XiaoMi-AI文件搜索系统
World File Search SystemRobo

人工智能:赌博的基础技术
法律界。机器学习算法和自然处理语言已经在国外用于协助法院作出判决。据称,IBM 的 Ross 等应用程序可以惊人地准确回答用户提出的法律问题,甚至提供引文和进一步阅读的建议。美国一家律师事务所最近也宣布,他们正在使用 IBM 的人工智能 Ross 来处理他们的破产业务 1 。一些法律未来学家,如 Benjamin Alarie,他预测人工智能将带来法律奇点(一个假设的点,计算智能和决策能力超过人类律师、法官和其他决策者),借用 Vernor Vinge 的“奇点”一词,他认为人工智能将通过政府、律师、公司的算法系统之间的自动交互过程取代现有的法律制度,并在此过程中解决所有法律困境 2 。未来生命研究所联合创始人、物理学家马克斯·泰格马克 (Max Tegmark) 对此表示:“由于法律程序可以抽象地看作是计算,输入有关证据和法律的信息并输出判决,因此一些学者梦想通过机器人法官实现法律程序的完全自动化;人工智能系统会孜孜不倦地将相同的高法律标准应用于每一项判决,而不会屈服于偏见、疲劳或缺乏最新知识等人为错误。3”尽管最近取得了进展

Stas Tiomkin 博士
SP22-FL23 主题:' 利用动态系统特性的无模型跟踪 ' SP22-FL23 主题:' 通过机器学习方法改善高速公路交通 ' SP22-FL23 主题:' 机械臂形态的优化 ' SP22-FL23 主题:' 用于无监督学习的信息理论和物理量 ' SP22-FL23 主题:' 通过稀疏输入和输出控制高维动力学 ' SP22-FL23 主题:' 机器人 - 训练师 ' FL22-SP23 主题:' 基于模型的几何先验强化学习 ' FL22-SP23 主题:' 滚石乐队通过自学下围棋 ' FL22-SP23 主题:' 通过动态系统进行潜在因子分析的研究 ' SP23-FL23 主题:' 用于自主网络物理平台的可扩展多服务架构 ' FL22-SP23主题:' 通过强化学习开发自主网络物理系统 ' FL22-SP23 主题:' 通过强化学习方法提高智能汽车刹车的安全性 ' FL22-SP23 主题:' 交通网络分散控制的信息论方法 ' FL22-SP23 主题:' 声学超材料设计的强化学习方法 ' SP23-FL23 主题:' 用于人工智能研究的大型网络物理平台 ' SP23-FL23 主题:' 使用信息论方法进行无监督学习 ' FL23-SP24 主题:' 用于 RoboCup 足球比赛的多智能体强化学习 ' FL23-SP24 主题:' 网络物理系统中的实时数据处理和机器学习 ' FL23-SP24 主题:' 自然环境中的宠物分类 ' FL23-SP24 主题:' 使用嵌入式设备实时监测和分析空气质量 '

stza常见问题解答
Q6:谁可以用作区域企业? In order for a Zone Enterprise to be eligible for a license, Zone Enterprises should preferably be engaged in the following categories ( ZE Categories ) R&D, operations, development, financing, and investment in Artificial Intelligence and Machine Learning, Big Data Analytics, Quantum Computing, Cloud Computing, Internet of Things (IoT), Robo Advisory, Distributed Ledger Technology (DLT), Natural Language Pro- cessing (NLP), Augmented Reality / Virtual Reality (AR / VR), Robotics, Wearables, Mobile Payment, Fintech and Block chain, Biotech and Genomics, Edtech, Science and or Technology Institution, Technol- ogy Skill Development Centers, Telemedicine, Biomedical Technology, Internet of Things (IoT), 3D-Print- ing, Electric Vehicles, Automobiles, Sustainable and Renewable Energy, Green Energy, Agri-Tech, Con-传递技术,ICT,IT和ITE,纳米技术,医疗设备,药品,创意工业。 