XiaoMi-AI文件搜索系统
World File Search SystemGLM

非数字数据的定量分析
摘要:本研究说明了使用关联规则常规分析系统(ARGA)用于分析非数字数据的使用。Parente,Finley和Megalis(2021)的先前研究表明,如何使用Argas方法在常规实验设计中测试假设。本研究说明了如何在探索性研究环境中使用ARGA,例如单盘研究,在多试验学习实验中评估组织,对社交媒体的分析以及针对个人的病例研究。这种分析方法在措施单位是单词,形状或其他形式的非数字数据的研究环境中是适当的。关键字:Argas,GLM,假设产生,关联规则,单个案例研究,社交媒体和面向病例的定性研究。

TractLearn:用于脑束定量分析的测地线学习框架
基于深度学习的卷积神经网络最近已证明其能够基于弥散加权成像快速分割主要脑束结构。脑束的定量分析则依赖于来自纤维束成像过程本身或束上每个体素的指标。在疾病的背景下,对异常体素的统计检测通常依赖于单变量和多变量统计模型,例如一般线性模型 (GLM)。然而,在高维低样本量数据的情况下,尽管通常使用平滑过程,但由于解剖学差异,GLM 通常意味着对照的标准差范围较大。这可能导致难以在体素尺度上检测到脑束中细微的定量变化。在这里,我们介绍了 TractLearn,这是一个使用测地线学习作为数据驱动学习任务的脑束定量分析统一框架。 TractLearn 允许使用黎曼方法在图像高维域和脑束的减少潜在空间之间进行映射。我们通过重测采集多壳扩散 MRI 数据说明了该方法对健康人群的稳健性,表明可以分别研究不同 MRI 会话导致的整体影响和局部束改变的影响。然后,我们在 5 名年龄匹配的轻度脑外伤受试者样本上测试了我们算法的效率。我们的贡献是提出:1/ 一种捕捉控制变异性的流形方法作为标准参考,而不是基于欧几里得均值的图谱方法。2/ 一种检测体素定量值整体变化的工具,它考虑了结构中体素的相互作用,而不是独立分析体素。3/ 一种即用型算法,用于突出显示扩散 MRI 指标的非线性变化。在这方面,TractLearn 是一个可立即使用的精准医疗算法。

用大语言模型自定义社交角色
基于角色的对话(字符)在行业中已经变得至关重要(例如,字符),使用户能够自由自定义社交互动。但是,在社交角色中固有的各种对话方案中的普遍性和适应性仍然缺乏公共的工业解决方案。通过解剖由固有的社会概况和外部社会行为组成的全面的社交角色,我们手动收集具有不同类别和行为的特征的大规模中国语料库,并与精心设计的改进方法一起开发特征模型。广泛的实验表明,特征glm形成了最流行的开放式和封闭源LLM,并且与GPT-4相当。我们发布了本地开发和部署的数据和模型:https://github.com/thu-coai/targinglm-6b。1

基于机器学习的库欣病内镜鼻内入路治疗结果预测:未来即将到来?
缩写 ACTH = 促肾上腺皮质激素;AUC = 曲线下面积;CD = 库欣病;CS = 海绵窦;DI = 尿崩症;EEA = 内镜经鼻入路;GBM = 梯度增强机;GLM = 广义线性模型;GTR = 大体肿瘤切除术;IPSS = 下岩窦取样;KNN = k-最近邻;ML = 机器学习;NPV = 阴性预测值;PAS = 过碘酸希夫;PPV = 阳性预测值;RF = 随机森林;ROC = 受试者工作特征;SF-1 = 类固醇生成因子-1;SVM = 支持向量机。随附编者按 DOI:10.3171/2020.3.FOCUS20213。提交于 2020 年 1 月 31 日。接受于 2020 年 3 月 4 日。引用时请包含 DOI:10.3171/2020.3.FOCUS2060。 * MZ 和 VES 对这项工作的贡献相同,并共同为第一作者。

精算周期中的机器学习
A B R I G H T F U T U T U T U R E在本文中提出了一个框架,该框架通过在策略级别上建模所有索赔阶段以及更有效地使用数据来连接精算周期。机器学习扩大了技术的调色板,并且并不总是它过去的黑框,因为新技术在准确性和透明度之间的权衡模糊了。我们的用例表明,可以使用机器学习来提供更好的传统方法(例如GLM模型),作为独立模型(例如估算忍者储量)或与其他技术结合(例如用于大型索赔建模)。使用这一小型用例,我们已经显示了精算师使用机器学习技术在整个精算周期中增加价值的丰富机会,以创造这个工作领域的光明未来。■


