XiaoMi-AI文件搜索系统
World File Search SystemDetect


RSA NetWitness 检测 AI
RSA NetWitness Detect AI 将高级分析和机器学习应用于 RSA NetWitness 平台捕获的数据,以提供可操作的威胁检测来应对新兴和复杂的攻击。该解决方案的优点有四个方面:它立即开始工作以识别可疑行为;机器学习算法不需要手动调整;并且由于它是 SaaS,因此对硬件和持续管理的要求极低,并且可以扩展以满足您组织的需求和用例。

通过头脑风暴检测脑部疾病
Rishabh Srivastava 1、Siddhant Singh 2、Ujjawal Yadav 3 印度 Galgotias 工程技术学院计算机科学与工程系 摘要:脑部疾病是全球面临的重大且日益严重的健康挑战,涵盖从阿尔茨海默病和帕金森病等神经退行性疾病到各种神经精神疾病等一系列疾病。及时准确地发现脑部疾病对于及时干预、制定适当的治疗方法和改善患者的整体生活质量至关重要。本研究论文探讨了一种创新的跨学科方法,通过整合头脑风暴技术和先进的机器学习算法来增强脑部疾病检测过程。该研究深入探讨了头脑风暴技术在脑部疾病检测中的适应性和有效性,利用了临床记录、遗传信息和患者病史等各种数据源。该研究介绍了各种头脑风暴技术,用于分析、识别和得出可用于检测脑部疾病的最佳方法。关键词:头脑风暴、帕金森、 SWOT、思维导图、星爆。

检测大肠菌群的新标准
1.00850Chromocult®Coliform琼脂ES用于食品和动物饲料中大肠菌菌和大肠杆菌的检测。e是提高选择性的,因为食品基质中的预期细菌背景菌群较高,例如生碎牛肉,生碎鸡肉和生牛奶(经AOAC验证)。44657 ECD杯琼脂此大肠杆菌直接琼脂中的胆汁盐混合物广泛抑制伴随植物群的非渗透性肠道。荧光底物杯子的裂解和阳性测试证明了大肠杆菌的存在。1.10620Fluorocult®LMX肉汤,用于通过发色和荧光过程同时检测水,食物和乳制品中大肠菌细菌和大肠杆菌。81938 Hicrome™大肠菌琼脂推荐用于同时检测水和食物样品中的大肠杆菌和总大肠菌群。发色混合物含有两个发色底物,鲑鱼 - 盐和X-葡萄糖苷。大肠菌群产生的酶β-D-半乳糖苷酶裂解了鲑鱼,从而导致鲑鱼变成大肠菌群的红色。大肠杆菌裂解X-葡萄糖醛酸的酶β-D-葡萄糖醛酸苷酶(深蓝色至紫色的菌落与两种活性结合使用)。70722 Hicrome™大肠杆菌琼脂B hicrome E. Coli琼脂B用于食品中大肠杆菌的检测和枚举,而无需在膜过滤器上或通过吲哚试剂进行进一步确认。大多数大肠杆菌菌株可以通过存在高度特异性大肠杆菌的酶葡萄糖醛酸酶来区分其他大肠菌菌。大肠杆菌细胞吸收X-葡萄糖醛酸酯,细胞内葡萄糖醛酸酶分裂发色团和葡萄糖醛酸苷之间的键。释放的发色团给出了菌落的蓝色。73009 Hicrome™ECC琼脂Hicrome ECC琼脂是一种差异培养基,用于推定大肠杆菌和其他大肠菌群中的食品和环境样品中的其他大肠菌群。发色混合物包含两个染色体,作为X-葡萄糖醛酸和鲑鱼 - 盐。X-葡萄糖醛酸是由大肠杆菌产生的酶β-葡萄糖醛酸酶裂解的。鲑鱼 - 盐 - 由大多数大肠菌群(包括大肠杆菌)产生的酶半乳糖苷酶裂解。大肠杆菌菌落的颜色:蓝色/紫色85927 Hicrome™ECC选择性琼脂hicrome ecc选择性琼脂是一种选择性(tergitol作为抑制剂)培养基,建议同时检测水和食品样品中的大肠杆菌和大肠杆菌。成分甚至有助于共同受伤的大肠菌群迅速生长。发色混合物包含两个发色底物,作为鲑鱼 - 果胶和X-glucuronide。大肠菌群产生的酶β-D-半乳糖苷酶裂解了鲑鱼,从而导致鲑鱼变成大肠菌群的红色。大肠杆菌裂解X-葡萄糖醛酸酶产生的酶β-D-葡萄糖醛酸苷酶。大肠杆菌由于鲑鱼和X-glucuronide的裂解而形成了深蓝色至紫色的有色菌落。
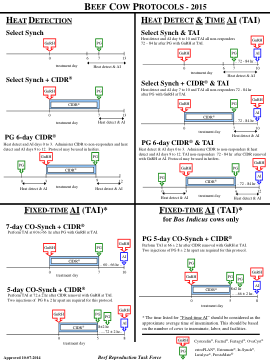
发情检测与时间人工智能 (TAI)
发情检测和人工授精第 0 至 3 天。对无反应母牛施用 CIDR,并在发情检测和人工授精第 9 至 12 天施用。对 TAI 无反应母牛在移除 CIDR 后 72 - 84 小时在人工授精时使用 GnRH。此方案可用于小母牛。
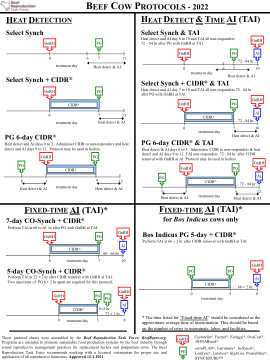
热检测和时间 AI (TAI)
这些协议表由牛肉繁殖工作组 (BeefRepro.org) 汇编而成。这些计划旨在通过合理的繁殖管理实践促进牛肉行业的可持续食品生产系统,供后备母牛和产后母牛使用。牛肉繁殖工作组建议与有执照的兽医合作,以正确使用和应用所有生殖激素。已批准 2021 年 12 月 1 日。