ed技术,半导体,电子商务,卫星,电子产品,智能手机和笔记本电脑,精美的化学品,新材料,精确仪器,环境技术,第三级工业,其他主要的S&T工业领域,工业,工业和工业以及其他现有的现有和即将到来的数字和即将到来的数字和技术领域,并获得了批准的,并获得了时间的批准,并在时间上批准了时间,并在时间上定位了时间。 Zone Enterprises的业务不是核心技术(即,不是来自上面提到的ZE类别之一),并且是技术业务的辅助或提供一般商业服务(例如酒店,餐厅,餐厅,邮政服务等。>Q6:谁可以用作区域企业?In order for a Zone Enterprise to be eligible for a license, Zone Enterprises should preferably be engaged in the following categories ( ZE Categories ) R&D, operations, development, financing, and investment in Artificial Intelligence and Machine Learning, Big Data Analytics, Quantum Computing, Cloud Computing, Internet of Things (IoT), Robo Advisory, Distributed Ledger Technology (DLT), Natural Language Pro- cessing (NLP), Augmented Reality / Virtual Reality (AR / VR), Robotics, Wearables, Mobile Payment, Fintech and Block chain, Biotech and Genomics, Edtech, Science and or Technology Institution, Technol- ogy Skill Development Centers, Telemedicine, Biomedical Technology, Internet of Things (IoT), 3D-Print- ing, Electric Vehicles, Automobiles, Sustainable and Renewable Energy, Green Energy, Agri-Tech, Con-传递技术,ICT,IT和ITE,纳米技术,医疗设备,药品,创意工业。ed技术,半导体,电子商务,卫星,电子产品,智能手机和笔记本电脑,精美的化学品,新材料,精确仪器,环境技术,第三级工业,其他主要的S&T工业领域,工业,工业和工业以及其他现有的现有和即将到来的数字和即将到来的数字和技术领域,并获得了批准的,并获得了时间的批准,并在时间上批准了时间,并在时间上定位了时间。Zone Enterprises的业务不是核心技术(即,不是来自上面提到的ZE类别之一),并且是技术业务的辅助或提供一般商业服务(例如酒店,餐厅,餐厅,邮政服务等。),也可以适用于在不同STZ的一般服务开放申请时,在STZ中经营其业务。在为一般服务申请开放之前,潜在申请人可以向applications@stza.gov.pk发送一封利益信。

生物技术(BE27)课程 技术选修课(TE)
• BENG 102 – 生命系统的分子成分(4 个单元中只有 2 个单元可计入工程学) • BENG 110 – 生物力学基础 • BENG 112A – 组织生物力学 • BENG 112B – 流体和细胞生物力学 • BENG 133 – 数值分析和计算工程 • BENG 134 – 测量、统计和概率 • BENG 140A – 生物工程生理学(4 个单元中只有 2 个单元可计入工程学) • BENG 140B – 生物工程生理学(4 个单元中只有 2 个单元可计入工程学) • BENG 141 – 生物医学光学和成像 • BENG 172 – 生物工程实验室 • BENG 186B – 生物仪器设计原理 • BENG 193 – 临床生物工程 • BENG 196 – 生物工程工业实习 • BENG 199(2 个季度与同一教员一起上课) • CENG 100 – 材料和能量平衡 • CENG/NANO 134 – 聚合物材料 • CENG 199(2 个季度与同一教员一起上课) • CSE 100 – 高级数据结构 • CSE 101 – 算法设计与分析 • CSE 112 – 高级软件工程 • CSE 140/140L – 数字系统/实验室的组件和设计技术 • CSE 150A – 人工智能简介:概率推理和决策 • CSE 150B – 人工智能简介:搜索和推理 • CSE 151A – 机器学习简介 • CSE 151B – 深度学习 • CSE 166 – 图像处理 • CSE 176A – 医疗机器人 • CSE 180 – 生物学与计算机的结合