机器学习驱动的糖蛋白质组学分析标识了新型糖尿病相关的糖基化生物标志物
糖基化在包括糖尿病在内的蛋白质功能和疾病进展中起着至关重要的作用。这项研究进行了全面的糖蛋白分析,比较了健康的志愿者(HV)和DM样品,并鉴定出19,374肽和2,113种蛋白质,其中11104种是糖基化的。总共将287种不同的聚糖映射到3,722个糖基化的肽,揭示了HV和DM样品之间糖基化模式的显着差异。统计分析确定了29个显着改变糖基化位点,在DM中上调了23个,在DM中下调了6个。值得注意的是,在DM中,在Prosaposin的位置215处的Glycan HexNAC(2)Hex(2)FUC(1)在DM中显着上调,标志着其首次报道的与糖尿病的关联。机器学习模型,尤其是支持向量机(SVM)和广义线性模型(GLM),在基于糖基化特征(Glycans,糖基化蛋白质和糖基化位点)区分HV和DM样品时,可以在区分HV和DM样品时获得高分类精度(〜92%:96%)。这些发现表明,改变的糖基化模式可能是糖尿病相关病理生理和治疗靶向的潜在生物标志物。
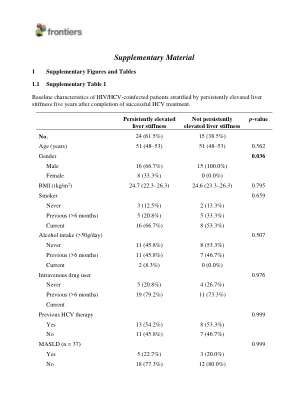
补充材料 - repisalud
统计:数据是通过具有伽马分布(LOG-LINK)的广义线性模型(GLM)计算的。多变量模型按年龄,性别,HCV治疗(基于IFN的治疗或DAAS),在治疗后一年进行LSM调整,并且在两次之间经过的时间,以前是通过逐步方法(前进)选择的(请参阅结果部分)。Q值代表使用错误发现率(FDR; Benjamini和Hochberg程序)进行多次测试校正的p值。统计上的显着差异以粗体显示。缩写:AMR,算术平均比例; AAMR,调整后的AMR; 95%CI,95%的置信区间; P,意义水平; q,校正的意义水平; BTLA,B和T淋巴细胞衰减剂; CD,分化簇; GITR,糖皮质激素诱导的TNFR相关; HVEM,疱疹病毒入学调解人; IDO,吲哚胺2,3-二氧酶; lag-3,淋巴细胞激活基因-3; PD-1,程序性细胞死亡蛋白1; PD-L1,编程的死亡配体1; PD-L2,编程死亡配体2; TIM-3,T细胞免疫球蛋白和含有3的粘蛋白膜。

利用共享神经模式解码自然视频的动态情感反应
本研究探索了使用短暂情感事件(观看情感图片)中的共享神经模式来解码自然体验(观看电影预告片)中的扩展动态情感序列的可行性。28 名参与者观看了国际情感图片系统 (IAPS) 中的图片,并在单独的环节中观看了各种电影预告片。我们首先通过 GLM 分析定位双侧枕叶皮层 (LOC) 对情感图片类别有反应的体素,然后根据他们在观看电影预告片时的反应对 LOC 体素进行受试者间超对齐。超对齐后,我们在情感图片上训练受试者间机器学习分类器,并使用这些分类器解码样本外参与者在图片观看和电影预告片观看期间的情感状态。在参与者中,神经分类器识别图片的效价和唤醒类别,并跟踪观看视频期间自我报告的效价和唤醒。总体而言,神经分类器生成效价和唤醒时间序列,跟踪从单独样本获得的电影预告片的动态评级。我们的发现进一步支持了使用预先训练的神经表征来解码自然体验期间的动态情感反应的可能性。

二进制反馈
安全是将重新执行学习(RL)应用于实际问题的必不可少的要求。尽管近年来提出了大量的安全RL算法,但大多数现有工作通常1)依赖于收到Nu-ereric Safety Affect的反馈; 2)不能保证在学习过程中的安全; 3)将问题限制为先验已知的确定性过渡动力学;和/或4)假设对任何州的已知安全政策都具有关注。解决上述问题时,我们提出了长期的二进制反馈安全RL(LOBISARL),这是一种具有二进制安全反馈和未知的随机状态过渡功能的马尔可夫决策过程(CMDP)的安全RL算法。lobisarl优化了一项政策,以最大程度地提高奖励,同时保证代理商在每个情节中仅执行安全的州行动对,并以很高的可能性执行安全的州行动对。具体来说,Lobisarl通过广义线性模型(GLM)对二进制安全函数进行建模,并且在每个时间步骤中仅采取安全措施,同时在适当的假设下对未来的安全产生影响。我们的理论结果表明,Lobisarl具有很高的可能性,可以保证长期的安全限制。最后,我们的经验结果表明,我们的算法比现有方法更安全,而没有显着损害奖励方面的表现。