检测工业中异常的三层方法...
摘要 — 本文介绍了一种基于物联网 (IoT) 网络和机器学习算法设计定制解决方案以检测不同工业应用中的罕见事件的通用方法。我们提出了一个基于三层(物理、数据和决策)的通用框架,该框架定义了可能的设计选项,以便可以超可靠地检测到罕见事件/异常。然后将这个通用框架应用于一个众所周知的基准场景,即田纳西伊士曼过程。然后,我们在与数据处理相关的三个线程下分析这个基准:采集、融合和分析。我们的数值结果表明:(i)事件驱动的数据采集可以显著减少样本数量,同时过滤测量噪声,(ii)互信息数据融合方法可以显著减少变量空间,(iii)用于数据分析的定量关联规则挖掘方法对于罕见事件的检测、识别和诊断是有效的。这些结果表明,集成解决方案的优势在于,该解决方案根据所提出的一般三层框架共同考虑了不同级别的数据处理,包括要采用的通信网络和计算平台的细节。

深度检测 - 新闻资料包
DEEPDETECT 项目旨在训练人工智能,以提高检测和识别光学和红外图像中极小物体的任务。这些图像中的内容种类繁多,甚至人类也很难检测到非常小的物体。因此,目的是评估这些技术以协助决策。当然,无论是在民用还是军用环境中,这都必须快速而高效,以避免任何错误。

Greenwatch-shing:利用人工智能检测漂绿行为
虚假新闻的兴起导致人们对某一问题的科学理解的关注度与来自科学界以外的误导性、有时是故意误导性的言论(故意传播以欺骗人们的虚假信息)之间存在巨大差异。气候变化就是一个例子,一项自然研究表明,尽管科学界对人类活动引起的气候变化的重要性达成了压倒性共识,但反对气候变化的人士在媒体文章中出现的频率比科学家高出 49%。此外,全球许多公司对其环境和社会绩效做出不准确且往往具有误导性的声明,这反过来又导致了漂绿行为的广泛传播。

检测癫痫发作的量子网络
背景:机器学习 (ML) 为科学家开发有效的计算机辅助诊断 (CAD) 系统铺平了道路。近年来,使用脑电图 (EEG) 数据和深度学习模型进行癫痫发作检测引起了广泛关注。然而,在深度学习网络中,瓶颈是大量可学习的参数。方法:在本研究中,提出了一种新方法,包括用于特征提取的 1D 卷积神经网络 (CNN) 模型,然后是用于分类的经典量子混合层。所提出的技术只有 745 个学习参数,这是迄今为止报道的最少的。结果:所提出的方法在 Bonn EEG 数据集上的二元分类中实现了 100% 的最大准确度、灵敏度和特异性。此外,还检查了所提出模型的噪声鲁棒性。据作者所知,这是第一项使用量子机器学习 (QML) 检测癫痫发作的研究。结论:因此,开发的混合系统将帮助神经科医生以在线模式检测癫痫发作。