月球矿石保留标准(101)
这项工作介绍了月球储量标准的当前开发(LORS101)。这些标准旨在为月球资源探险家,矿工,投资者以及对月球资源(Mineral and volales)QuanɵɵEs的任何相关方提供一致的指南,对月球资源项目的评估,并报告全面的分类框架中的结果。LORS-101分类框架考虑地质不确定性,项目和技术成熟度,以及社会上的框架,以及社会上的框架和Lors-Cal和Lors-101,还包括SRU或原位资源的词汇表或现场资源uɵlisaɵon(ISRU),这是对月球,Mars和其他机构的使用,或者在Sere中使用的,或者在Sere中使用的是,也可以在Sere和其他机构中使用,并在Sere中使用,该系统是在Sere中使用的。目前在石油和天然气和采矿业中使用的定义。SRU技术将为人类提供进一步探索的空间,而对于所有SRU技术阶段都是必不可少的。关键挑战之一是SRU的独特跨学科性质;它集成了空间系统,机器人,材料处理和益处,以及化学过程工程。这是对月球或行星地质学的知识所支持的,包括矿物学,物理特征和当地材料的可变性。以一种协调的方式将如此多样化的领域结合起来,需要使用一个通用框架,该框架将使歌剧进行整合和技术的比较,并将定义全球术语在所有领域中使用。在sruacɵviɵes之前需要解决的重要项目之一是Esɵmaɵon和公共记录的标准的范围;空间探索结果,空间资源评估和空间储备。

吉大港独立大学(CIU)
吉大港独立大学(CIU)的科学与工程学院(SSE)成立于2013年。今天,这所学校仍然是CIU的主要学校之一,旨在培养世界一流的工程毕业生。除了计算机科学与工程(CSE),电气和电子工程(EEE)和电子与电信工程(ETE)计划外,SSE还增加了一项研究生文凭(PGD)信息和通信技术(ICT)。所有这些计划都遵循UGC批准的教学大纲和课程。仅考虑当前学校的教师学生比例为1:14。吉塔贡工程技术大学(CUET),吉大港大学(CU)(CU)(CU)和Di Erent组织的工程专业人士的兼职能力将在需要时。为了满足学生的质量和能力,我们定期安排研讨会和讲习班,一个星期或一个月的培训计划,例如Android应用程序开发,机器人技术,可编程逻辑控制器(PLC)和工业自动化,高级编程,AL和第五工业革命,可再生和可持续的能源开发等此外,SSE还安排了各种竞争计划,例如国家高中节目竞赛(NHSPC),Inter Schools&College编程竞赛,高中和大学教师编程的研讨会,CIU Tech Fest,CIU-SSE Robo竞赛,SSE文化之夜等。我们也表明了我们对地方社会的承诺。每月的教师研讨会启发了学者和学生。为与学生,毕业生和专业人士提供全球网络的机会,这些机会有助于在课堂外建立关键技能,SSE推出了Central Student Club(ISEC),SSE编程俱乐部,机器人俱乐部,IEEE学生分支机构,CIU等。IEEE学生会是SSE唯一一个将CIU列入世界最大技术学会地图的专业和国际学生组织。

2020-1102 NEP SIP CEPF FINS.PDF
•宣布协议在约1 ggawatt的可再生能源投资组合中获得40%的权益,并在100兆瓦的太阳能储存项目中获得100%的利息•达成共识10年,约111亿美元可转换的股票投资组合融资,其中包括获得的Nextera Enlienter Protient and Soler Partners的PROTCHTERS&SOL PROTCTING•有效的Partenters的份额•有意义的份额•交易后融资能力高达约24亿美元,这进一步支持了伙伴关系的长期增长•介绍了年预期的2021年运行率调整后的EBITDA和现金可用于分配期望,反映了与同等2020年期终年期间的10%和7%的增长,分别在弗洛拉(Juno Beach),fla。与Nextera Energy Resources,LLC的子公司达成的协议,以在约1,000兆瓦(MW)可再生能源投资组合中获得40%的权益,并在100兆瓦的太阳能储存项目中获得100%的利息。收购后,Nextera Energy Partners将在获得的项目中为新投资组合贡献利益和四个现有的可再生能源资产。结合了新投资组合的收购和创建,Nextera Energy Partners已与私人基础设施投资者财团一起融入了约11亿美元的可兑换股权投资组合融资。“今天宣布的交易展示了Nextera Energy Partners的持续能力执行其长期增长计划并继续获得有吸引力的低成本资本来源,”董事长兼首席执行官Jim Robo说。“收购高质量的长期合同可再生能源资产,包括合伙企业的第一个电池存储项目,进一步增强了合伙企业现有投资组合的多样性。通过伙伴关系历史上的日期最长,最低的可转换股权投资组合融资将这一收购与四个现有的Nextera Energy Partners资产重新资本相结合,预计将为Unithiteer提供重大利益。通过与私人基础设施投资者合作,Nextera Energy Partners希望进一步加强其资产负债表,并在交易后获得约24亿美元的资本,以支持未来的增长。这种对低成本资本的重要机会使Nextera Energy Partners独特地定位,以利用重塑能量的破坏性因素

