维特,法国,3 认知神经科学研究所,伦敦大学学院,伦敦 WC1E 6BT,英国,4 成人精神病学系,Pitié Salpêtrière 大学医院,75013 巴黎,法国,5 AP-HP,H. Mondor 大学医院,DMU IMPACT,FHU ADAPT,F-94010,克雷泰伊,法国,6 神经科学中心,圣路易斯医院集团,Lariboisière Fernand Widal Assistance Publique-Hospitals of Paris,75010 巴黎,法国,7 巴斯德医学中心, 94550 Chevilly-Larue,法国,8 康塞普西翁大学工程学院,康塞普西翁 4070386,智利,9 巴黎东克雷泰伊大学,INSERM,IMRB,转化神经精神病学,FondaMental 基金会,F-94010,克雷泰伊,法国,10 法国学院,巴黎 75005,法国


标签代码
24174 ADAPT 100346 冒险音乐 77782 ANNIHILATION 48979 音频智能 22926 大屏幕 22925 BOOSTTV 49108 CLUBBINGZONE 33693 COUNTER 音乐 49109 DOCUZONE 27902 DRAMAZONE 13890 DRONEZONE 51442 EAR PARADE 音乐 92162 END OF SILENCE 52471 FLOAT 音乐库 22930 FUNZONE 97462 GEARBOX 50790 重旋律预告片 27924 重宣传片 50388 HISTORY ZONE 15691 灵感制作音乐 15742 LIFTMUSIC 27903 LIFTMUSIC WILDCARDS 29066 LIFTMUSIC FLAVA 29246 LIFTMUSIC FACTUAL 27101 MINDS AND MUSIC 101917 N-TRAX 25396 ONETRACKADAY 102129 OUTBREAK 18481 PENNYBANK TUNES 48979 PITCH HAMMER 57553 PLANET SYNC 22929 PLAYGROUND HOLLYWOOD 49110 PLEASUREZONE 14582 POINT CLASSICS 24348 POKE MUSIC 22927 PP MUSIC 49116 PROFILES 99204 RECORD COLLECTOR 84851 ROGUE SOULS 50792 SILVER SCREEN 89167 故事记录 28965 超市 50791 第三轨 49107 电视区 48979 UPPER CUT 48979 VANGUARD 95560 世界区 48979 YOUR SILENT FACADE 22928 ZONE PLUS 51541 区域拖车

单元2-第2部分影响孩子发育的因素
•尖叫。•发脾气。•踢。•咬人。•回归。•提取。•固执。如果他们具有良好的自我概念,则更有可能具有弹性,并且会受到过渡的影响,因为它们将更能够适应新的情况。韧性是适应新情况并从艰难的经历中反弹的能力。案例研究1-斯嘉丽

模块 1:人工智能简介...
本学习模块采用 Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International BY-NC-SA 4.0 许可证,该许可证要求重复使用者注明创作者。它允许重复使用者以任何媒介或格式分发、重新混合、改编和基于该材料进行创作,但仅限于非商业用途。如果其他人修改或改编该材料,他们必须根据相同的条款对修改后的材料进行许可。4
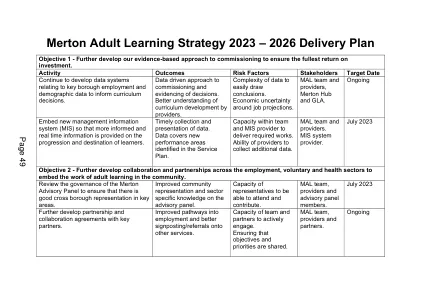
默顿成人学习策略2023 - 2026交货计划
提供商适应市场变化的能力。就业机会。目标5-调整课程以满足雇主的未来劳动力需求,并将更多的居民纳入良好的工作,包括绿色经济的技能。活动结果风险因素利益相关者目标日期增加与关键雇主的参与,以帮助将其劳动力需求满足课程开发。