XiaoMi-AI文件搜索系统
World File Search SystemLanguage


人工智能在英语外语教学中的探索
摘要:本研究旨在根据所发现的实验研究结果,分析目前在大学层面用于外语教学和英语作为应用语言学习的技术。该方法汇编了 PRISMA 系统评价和荟萃分析标准。实验研究的结果表明,缺乏创新技术,例如聊天机器人或虚拟现实 (VR) 设备,这些技术通常用于外语 (FL) 教育。此外,移动应用程序主要关注外语词汇的习得。研究结果表明,外语教师可能了解最新的技术设备,例如神经机器翻译,但他们并没有在教学过程中准确地将它们结合起来。因此,本研究表明,教师应该接受教育,并知道如何在外语课程和传统教学中使用它们,以确定哪些技能或语言结构可以通过使用它们而产生。此外,建议必须进行进一步的实验研究,以阐明证据以及它在将外语作为适用语言进行教学方面有多大用处。



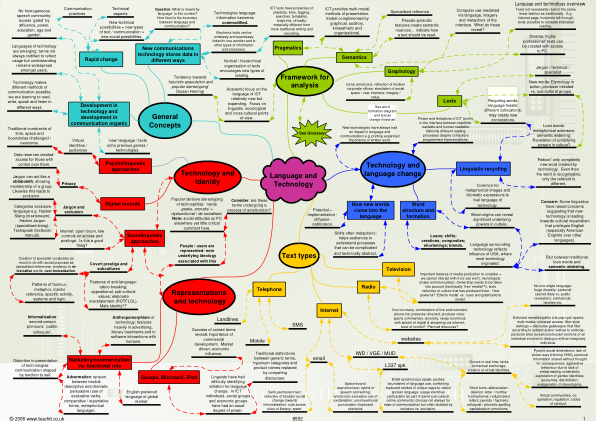
语言与技术通用...
需要考虑的媒体制作的重要特征 = 我们无法与其互动(或者我们可以吗?);独白(大众传播);需要考虑所有权(技术上“免费”媒体?);文本反映了产生它们的文化。有多强大?“效果模式”与“使用和满足模式”。

语言发展基础
在这些卷本的最后准备阶段,埃里克·伦内伯格于 1975 年 5 月 31 日在纽约州怀特普莱恩斯突然去世。他是一个有着无限好奇心的人,他的理论和综合能力在语言、大脑和行为研究中无与伦比。虽然他以在人类语言生物学基础上的开创性工作而闻名,但他最终关注的是心智和大脑的研究,这也是他去世前正在研究的问题。他在 50 年代末首次提出,人类的语言能力只能基于人类大脑和声道的生物学特性来解释,这一观点后来被广泛接受和阐述。他的实验和观点被总结在 1967 年出版的开创性著作《语言的生物学基础》中。Eric Lenneberg 于 1921 年 9 月 19 日出生于德国,并在那里度过了生命的前十二年。1933 年,他随父母移民到巴西。为了寻求更广泛的教育经验,他于 1945 年来到美国。在美国陆军服役一年后,他于 1947 年进入芝加哥大学,于 1949 年获得文学士学位,并于 1951 年获得文学硕士学位。他获得了博士学位。 1955 年,他获得哈佛大学心理学和语言学双学位,随后在哈佛医学院获得医学科学博士后奖学金,进一步专攻神经病学和儿童发育障碍。1959 年至 1967 年,他在哈佛大学和马萨诸塞州任教

Maude 战略语言
重写逻辑是并发系统和逻辑规范的自然且富有表现力的框架。Maude 规范语言提供了这种形式主义的实现,允许执行、验证和分析所表示的系统。这些规范通过术语和方程式声明其对象,并提供重写规则来表示状态上可能不确定的局部转换。有时需要对这些规则进行受控应用,以减少非确定性,捕捉全局、面向目标或效率问题,或选择特定的执行进行分析。这就是我们所说的策略。为了表达它们,尊重关注点分离原则,提出并开发了 Maude 策略语言。策略语言的首次实现是在 Maude 本身中使用其反射功能完成的。经过充分的实验,又添加了一些功能,为了提高效率,策略语言已在 C++ 中实现为 Maude 系统的一个组成部分。本文介绍了 Maude 策略语言及其语义、实施决策以及来自各个领域的几个应用示例。

ALS426:语言和语言学
本课程是对语言和语言学研究的介绍。它向学生介绍了语言和语言学的基本概念,原则和理论。它提供了一些背景信息,有关语言的起源,动物和人类语言之间的差异,语言获取/学习和语言学重要,其中包括语音,语音学,形态学,语法,语义,语义,语用学。它还教会学生根据电影/报告/纪录片分析某些语言问题,并撰写有关与语言有关的问题的项目论文。

语音和语言处理
i NLP 1 1简介的基本算法。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。3 2正则表达式,令牌化,编辑距离。。。。。。。。。。。。。。。4 3 n克语言模型。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。32 4天真的贝叶斯,文本分类和情感。。。。。。。。。。。。。。。。。56 5逻辑回归。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。77 6矢量语义和嵌入。。。。。。。。。。。。。。。。。。。。。。。。。。。。。101 7神经网络。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。132 8 RNN和LSTMS。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。158 9变压器。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。184 10大语言模型。。。。。。。。。。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>203 11蒙版语言模型。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>223 12模型对齐,提示和内在学习。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>242 div>