参考书目 - Elgaronline
Abraham, Kenneth S. ‘个人行为与集体责任:大规模侵权行为改革的困境’ (1987) 73 Va L Rev 845。Allen, Hilary A. ‘监管沙盒’ (2019) 87 Geo Wash L Rev 579。Bainbridge, Stephen M. ‘为什么要有董事会?公司治理中的集体决策’ (2002) 55 Vand L Rev 1。Baker, Steven D. ‘Rachal v. Reitz 和信托中强制仲裁条款的效力和实施’ (2017) 9 Est Plan & Cmty Prop LJ 191。Baker, Tom 和 Benedict Dellaert。 “监管金融服务行业的机器人咨询”(2018) 103 Iowa L Rev 713。Bakhtiari, Ryan K.、Katrina Boice 和 Jeffrey S. Majors。“现在是统一受托责任的时候了”(2013) 87 St John’s L Rev 313。Bant, Elise。“误导行为和决策因果关系案件中的决策因果关系路线图”(2020) 157 Precedent 4。Bant, Elise。“不当得利的因果关系和责任范围”(2009) 17 RLR 60。Bant, Elise 和 Jeannie M. Paterson。“消费者救济立法:简化还是颠覆合同法”(2017) 80 MLR 895。Bant, Elise 和 Jeannie M. Paterson。 “误导行为案件中的法定因果关系:普通法的经验教训”(2017 年)24 TLJ 1. Barnett, Katy。“公平补偿和疏远:毕竟与普通法并没有那么遥远”(2014 年)38 UWAL Rev 48. Barnett, Katy。“合同中的减轻和疏远:政策和原则”(2019 年)36 JCL 5. Barnett, Katy。“合同法中的替代性损害赔偿和减轻”(2016 年)
参考书目 - Elgaronline
Abraham, Kenneth S.《个人行为与集体责任:大规模侵权行为改革的困境》 (1987) 73 Va L Rev 845。Allen, Hilary A.《监管沙盒》 (2019) 87 Geo Wash L Rev 579。Bainbridge, Stephen M.《为什么要有董事会?公司治理中的集体决策》 (2002) 55 Vand L Rev 1。Baker, Steven D.《Rachal v. Reitz 和信托中强制仲裁条款的效力和实施》 (2017) 9 Est Plan & Cmty Prop LJ 191。Baker, Tom 和 Benedict Dellaert。 《金融服务行业机器人咨询监管》(2018 年)103 Iowa L Rev 713。Bakhtiari、Ryan K.、Katrina Boice 和 Jeffrey S. Majors。《现在是统一受托责任的时候了》(2013 年)87 St John's L Rev 313。Bant, Elise。《误导行为和决策因果关系案件中的决策因果关系路线图》(2020 年)157 Precedent 4。Bant, Elise。《不当得利的因果关系和责任范围》(2009 年)17 RLR 60。Bant, Elise 和 Jeannie M. Paterson。《消费者救济立法:简化还是颠覆合同法》(2017 年)80 MLR 895。Bant, Elise 和 Jeannie M. Paterson。 “误导行为案件中的法定因果关系:普通法的教训”(2017) 24 TLJ 1. Barnett, Katy。“公平补偿与疏远:毕竟与普通法并无太大差别”(2014) 38 UWAL Rev 48. Barnett, Katy。“合同中的减轻和疏远:政策和原则”(2019) 36 JCL 5. Barnett, Katy。“合同法中的替代性损害赔偿和减轻” (2016) 28 SAcLJ 795。Bar-Gill, Oren 和 Elizabeth Warren。 《让信贷更安全》(2008)157 U Pa L Rev 1。Baxter,Lawrence G。《联邦银行监管中的受托人问题》(1993)56(1)LCP 7。Beale,Hugh。《英国合同法中合同文件的首要地位》[2019] IWRZ(国际经济法杂志)28。Ben-Shahar,Omri 和 Carl E. Schneider。《强制披露的失败》(2011)159 U Pa L Rev 647。Berryman,Jeff。《基于事实的受托人违约的公平赔偿:关于澄清补救目标的初步想法》(1999)37 Alta L Rev 95。Black,Barbara 和 Jill I. Gross。 《边做边学:法律在证券仲裁中的作用》 (2002) 23 Cardozo L Rev 991。Black, Julia。《对监管的批判性思考》 (2002) 27 Austl J Leg Phil 1。Bollen, Rhys。《金融服务与产品的质量与安全》 (2015) 26 JBFLP 182。Booysen, Sandra。《新加坡二十年(及以上)对不公平合同条款的控制》 [2016] Sing JLS 219。Boxx, Karen E.《论细节与回报:统一信托法典下的忠诚义务》 (2002) 67 Mo L Rev 279。Boz, Emine 和 Enrique G. Mendoza。 《金融创新、风险的发现和美国信贷危机》 (2014) 62 J Monetary Economics 1. Braithwaite, Jo.《合同禁止反言的起源和含义》 (2016) 132 LQR 120. Brunet, Edward.“质疑替代性争议解决方式的质量” (1987-8),62 Tul L Rev 1。
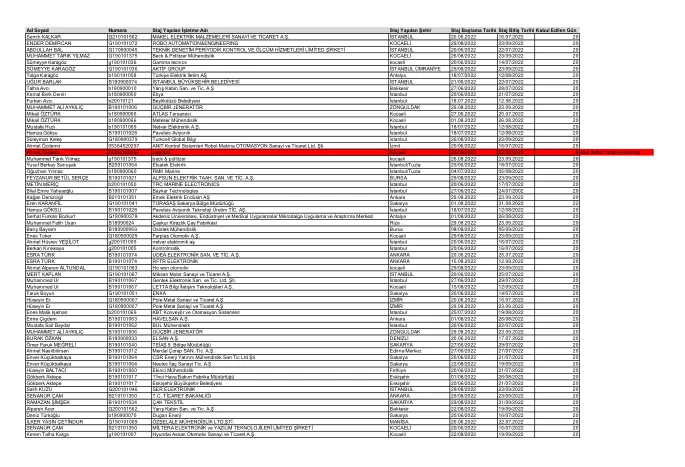
实习所在企业的名称
名字 姓氏 号码 实习公司名称 实习城市 实习开始日期 实习结束日期 接受日期 Semih KALKAR G210101562 MAKEL ELECTRICAL MATERIALS INDUSTRY AND TRADE INC.伊斯坦布尔 2022 年 6 月 20 日 2022 年 7 月 16 日 20 ENDER DEMİRCAN G190101072 ROBO AUTOMATION&ENGINEERING 科贾埃利 2022 年 8 月 29 日 2022 年 9 月 23 日 20 ABDULLAH BAL G170900045 技术检查定期控制和测量服务有限公司 伊斯坦布尔 2022 年 6 月 20 日 2022 年 7 月 22 日 20 MUHAMMET TARIK YILMAZ G190101375 Beck & Pollitzer Engineering 科贾埃利 2022 年 8 月 26 日 2022 年 9 月 23 日 20 Sümeyye Karagöz g190101036 Gamma tecnıcs 科贾埃利20/06/2022 14/07/2022 20 SÜMEYYE KARAGÖZ G190101036 ACTIVE GROUP ISTANBUL ÜMRANİYE 29/08/2022 23/09/2022 20 Tolga Karagöz b190101058 土耳其电力输送公司 安塔利亚 18/07/2022 12/08/2022 20 UĞUR BARLAK B180900074 伊斯坦布尔大都会市 伊斯坦布尔 21/06/2022 22/07/2022 20 Talha Avcı b180900010 Yarış Kabin San.和贸易。 A.Ş 巴勒克埃西尔 27/06/2022 28/07/2022 20 Kemal Berk Demir b180900050 Etiya 伊斯坦布尔 20/06/2022 21/07/2022 20 Furkan Avcı b20010121 贝伊利克杜祖市 伊斯坦布尔 18.07.2022 12.08.2022 20 MUHAMMET ALİ AYKILIÇ B190101006 GUCBIR 发电机 ZONGULDAK 29.08.2022 23.09.2022 20 Mikail OZTURK b180900066 ATLAS 船厂科贾埃利 27.06.2022 25.07.2022 20 Mikail OZTURK b180900066 Meteser Engineering Kocaeli 01.08.2022 26.08.2022 20 Mustafa Hızlı b190101069 Netvar Elektronik A.Ş.伊斯坦布尔 2022 年 7 月 18 日 2022 年 8 月 12 日 20 Hamza Göksu B190101028 Pavelsis Avionics 伊斯坦布尔 2022 年 7 月 18 日 2022 年 8 月 12 日 20 Süleyman Keleş G180900379 Turkcell Global Bilgi 伊斯坦布尔 2022 年 8 月 26 日 2022 年 9 月 23 日 20 Ahmet Özdemir 05364520297 ANIT 控制系统机器人机械自动化工贸有限公司斯蒂。 İzmit 20/06/2022 16/07/2022 20 Ahmet Özdemir 05364520297 Legrand Kocaeli 29/08/2022 23/09/2022 0 实习书上传错误。 Muhammet Tarık Yılmaz g190101375 beck & pollitzer kocaeli 08/26/2022 09/23/2022 20 Yusuf Berkay Sarıuşak B200101064 Elsatek Elektrik İstanbul/Tuzla 06/20/2022 07/18/2022 20 Oğuzhan Yılmaz b180900060 RMK Marine İstanbul/Tuzla 07/04/2022 08/05/2022 20 FEYZANUR BETUL SERÇE B190101021 ALPSUN ELECTRICAL CONTRACTING.歌唱。和贸易。作为。 BURSA 29/08/2022 23/09/2022 20METïnMeríçB200101050TRC Marine Electronicsİstanbul20/06/2022 17/07/2022 20 Bilal Emre Yahyao 210101351 EMEK Electric Industry Inc. Ankara 29.08.2022 23.09.2022 20 ErenKaranfïlG1901010101041TurasaşSakaryasakarya Regionate Sakarya Sakarya 01.08.08.2022航空电子技术生产贸易有限公司公司。伊斯坦布尔 2022 年 7 月 18 日 2022 年 8 月 12 日 20 Serhat Furkan Bozkurt G180900378 Akdeniz 大学,工业和医学应用微波应用与研究中心 安塔利亚 2022 年 8 月 1 日 2022 年 8 月 26 日 20 Muhammet Fatih Uyan B18090024 Çaykur Kirazlık 茶厂 里泽 2022 年 8 月 29 日 2022 年 9 月 23 日 20 巴里什 Bayram B180900069 Osistek Engineering 布尔萨 2022 年 8 月 8 日 2022 年 9 月 5 日 20 Enes Toker G180900029 Farplas Automotive A.Ş.科贾埃利 (Kocaeli) 29/08/2022 23/09/2022 20 Ahmet Hüsrev YEŞİLOT g200101009 netvar Elektronik AŞ 伊斯坦布尔 20/06/2022 16/07/2022 20 Berkan Kırıkkaya g200101005 控制仪伊斯坦布尔 20/06/2022 16/07/2022 20 ESRA TÜRK B190101074 UDEA ELECTRONICS SAN。和贸易。作为。安卡拉 20.06.2022 25.07.2022 20 ESRA TÜRK B190101074 RFTR ELECTRONICS 安卡拉 15.08.2022 12.09.2022 20 Ahmet Alperen ALTUNDAL G190101063 Ho won automobile kocaeli 29/08/2022 23/09/2022 20 MERT KAPLAN G190101067 Miksan Motor Industry and Trade Inc.伊斯坦布尔 20/06/2022 25/07/2022 20 Muhammed Ur B190101067 Gentek Elektronik San.和贸易。有限公司斯蒂。伊斯坦布尔 2022 年 6 月 27 日 2022 年 7 月 29 日 20 Muhammed Ur B190101067 LETTA 信息通信技术公司科贾埃利省 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Faruk Boyun G190101051 ENKA Sakarya 2022 年 6 月 20 日 2022 年 7 月 14 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 6 月 20 日 2022 年 7 月 16 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN作为。安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 202022 20 ESRA TÜRK B190101074 RFTR ELECTRONICS 安卡拉 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Ahmet Alperen ALTUNDAL G190101063 Ho won automobile kocaeli 2022 年 8 月 29 日 2022 年 9 月 23 日 20 MERT KAPLAN G190101067 Miksan Motor Industry and Trade Inc.伊斯坦布尔 20/06/2022 25/07/2022 20 Muhammed Ur B190101067 Gentek Elektronik San.和贸易。有限公司斯蒂。伊斯坦布尔 2022 年 6 月 27 日 2022 年 7 月 29 日 20 Muhammed Ur B190101067 LETTA 信息通信技术公司科贾埃利省 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Faruk Boyun G190101051 ENKA Sakarya 2022 年 6 月 20 日 2022 年 7 月 14 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 6 月 20 日 2022 年 7 月 16 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN作为。安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 202022 20 ESRA TÜRK B190101074 RFTR ELECTRONICS 安卡拉 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Ahmet Alperen ALTUNDAL G190101063 Ho won automobile kocaeli 2022 年 8 月 29 日 2022 年 9 月 23 日 20 MERT KAPLAN G190101067 Miksan Motor Industry and Trade Inc.伊斯坦布尔 20/06/2022 25/07/2022 20 Muhammed Ur B190101067 Gentek Elektronik San.和贸易。有限公司斯蒂。伊斯坦布尔 2022 年 6 月 27 日 2022 年 7 月 29 日 20 Muhammed Ur B190101067 LETTA 信息通信技术公司科贾埃利省 2022 年 8 月 15 日 2022 年 9 月 12 日 20 Faruk Boyun G190101051 ENKA Sakarya 2022 年 6 月 20 日 2022 年 7 月 14 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 6 月 20 日 2022 年 7 月 16 日 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN作为。安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 202022 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统 伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN Inc.安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 202022 20 Hüseyin Er G180900007 Pole Metal Industry and Trade Inc. 伊兹密尔 2022 年 8 月 29 日 2022 年 9 月 23 日 20 Enes Malik Işıkhan b200101069 KBT 输送机和自动化系统 伊斯坦布尔 2022 年 7 月 25 日 2022 年 8 月 19 日 20 Emre Çigdem B190101063 HAVELSAN Inc.安卡拉 01/08/2022 26/08/2022 20 Mustafa Sait Baydar B190101062 BUL 工程 伊斯坦布尔 20/06/2022 22/07/2022 20 MUHAMMET ALI AYKILIÇ B190101006 GUCBIR 发电机 宗古尔达克 29.08.2022 23.09.2022 20 BURAK ÖZKAN B180900033 ELSAN A.Ş. DENIZLI 20.06.2022 17.07.2022 20 Omer Faruk MEGRELI B190101040 TEIAS 第 5 地区局 SAKARYA 27/06/2022 29/07/2022 20 Ahmet HowYouKnow B190101012 Merdal Çorap SAN。贸易。作为。埃迪尔内/中心 2022 年 6 月 27 日 2022 年 7 月 27 日 20 Enver Küçükbalkaya B190101064 CSR 能源投资工程 San Tic Ltd Sti Sakarya 2022 年 6 月 20 日 2022 年 7 月 21 日 20 Enver Küçükbalkaya B190101064 Neutec 制药工业贸易。 A.S Sakarya 22/08/2022 2022 20HüseyinBaltaciB190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20GökberkAktepe aktepe aktepe aktepe b1901010101717 Aktepe B190101017EskişehirMetropolitan城市Eskişehir20/06/2022 21/07/2022 20 Salih Kuzu G2001010101046 Ser Electronics Istanbul 29/08/2022 23/09/2022 23/2022 23/23/2022 20 Senanurur B210111111111111350土耳其共和国贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 20Ş Sakarya 22/08/2022 19/09/2022 20 Hüseyin BALTACI B190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20 Gökberk Aktepe B190101017 1st Air Maintenance Factory Directorate Eskişehir 01/08/2022 26/08/2022 20 Gökberk Aktepe B190101017 Eskişehir Metropolitan Municipality Eskişehir 20/06/2022 21/07/2022 20 Salih KUZU G200101046 SER ELECTRONICS ISTANBUL 29/08/2022 23/09/2022 20 SENANUR ÇAM B210101350 TC贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 20Ş Sakarya 22/08/2022 19/09/2022 20 Hüseyin BALTACI B190101060 Ekinci Engineering Fethiye 20/06/2022 21/07/2022 20 Gökberk Aktepe B190101017 1st Air Maintenance Factory Directorate Eskişehir 01/08/2022 26/08/2022 20 Gökberk Aktepe B190101017 Eskişehir Metropolitan Municipality Eskişehir 20/06/2022 21/07/2022 20 Salih KUZU G200101046 SER ELECTRONICS ISTANBUL 29/08/2022 23/09/2022 20 SENANUR ÇAM B210101350 TC贸易部 安卡拉 29/08/2022 23/09/2022 20 RAMAZAN ŞİMŞEK B190101034 ÇAK TEXTILE 萨卡里亚 29/08/2022 21/09/2022 20 Alperen Acer G200101562 亚里斯 卡宾圣。和贸易。 A.Ş Balıkesir 2022 年 8 月 22 日 2022 年 9 月 19 日 20 Deniz Türkoğlu b180900070 Dugan Energy Sakarya 2022 年 6 月 20 日 2022 年 7 月 16 日 20 İLKER YASİN ÇETİNDUR G190101009 ÖZŞELALE ENGINEERING LTD.INC.马尼萨 20.06.2022 22.07.2022 20 SENANUR ÇAM B210101350 MİLTERA ELECTRONICS and SOFTWARE TECHNOLOGIES LIMITED COMPANY 科贾埃利 20/06/2022 16/07/2022 20 Kerem Talha Karga g190101007 现代阿桑汽车工贸公司科贾埃利 2022 年 8 月 22 日 2022 年 9 月 19 日 20